 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
Mar 02, 2026General-purpose robot reward models are typically trained to predict absolute task progress from expert demonstrations, providing only local, frame-level supervision. While effective for expert demonstrations, this paradigm scales poorly to large-scale robotics datasets where failed and suboptimal trajectories are abundant and assigning dense progress labels is ambiguous. We introduce Robometer, a scalable reward modeling framework that combines intra-trajectory progress supervision with inter-trajectory preference supervision. Robometer is trained with a dual objective: a frame-level progress loss that anchors reward magnitude on expert data, and a trajectory-comparison preference loss that imposes global ordering constraints across trajectories of the same task, enabling effective learning from both real and augmented failed trajectories. To support this formulation at scale, we curate RBM-1M, a reward-learning dataset comprising over one million trajectories spanning diverse robot embodiments and tasks, including substantial suboptimal and failure data. Across benchmarks and real-world evaluations, Robometer learns more generalizable reward functions than prior methods and improves robot learning performance across a diverse set of downstream applications. Code, model weights, and videos at https://robometer.github.io/.
HAND Me the Data: Fast Robot Adaptation via Hand Path Retrieval
May 28, 2025



We hand the community HAND, a simple and time-efficient method for teaching robots new manipulation tasks through human hand demonstrations. Instead of relying on task-specific robot demonstrations collected via teleoperation, HAND uses easy-to-provide hand demonstrations to retrieve relevant behaviors from task-agnostic robot play data. Using a visual tracking pipeline, HAND extracts the motion of the human hand from the hand demonstration and retrieves robot sub-trajectories in two stages: first filtering by visual similarity, then retrieving trajectories with similar behaviors to the hand. Fine-tuning a policy on the retrieved data enables real-time learning of tasks in under four minutes, without requiring calibrated cameras or detailed hand pose estimation. Experiments also show that HAND outperforms retrieval baselines by over 2x in average task success rates on real robots. Videos can be found at our project website: https://liralab.usc.edu/handretrieval/.
ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations
May 16, 2025

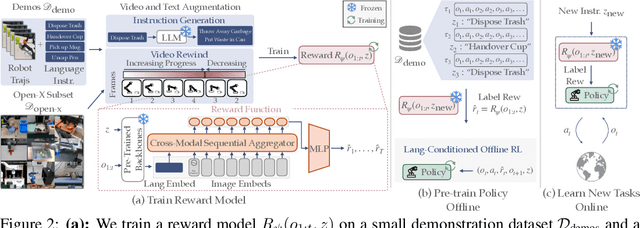
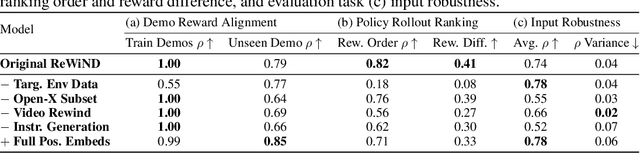
We introduce ReWiND, a framework for learning robot manipulation tasks solely from language instructions without per-task demonstrations. Standard reinforcement learning (RL) and imitation learning methods require expert supervision through human-designed reward functions or demonstrations for every new task. In contrast, ReWiND starts from a small demonstration dataset to learn: (1) a data-efficient, language-conditioned reward function that labels the dataset with rewards, and (2) a language-conditioned policy pre-trained with offline RL using these rewards. Given an unseen task variation, ReWiND fine-tunes the pre-trained policy using the learned reward function, requiring minimal online interaction. We show that ReWiND's reward model generalizes effectively to unseen tasks, outperforming baselines by up to 2.4x in reward generalization and policy alignment metrics. Finally, we demonstrate that ReWiND enables sample-efficient adaptation to new tasks, beating baselines by 2x in simulation and improving real-world pretrained bimanual policies by 5x, taking a step towards scalable, real-world robot learning. See website at https://rewind-reward.github.io/.
HAMSTER: Hierarchical Action Models For Open-World Robot Manipulation
Feb 08, 2025



