 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARC: Soft Actor Retrospective Critic
Jun 28, 2023


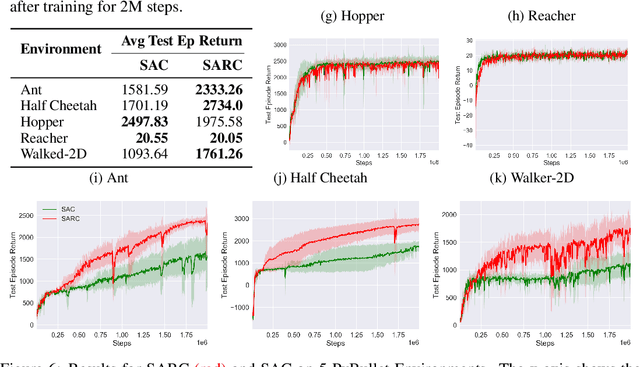
The two-time scale nature of SAC, which is an actor-critic algorithm, is characterised by the fact that the critic estimate has not converged for the actor at any given time, but since the critic learns faster than the actor, it ensures eventual consistency between the two. Various strategies have been introduced in literature to learn better gradient estimates to help achieve better convergence. Since gradient estimates depend upon the critic, we posit that improving the critic can provide a better gradient estimate for the actor at each time. Utilizing this, we propose Soft Actor Retrospective Critic (SARC), where we augment the SAC critic loss with another loss term - retrospective loss - leading to faster critic convergence and consequently, better policy gradient estimates for the actor. An existing implementation of SAC can be easily adapted to SARC with minimal modifications. Through extensive experimentation and analysis, we show that SARC provides consistent improvement over SAC on benchmark environments. We plan to open-source the code and all experiment data at: https://github.com/sukritiverma1996/SARC.
HyHTM: Hyperbolic Geometry based Hierarchical Topic Models
May 16, 2023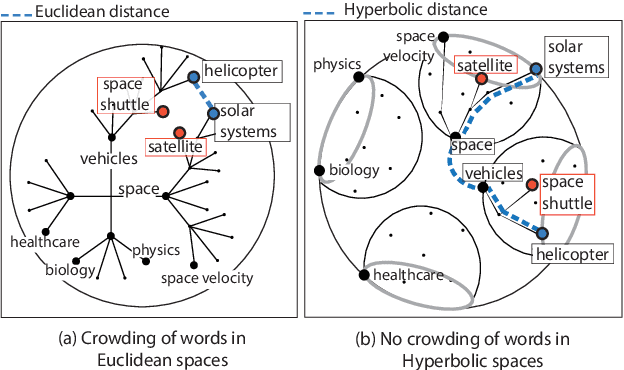
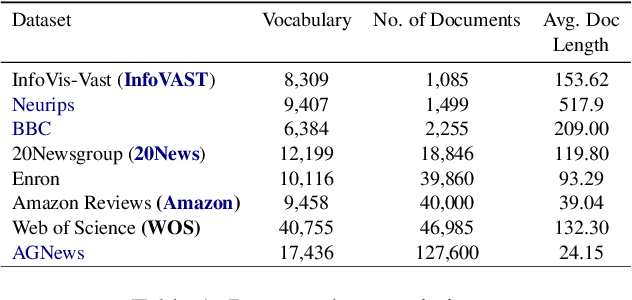

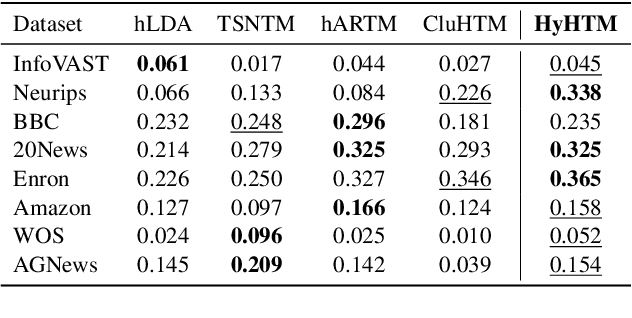
Hierarchical Topic Models (HTMs) are useful for discovering topic hierarchies in a collection of documents. However, traditional HTMs often produce hierarchies where lowerlevel topics are unrelated and not specific enough to their higher-level topics. Additionally, these methods can be computationally expensive. We present HyHTM - a Hyperbolic geometry based Hierarchical Topic Models - that addresses these limitations by incorporating hierarchical information from hyperbolic geometry to explicitly model hierarchies in topic models. Experimental results with four baselines show that HyHTM can better attend to parent-child relationships among topics. HyHTM produces coherent topic hierarchies that specialise in granularity from generic higher-level topics to specific lowerlevel topics. Further, our model is significantly faster and leaves a much smaller memory footprint than our best-performing baseline.We have made the source code for our algorithm publicly accessible.
