 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAWER: Digital Reconstruction and Articulation With Environment Realism
Apr 22, 2025Creating virtual digital replicas from real-world data unlocks significant potential across domains like gaming and robotics. In this paper, we present DRAWER, a novel framework that converts a video of a static indoor scene into a photorealistic and interactive digital environment. Our approach centers on two main contributions: (i) a reconstruction module based on a dual scene representation that reconstructs the scene with fine-grained geometric details, and (ii) an articulation module that identifies articulation types and hinge positions, reconstructs simulatable shapes and appearances and integrates them into the scene. The resulting virtual environment is photorealistic, interactive, and runs in real time, with compatibility for game engines and robotic simulation platforms. We demonstrate the potential of DRAWER by using it to automatically create an interactive game in Unreal Engine and to enable real-to-sim-to-real transfer for robotics applications.
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Apr 03, 2025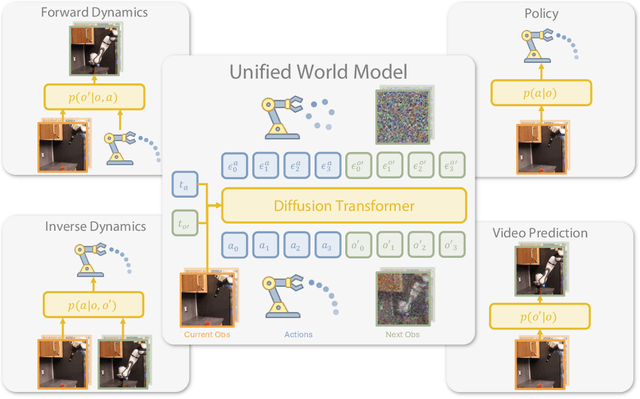
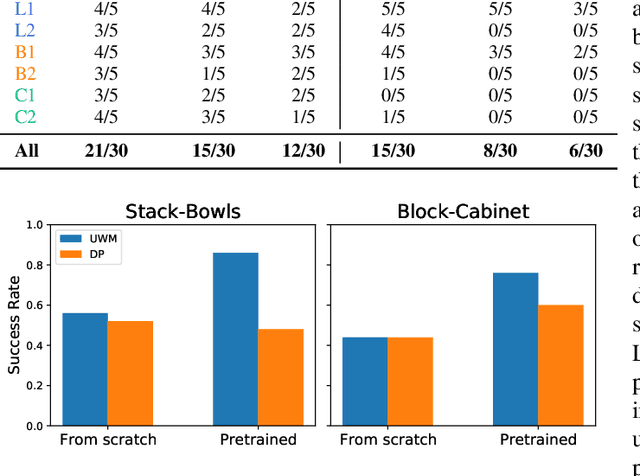


Imitation learning has emerged as a promising approach towards building generalist robots. However, scaling imitation learning for large robot foundation models remains challenging due to its reliance on high-quality expert demonstrations. Meanwhile, large amounts of video data depicting a wide range of environments and diverse behaviors are readily available. This data provides a rich source of information about real-world dynamics and agent-environment interactions. Leveraging this data directly for imitation learning, however, has proven difficult due to the lack of action annotation required for most contemporary methods. In this work, we present Unified World Models (UWM), a framework that allows for leveraging both video and action data for policy learning. Specifically, a UWM integrates an action diffusion process and a video diffusion process within a unified transformer architecture, where independent diffusion timesteps govern each modality. We show that by simply controlling each diffusion timestep, UWM can flexibly represent a policy, a forward dynamics, an inverse dynamics, and a video generator. Through simulated and real-world experiments, we show that: (1) UWM enables effective pretraining on large-scale multitask robot datasets with both dynamics and action predictions, resulting in more generalizable and robust policies than imitation learning, (2) UWM naturally facilitates learning from action-free video data through independent control of modality-specific diffusion timesteps, further improving the performance of finetuned policies. Our results suggest that UWM offers a promising step toward harnessing large, heterogeneous datasets for scalable robot learning, and provides a simple unification between the often disparate paradigms of imitation learning and world modeling. Videos and code are available at https://weirdlabuw.github.io/uwm/.
HAMSTER: Hierarchical Action Models For Open-World Robot Manipulation
Feb 08, 2025



Large foundation models have shown strong open-world generalization to complex problems in vision and language, but similar levels of generalization have yet to be achieved in robotics. One fundamental challenge is the lack of robotic data, which are typically obtained through expensive on-robot operation. A promising remedy is to leverage cheaper, off-domain data such as action-free videos, hand-drawn sketches or simulation data. In this work, we posit that hierarchical vision-language-action (VLA) models can be more effective in utilizing off-domain data than standard monolithic VLA models that directly finetune vision-language models (VLMs) to predict actions. In particular, we study a class of hierarchical VLA models, where the high-level VLM is finetuned to produce a coarse 2D path indicating the desired robot end-effector trajectory given an RGB image and a task description. The intermediate 2D path prediction is then served as guidance to the low-level, 3D-aware control policy capable of precise manipulation. Doing so alleviates the high-level VLM from fine-grained action prediction, while reducing the low-level policy's burden on complex task-level reasoning. We show that, with the hierarchical design, the high-level VLM can transfer across significant domain gaps between the off-domain finetuning data and real-robot testing scenarios, including differences on embodiments, dynamics, visual appearances and task semantics, etc. In the real-robot experiments, we observe an average of 20% improvement in success rate across seven different axes of generalization over OpenVLA, representing a 50% relative gain. Visual results are provided at: https://hamster-robot.github.io/