 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboCLIP: One Demonstration is Enough to Learn Robot Policies
Oct 11, 2023



Reward specification is a notoriously difficult problem in reinforcement learning, requiring extensive expert supervision to design robust reward functions. Imitation learning (IL) methods attempt to circumvent these problems by utilizing expert demonstrations but typically require a large number of in-domain expert demonstrations. Inspired by advances in the field of Video-and-Language Models (VLMs), we present RoboCLIP, an online imitation learning method that uses a single demonstration (overcoming the large data requirement) in the form of a video demonstration or a textual description of the task to generate rewards without manual reward function design. Additionally, RoboCLIP can also utilize out-of-domain demonstrations, like videos of humans solving the task for reward generation, circumventing the need to have the same demonstration and deployment domains. RoboCLIP utilizes pretrained VLMs without any finetuning for reward generation. Reinforcement learning agents trained with RoboCLIP rewards demonstrate 2-3 times higher zero-shot performance than competing imitation learning methods on downstream robot manipulation tasks, doing so using only one video/text demonstration.
Model2Detector: Widening the Information Bottleneck for Out-of-Distribution Detection using a Handful of Gradient Steps
Feb 22, 2022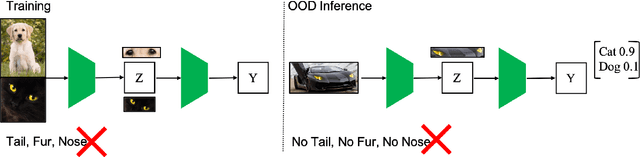
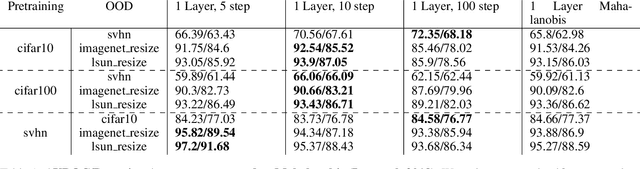

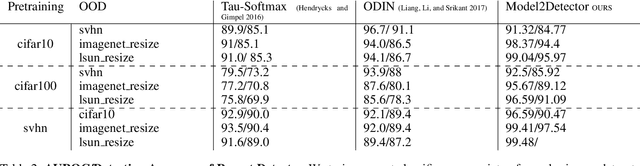
Out-of-distribution detection is an important capability that has long eluded vanilla neural networks. Deep Neural networks (DNNs) tend to generate over-confident predictions when presented with inputs that are significantly out-of-distribution (OOD). This can be dangerous when employing machine learning systems in the wild as detecting attacks can thus be difficult. Recent advances inference-time out-of-distribution detection help mitigate some of these problems. However, existing methods can be restrictive as they are often computationally expensive. Additionally, these methods require training of a downstream detector model which learns to detect OOD inputs from in-distribution ones. This, therefore, adds latency during inference. Here, we offer an information theoretic perspective on why neural networks are inherently incapable of OOD detection. We attempt to mitigate these flaws by converting a trained model into a an OOD detector using a handful of steps of gradient descent. Our work can be employed as a post-processing method whereby an inference-time ML system can convert a trained model into an OOD detector. Experimentally, we show how our method consistently outperforms the state-of-the-art in detection accuracy on popular image datasets while also reducing computational complexity.
GalilAI: Out-of-Task Distribution Detection using Causal Active Experimentation for Safe Transfer RL
Oct 29, 2021