Video2Skill: Adapting Events in Demonstration Videos to Skills in an Environment using Cyclic MDP Homomorphisms
Sep 09, 2021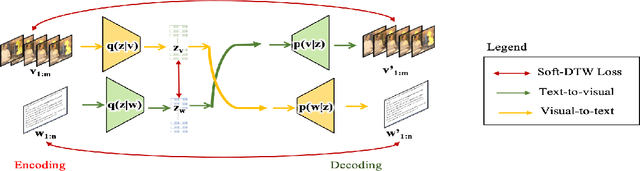
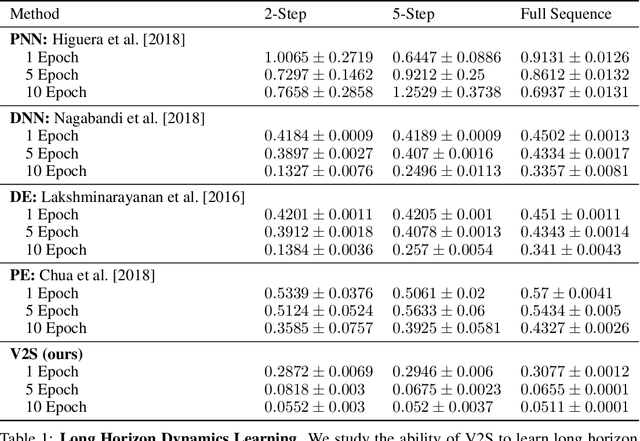
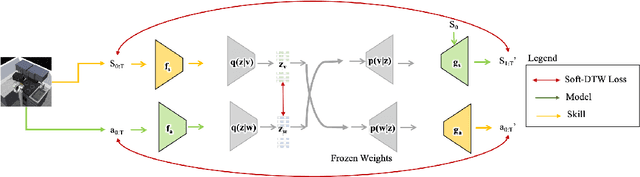
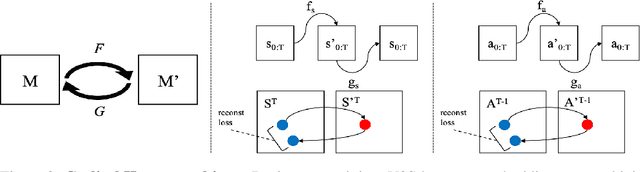
Humans excel at learning long-horizon tasks from demonstrations augmented with textual commentary, as evidenced by the burgeoning popularity of tutorial videos online. Intuitively, this capability can be separated into 2 distinct subtasks - first, dividing a long-horizon demonstration sequence into semantically meaningful events; second, adapting such events into meaningful behaviors in one's own environment. Here, we present Video2Skill (V2S), which attempts to extend this capability to artificial agents by allowing a robot arm to learn from human cooking videos. We first use sequence-to-sequence Auto-Encoder style architectures to learn a temporal latent space for events in long-horizon demonstrations. We then transfer these representations to the robotic target domain, using a small amount of offline and unrelated interaction data (sequences of state-action pairs of the robot arm controlled by an expert) to adapt these events into actionable representations, i.e., skills. Through experiments, we demonstrate that our approach results in self-supervised analogy learning, where the agent learns to draw analogies between motions in human demonstration data and behaviors in the robotic environment. We also demonstrate the efficacy of our approach on model learning - demonstrating how Video2Skill utilizes prior knowledge from human demonstration to outperform traditional model learning of long-horizon dynamics. Finally, we demonstrate the utility of our approach for non-tabula rasa decision-making, i.e, utilizing video demonstration for zero-shot skill generation.
