 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMSTER: Hierarchical Action Models For Open-World Robot Manipulation
Feb 08, 2025



Large foundation models have shown strong open-world generalization to complex problems in vision and language, but similar levels of generalization have yet to be achieved in robotics. One fundamental challenge is the lack of robotic data, which are typically obtained through expensive on-robot operation. A promising remedy is to leverage cheaper, off-domain data such as action-free videos, hand-drawn sketches or simulation data. In this work, we posit that hierarchical vision-language-action (VLA) models can be more effective in utilizing off-domain data than standard monolithic VLA models that directly finetune vision-language models (VLMs) to predict actions. In particular, we study a class of hierarchical VLA models, where the high-level VLM is finetuned to produce a coarse 2D path indicating the desired robot end-effector trajectory given an RGB image and a task description. The intermediate 2D path prediction is then served as guidance to the low-level, 3D-aware control policy capable of precise manipulation. Doing so alleviates the high-level VLM from fine-grained action prediction, while reducing the low-level policy's burden on complex task-level reasoning. We show that, with the hierarchical design, the high-level VLM can transfer across significant domain gaps between the off-domain finetuning data and real-robot testing scenarios, including differences on embodiments, dynamics, visual appearances and task semantics, etc. In the real-robot experiments, we observe an average of 20% improvement in success rate across seven different axes of generalization over OpenVLA, representing a 50% relative gain. Visual results are provided at: https://hamster-robot.github.io/
Differentiable GPU-Parallelized Task and Motion Planning
Nov 18, 2024


We present a differentiable optimization-based framework for Task and Motion Planning (TAMP) that is massively parallelizable on GPUs, enabling thousands of sampled seeds to be optimized simultaneously. Existing sampling-based approaches inherently disconnect the parameters by generating samples for each independently and combining them through composition and rejection, while optimization-based methods struggle with highly non-convex constraints and local optima. Our method treats TAMP constraint satisfaction as optimizing a batch of particles, each representing an assignment to a plan skeleton's continuous parameters. We represent the plan skeleton's constraints using differentiable cost functions, enabling us to compute the gradient of each particle and update it toward satisfying solutions. Our use of GPU parallelism better covers the parameter space through scale, increasing the likelihood of finding the global optima by exploring multiple basins through global sampling. We demonstrate that our algorithm can effectively solve a highly constrained Tetris packing problem using a Franka arm in simulation and deploy our planner on a real robot arm. Website: https://williamshen-nz.github.io/gpu-tamp
Discovering Robotic Interaction Modes with Discrete Representation Learning
Oct 26, 2024
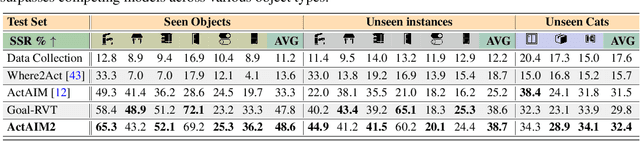
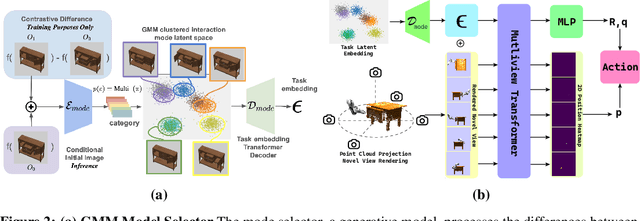

Human actions manipulating articulated objects, such as opening and closing a drawer, can be categorized into multiple modalities we define as interaction modes. Traditional robot learning approaches lack discrete representations of these modes, which are crucial for empirical sampling and grounding. In this paper, we present ActAIM2, which learns a discrete representation of robot manipulation interaction modes in a purely unsupervised fashion, without the use of expert labels or simulator-based privileged information. Utilizing novel data collection methods involving simulator rollouts, ActAIM2 consists of an interaction mode selector and a low-level action predictor. The selector generates discrete representations of potential interaction modes with self-supervision, while the predictor outputs corresponding action trajectories. Our method is validated through its success rate in manipulating articulated objects and its robustness in sampling meaningful actions from the discrete representation. Extensive experiments demonstrate ActAIM2's effectiveness in enhancing manipulability and generalizability over baselines and ablation studies. For videos and additional results, see our website: https://actaim2.github.io/.
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Jun 26, 2024