Out-of-distribution (OOD) detection is a well-studied topic in supervised learning. Extending the successes in supervised learning methods to the reinforcement learning (RL) setting, however, is difficult due to the data generating process - RL agents actively query their environment for data, and the data are a function of the policy followed by the agent. An agent could thus neglect a shift in the environment if its policy did not lead it to explore the aspect of the environment that shifted. Therefore, to achieve safe and robust generalization in RL, there exists an unmet need for OOD detection through active experimentation. Here, we attempt to bridge this lacuna by first defining a causal framework for OOD scenarios or environments encountered by RL agents in the wild. Then, we propose a novel task: that of Out-of-Task Distribution (OOTD) detection. We introduce an RL agent that actively experiments in a test environment and subsequently concludes whether it is OOTD or not. We name our method GalilAI, in honor of Galileo Galilei, as it discovers, among other causal processes, that gravitational acceleration is independent of the mass of a body. Finally, we propose a simple probabilistic neural network baseline for comparison, which extends extant Model-Based RL. We find that GalilAI outperforms the baseline significantly. See visualizations of our method https://galil-ai.github.io/
Video2Skill: Adapting Events in Demonstration Videos to Skills in an Environment using Cyclic MDP Homomorphisms
Sep 09, 2021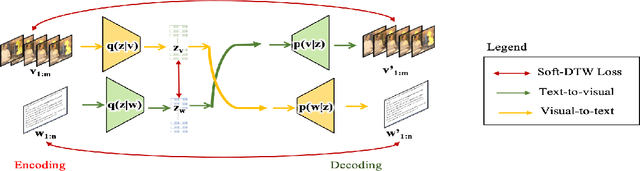
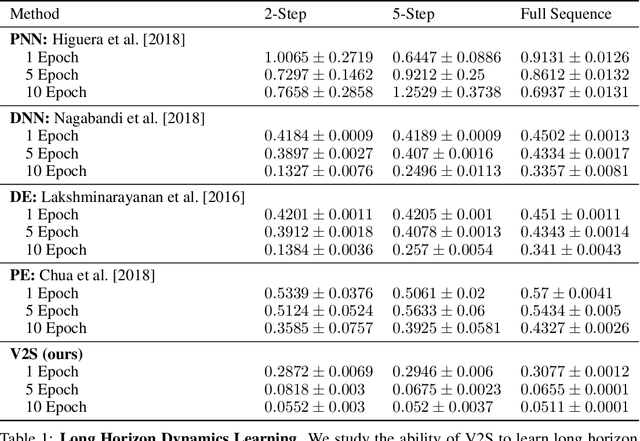
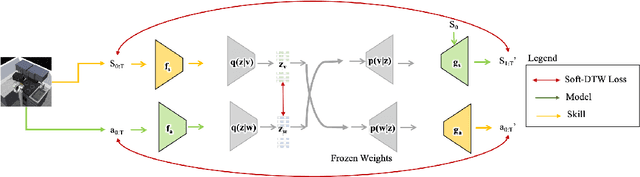
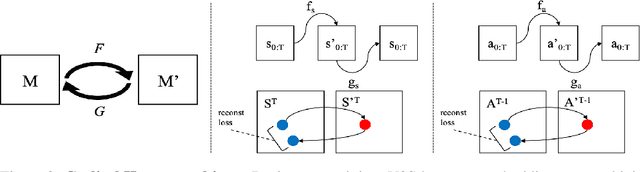
Humans excel at learning long-horizon tasks from demonstrations augmented with textual commentary, as evidenced by the burgeoning popularity of tutorial videos online. Intuitively, this capability can be separated into 2 distinct subtasks - first, dividing a long-horizon demonstration sequence into semantically meaningful events; second, adapting such events into meaningful behaviors in one's own environment. Here, we present Video2Skill (V2S), which attempts to extend this capability to artificial agents by allowing a robot arm to learn from human cooking videos. We first use sequence-to-sequence Auto-Encoder style architectures to learn a temporal latent space for events in long-horizon demonstrations. We then transfer these representations to the robotic target domain, using a small amount of offline and unrelated interaction data (sequences of state-action pairs of the robot arm controlled by an expert) to adapt these events into actionable representations, i.e., skills. Through experiments, we demonstrate that our approach results in self-supervised analogy learning, where the agent learns to draw analogies between motions in human demonstration data and behaviors in the robotic environment. We also demonstrate the efficacy of our approach on model learning - demonstrating how Video2Skill utilizes prior knowledge from human demonstration to outperform traditional model learning of long-horizon dynamics. Finally, we demonstrate the utility of our approach for non-tabula rasa decision-making, i.e, utilizing video demonstration for zero-shot skill generation.