Information-theoretic Evolution of Model Agnostic Global Explanations
May 14, 2021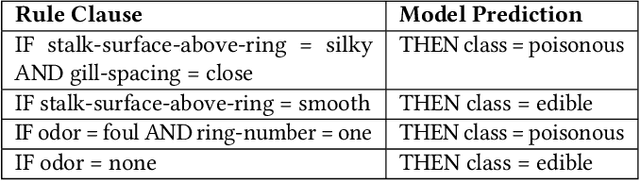
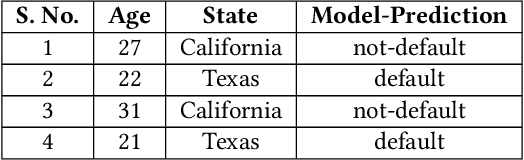
Explaining the behavior of black box machine learning models through human interpretable rules is an important research area. Recent work has focused on explaining model behavior locally i.e. for specific predictions as well as globally across the fields of vision, natural language, reinforcement learning and data science. We present a novel model-agnostic approach that derives rules to globally explain the behavior of classification models trained on numerical and/or categorical data. Our approach builds on top of existing local model explanation methods to extract conditions important for explaining model behavior for specific instances followed by an evolutionary algorithm that optimizes an information theory based fitness function to construct rules that explain global model behavior. We show how our approach outperforms existing approaches on a variety of datasets. Further, we introduce a parameter to evaluate the quality of interpretation under the scenario of distributional shift. This parameter evaluates how well the interpretation can predict model behavior for previously unseen data distributions. We show how existing approaches for interpreting models globally lack distributional robustness. Finally, we show how the quality of the interpretation can be improved under the scenario of distributional shift by adding out of distribution samples to the dataset used to learn the interpretation and thereby, increase robustness. All of the datasets used in our paper are open and publicly available. Our approach has been deployed in a leading digital marketing suite of products.
Unsupervised Hierarchical Concept Learning
Oct 06, 2020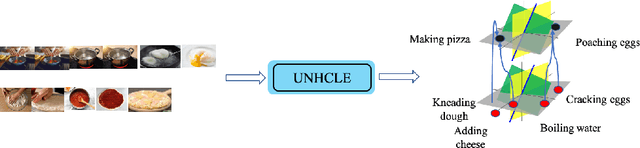

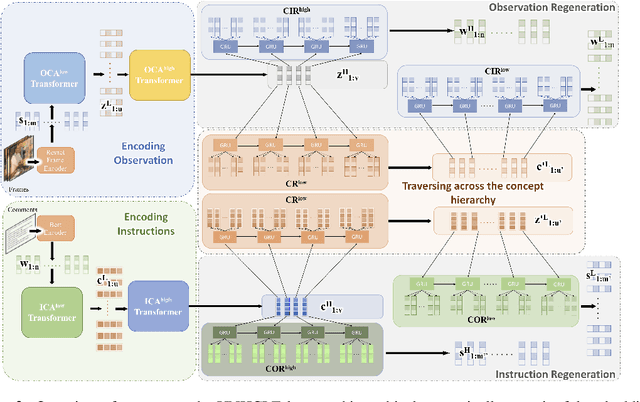
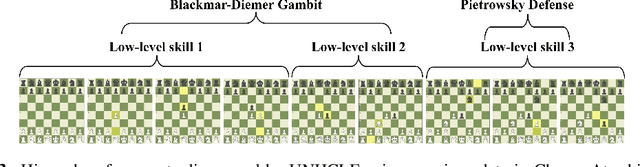