Recent works have shown that visual pretraining on egocentric datasets using masked autoencoders (MAE) can improve generalization for downstream robotics tasks. However, these approaches pretrain only on 2D images, while many robotics applications require 3D scene understanding. In this work, we propose 3D-MVP, a novel approach for 3D multi-view pretraining using masked autoencoders. We leverage Robotic View Transformer (RVT), which uses a multi-view transformer to understand the 3D scene and predict gripper pose actions. We split RVT's multi-view transformer into visual encoder and action decoder, and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse. We evaluate 3D-MVP on a suite of virtual robot manipulation tasks and demonstrate improved performance over baselines. We also show promising results on a real robot platform with minimal finetuning. Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies. We will release code and pretrained models for 3D-MVP to facilitate future research. Project site: https://jasonqsy.github.io/3DMVP
RVT-2: Learning Precise Manipulation from Few Demonstrations
Jun 12, 2024
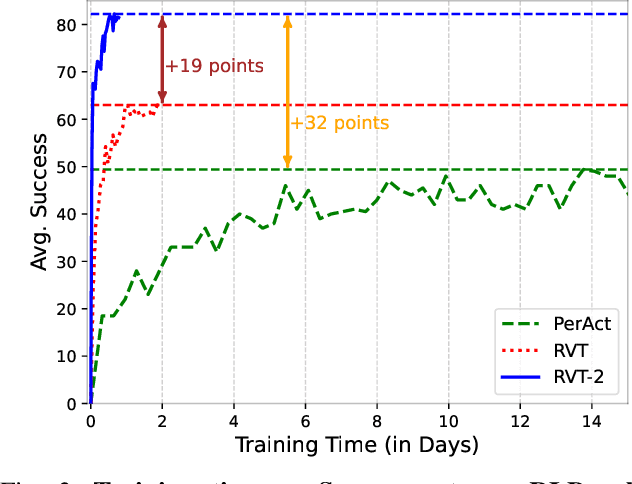


In this work, we study how to build a robotic system that can solve multiple 3D manipulation tasks given language instructions. To be useful in industrial and household domains, such a system should be capable of learning new tasks with few demonstrations and solving them precisely. Prior works, like PerAct and RVT, have studied this problem, however, they often struggle with tasks requiring high precision. We study how to make them more effective, precise, and fast. Using a combination of architectural and system-level improvements, we propose RVT-2, a multitask 3D manipulation model that is 6X faster in training and 2X faster in inference than its predecessor RVT. RVT-2 achieves a new state-of-the-art on RLBench, improving the success rate from 65% to 82%. RVT-2 is also effective in the real world, where it can learn tasks requiring high precision, like picking up and inserting plugs, with just 10 demonstrations. Visual results, code, and trained model are provided at: https://robotic-view-transformer-2.github.io/.
AdaDemo: Data-Efficient Demonstration Expansion for Generalist Robotic Agent
Apr 11, 2024



Encouraged by the remarkable achievements of language and vision foundation models, developing generalist robotic agents through imitation learning, using large demonstration datasets, has become a prominent area of interest in robot learning. The efficacy of imitation learning is heavily reliant on the quantity and quality of the demonstration datasets. In this study, we aim to scale up demonstrations in a data-efficient way to facilitate the learning of generalist robotic agents. We introduce AdaDemo (Adaptive Online Demonstration Expansion), a general framework designed to improve multi-task policy learning by actively and continually expanding the demonstration dataset. AdaDemo strategically collects new demonstrations to address the identified weakness in the existing policy, ensuring data efficiency is maximized. Through a comprehensive evaluation on a total of 22 tasks across two robotic manipulation benchmarks (RLBench and Adroit), we demonstrate AdaDemo's capability to progressively improve policy performance by guiding the generation of high-quality demonstration datasets in a data-efficient manner.
Shelving, Stacking, Hanging: Relational Pose Diffusion for Multi-modal Rearrangement
Jul 10, 2023