Large foundation models have shown strong open-world generalization to complex problems in vision and language, but similar levels of generalization have yet to be achieved in robotics. One fundamental challenge is the lack of robotic data, which are typically obtained through expensive on-robot operation. A promising remedy is to leverage cheaper, off-domain data such as action-free videos, hand-drawn sketches or simulation data. In this work, we posit that hierarchical vision-language-action (VLA) models can be more effective in utilizing off-domain data than standard monolithic VLA models that directly finetune vision-language models (VLMs) to predict actions. In particular, we study a class of hierarchical VLA models, where the high-level VLM is finetuned to produce a coarse 2D path indicating the desired robot end-effector trajectory given an RGB image and a task description. The intermediate 2D path prediction is then served as guidance to the low-level, 3D-aware control policy capable of precise manipulation. Doing so alleviates the high-level VLM from fine-grained action prediction, while reducing the low-level policy's burden on complex task-level reasoning. We show that, with the hierarchical design, the high-level VLM can transfer across significant domain gaps between the off-domain finetuning data and real-robot testing scenarios, including differences on embodiments, dynamics, visual appearances and task semantics, etc. In the real-robot experiments, we observe an average of 20% improvement in success rate across seven different axes of generalization over OpenVLA, representing a 50% relative gain. Visual results are provided at: https://hamster-robot.github.io/
EXTRACT: Efficient Policy Learning by Extracting Transferrable Robot Skills from Offline Data
Jun 25, 2024



Most reinforcement learning (RL) methods focus on learning optimal policies over low-level action spaces. While these methods can perform well in their training environments, they lack the flexibility to transfer to new tasks. Instead, RL agents that can act over useful, temporally extended skills rather than low-level actions can learn new tasks more easily. Prior work in skill-based RL either requires expert supervision to define useful skills, which is hard to scale, or learns a skill-space from offline data with heuristics that limit the adaptability of the skills, making them difficult to transfer during downstream RL. Our approach, EXTRACT, instead utilizes pre-trained vision language models to extract a discrete set of semantically meaningful skills from offline data, each of which is parameterized by continuous arguments, without human supervision. This skill parameterization allows robots to learn new tasks by only needing to learn when to select a specific skill and how to modify its arguments for the specific task. We demonstrate through experiments in sparse-reward, image-based, robot manipulation environments that EXTRACT can more quickly learn new tasks than prior works, with major gains in sample efficiency and performance over prior skill-based RL. Website at https://www.jessezhang.net/projects/extract/.
RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Feb 10, 2024



Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains - including classic control, as well as manipulation of rigid, articulated, and deformable objects - without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions.
LiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers
Dec 14, 2023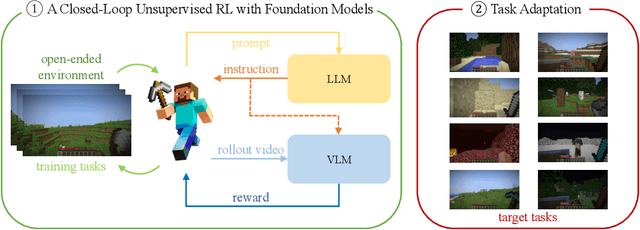