Discovering concepts (or temporal abstractions) in an unsupervised manner from demonstration data in the absence of an environment is an important problem. Organizing these discovered concepts hierarchically at different levels of abstraction is useful in discovering patterns, building ontologies, and generating tutorials from demonstration data. However, recent work to discover such concepts without access to any environment does not discover relationships (or a hierarchy) between these discovered concepts. In this paper, we present a Transformer-based concept abstraction architecture UNHCLE (pronounced uncle) that extracts a hierarchy of concepts in an unsupervised way from demonstration data. We empirically demonstrate how UNHCLE discovers meaningful hierarchies using datasets from Chess and Cooking domains. Finally, we show how UNHCLE learns meaningful language labels for concepts by using demonstration data augmented with natural language for cooking and chess. All of our code is available at https://github.com/UNHCLE/UNHCLE
MixBoost: Synthetic Oversampling with Boosted Mixup for Handling Extreme Imbalance
Sep 03, 2020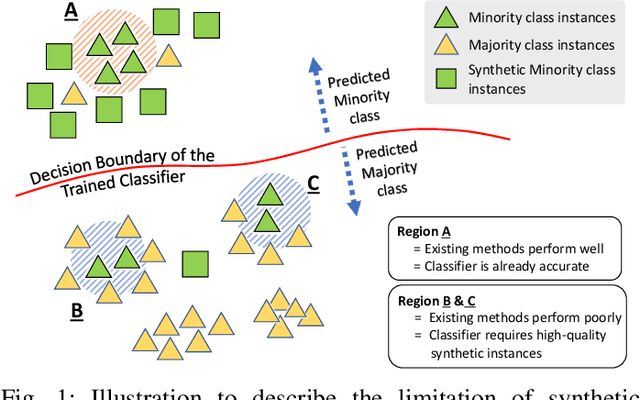
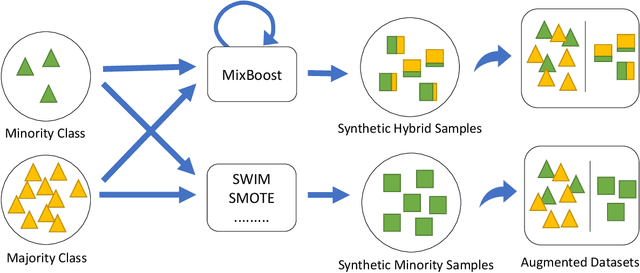
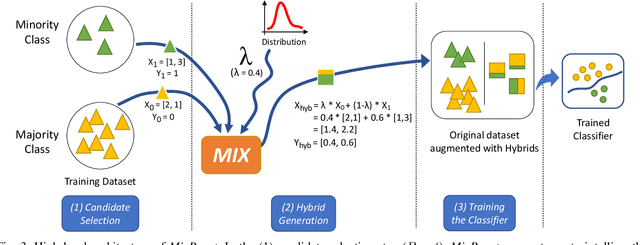
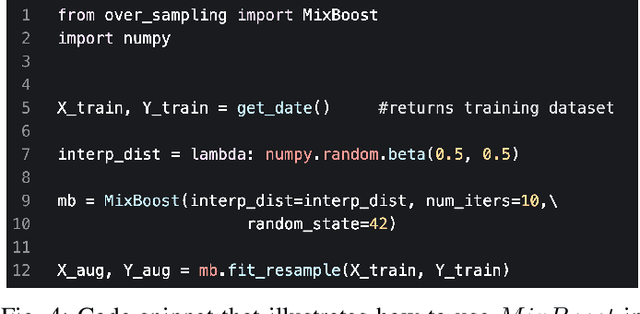
Training a classification model on a dataset where the instances of one class outnumber those of the other class is a challenging problem. Such imbalanced datasets are standard in real-world situations such as fraud detection, medical diagnosis, and computational advertising. We propose an iterative data augmentation method, MixBoost, which intelligently selects (Boost) and then combines (Mix) instances from the majority and minority classes to generate synthetic hybrid instances that have characteristics of both classes. We evaluate MixBoost on 20 benchmark datasets, show that it outperforms existing approaches, and test its efficacy through significance testing. We also present ablation studies to analyze the impact of the different components of MixBoost.