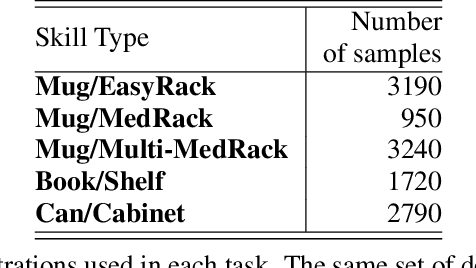
We propose a system for rearranging objects in a scene to achieve a desired object-scene placing relationship, such as a book inserted in an open slot of a bookshelf. The pipeline generalizes to novel geometries, poses, and layouts of both scenes and objects, and is trained from demonstrations to operate directly on 3D point clouds. Our system overcomes challenges associated with the existence of many geometrically-similar rearrangement solutions for a given scene. By leveraging an iterative pose de-noising training procedure, we can fit multi-modal demonstration data and produce multi-modal outputs while remaining precise and accurate. We also show the advantages of conditioning on relevant local geometric features while ignoring irrelevant global structure that harms both generalization and precision. We demonstrate our approach on three distinct rearrangement tasks that require handling multi-modality and generalization over object shape and pose in both simulation and the real world. Project website, code, and videos: https://anthonysimeonov.github.io/rpdiff-multi-modal/
Infinite Photorealistic Worlds using Procedural Generation
Jun 26, 2023
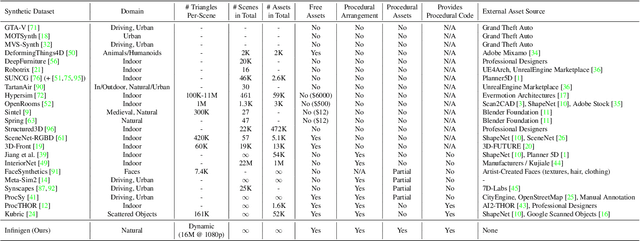


We introduce Infinigen, a procedural generator of photorealistic 3D scenes of the natural world. Infinigen is entirely procedural: every asset, from shape to texture, is generated from scratch via randomized mathematical rules, using no external source and allowing infinite variation and composition. Infinigen offers broad coverage of objects and scenes in the natural world including plants, animals, terrains, and natural phenomena such as fire, cloud, rain, and snow. Infinigen can be used to generate unlimited, diverse training data for a wide range of computer vision tasks including object detection, semantic segmentation, optical flow, and 3D reconstruction. We expect Infinigen to be a useful resource for computer vision research and beyond. Please visit https://infinigen.org for videos, code and pre-generated data.
RVT: Robotic View Transformer for 3D Object Manipulation
Jun 26, 2023


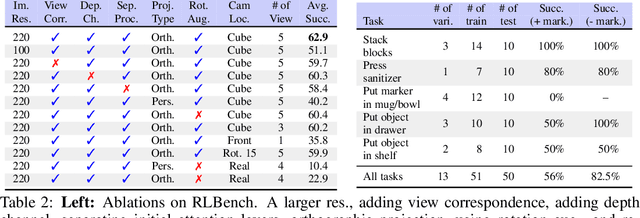
For 3D object manipulation, methods that build an explicit 3D representation perform better than those relying only on camera images. But using explicit 3D representations like voxels comes at large computing cost, adversely affecting scalability. In this work, we propose RVT, a multi-view transformer for 3D manipulation that is both scalable and accurate. Some key features of RVT are an attention mechanism to aggregate information across views and re-rendering of the camera input from virtual views around the robot workspace. In simulations, we find that a single RVT model works well across 18 RLBench tasks with 249 task variations, achieving 26% higher relative success than the existing state-of-the-art method (PerAct). It also trains 36X faster than PerAct for achieving the same performance and achieves 2.3X the inference speed of PerAct. Further, RVT can perform a variety of manipulation tasks in the real world with just a few ($\sim$10) demonstrations per task. Visual results, code, and trained model are provided at https://robotic-view-transformer.github.io/.
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Sep 22, 2022



Task planning can require defining myriad domain knowledge about the world in which a robot needs to act. To ameliorate that effort, large language models (LLMs) can be used to score potential next actions during task planning, and even generate action sequences directly, given an instruction in natural language with no additional domain information. However, such methods either require enumerating all possible next steps for scoring, or generate free-form text that may contain actions not possible on a given robot in its current context. We present a programmatic LLM prompt structure that enables plan generation functional across situated environments, robot capabilities, and tasks. Our key insight is to prompt the LLM with program-like specifications of the available actions and objects in an environment, as well as with example programs that can be executed. We make concrete recommendations about prompt structure and generation constraints through ablation experiments, demonstrate state of the art success rates in VirtualHome household tasks, and deploy our method on a physical robot arm for tabletop tasks. Website at progprompt.github.io