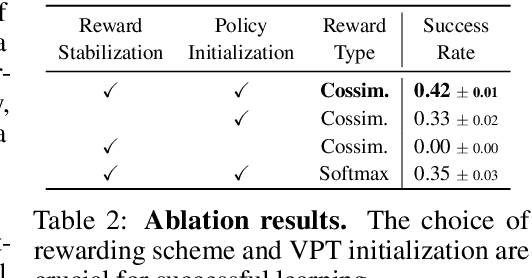
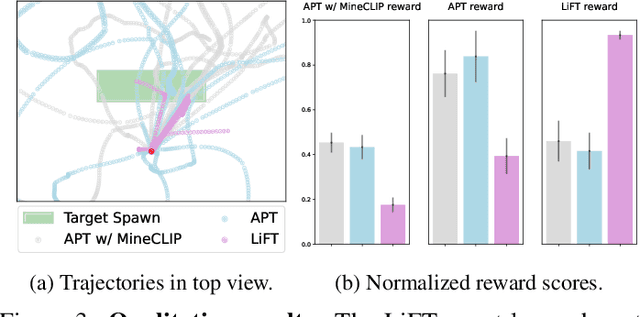
We propose a framework that leverages foundation models as teachers, guiding a reinforcement learning agent to acquire semantically meaningful behavior without human feedback. In our framework, the agent receives task instructions grounded in a training environment from large language models. Then, a vision-language model guides the agent in learning the multi-task language-conditioned policy by providing reward feedback. We demonstrate that our method can learn semantically meaningful skills in a challenging open-ended MineDojo environment while prior unsupervised skill discovery methods struggle. Additionally, we discuss observed challenges of using off-the-shelf foundation models as teachers and our efforts to address them.
Bootstrap Your Own Skills: Learning to Solve New Tasks with Large Language Model Guidance
Oct 17, 2023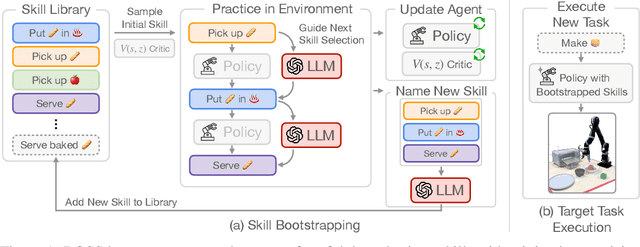
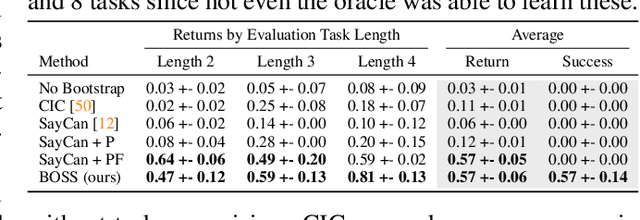
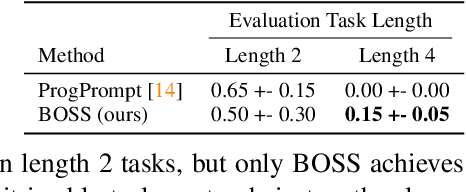
We propose BOSS, an approach that automatically learns to solve new long-horizon, complex, and meaningful tasks by growing a learned skill library with minimal supervision. Prior work in reinforcement learning require expert supervision, in the form of demonstrations or rich reward functions, to learn long-horizon tasks. Instead, our approach BOSS (BOotStrapping your own Skills) learns to accomplish new tasks by performing "skill bootstrapping," where an agent with a set of primitive skills interacts with the environment to practice new skills without receiving reward feedback for tasks outside of the initial skill set. This bootstrapping phase is guided by large language models (LLMs) that inform the agent of meaningful skills to chain together. Through this process, BOSS builds a wide range of complex and useful behaviors from a basic set of primitive skills. We demonstrate through experiments in realistic household environments that agents trained with our LLM-guided bootstrapping procedure outperform those trained with naive bootstrapping as well as prior unsupervised skill acquisition methods on zero-shot execution of unseen, long-horizon tasks in new environments. Website at clvrai.com/boss.
RoboCLIP: One Demonstration is Enough to Learn Robot Policies
Oct 11, 2023



Reward specification is a notoriously difficult problem in reinforcement learning, requiring extensive expert supervision to design robust reward functions. Imitation learning (IL) methods attempt to circumvent these problems by utilizing expert demonstrations but typically require a large number of in-domain expert demonstrations. Inspired by advances in the field of Video-and-Language Models (VLMs), we present RoboCLIP, an online imitation learning method that uses a single demonstration (overcoming the large data requirement) in the form of a video demonstration or a textual description of the task to generate rewards without manual reward function design. Additionally, RoboCLIP can also utilize out-of-domain demonstrations, like videos of humans solving the task for reward generation, circumventing the need to have the same demonstration and deployment domains. RoboCLIP utilizes pretrained VLMs without any finetuning for reward generation. Reinforcement learning agents trained with RoboCLIP rewards demonstrate 2-3 times higher zero-shot performance than competing imitation learning methods on downstream robot manipulation tasks, doing so using only one video/text demonstration.
TAIL: Task-specific Adapters for Imitation Learning with Large Pretrained Models
Oct 09, 2023



The full potential of large pretrained models remains largely untapped in control domains like robotics. This is mainly because of the scarcity of data and the computational challenges associated with training or fine-tuning these large models for such applications. Prior work mainly emphasizes effective pretraining of large models for decision-making, with little exploration into how to perform data-efficient continual adaptation of these models for new tasks. Recognizing these constraints, we introduce TAIL (Task-specific Adapters for Imitation Learning), a framework for efficient adaptation to new control tasks. Inspired by recent advancements in parameter-efficient fine-tuning in language domains, we explore efficient fine-tuning techniques -- e.g., Bottleneck Adapters, P-Tuning, and Low-Rank Adaptation (LoRA) -- in TAIL to adapt large pretrained models for new tasks with limited demonstration data. Our extensive experiments in large-scale language-conditioned manipulation tasks comparing prevalent parameter-efficient fine-tuning techniques and adaptation baselines suggest that TAIL with LoRA can achieve the best post-adaptation performance with only 1\% of the trainable parameters of full fine-tuning, while avoiding catastrophic forgetting and preserving adaptation plasticity in continual learning settings.