Inducing Cooperative behaviour in Sequential-Social dilemmas through Multi-Agent Reinforcement Learning using Status-Quo Loss
Feb 13, 2020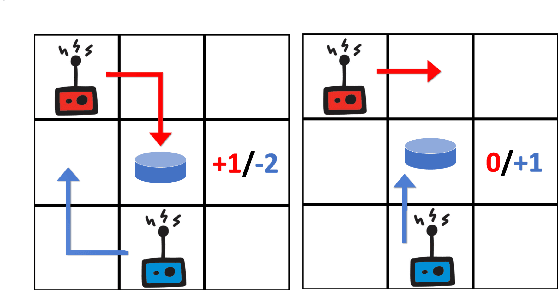


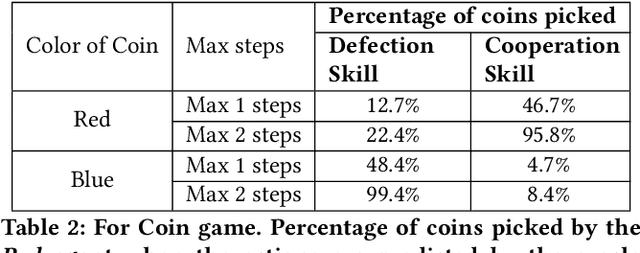
In social dilemma situations, individual rationality leads to sub-optimal group outcomes. Several human engagements can be modeled as a sequential (multi-step) social dilemmas. However, in contrast to humans, Deep Reinforcement Learning agents trained to optimize individual rewards in sequential social dilemmas converge to selfish, mutually harmful behavior. We introduce a status-quo loss (SQLoss) that encourages an agent to stick to the status quo, rather than repeatedly changing its policy. We show how agents trained with SQLoss evolve cooperative behavior in several social dilemma matrix games. To work with social dilemma games that have visual input, we propose GameDistill. GameDistill uses self-supervision and clustering to automatically extract cooperative and selfish policies from a social dilemma game. We combine GameDistill and SQLoss to show how agents evolve socially desirable cooperative behavior in the Coin Game.
Explain Your Move: Understanding Agent Actions Using Focused Feature Saliency
Dec 31, 2019

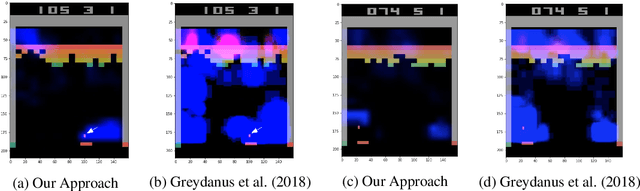
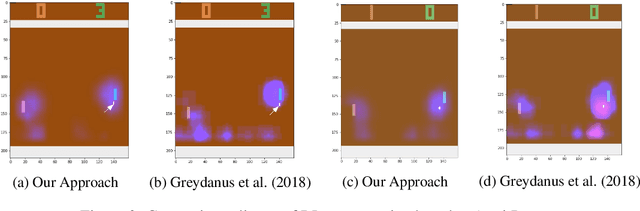
As deep reinforcement learning (RL) is applied to more tasks, there is a need to visualize and understand the behavior of learned agents. Saliency maps explain agent behavior by highlighting the features of the input state that are most relevant for the agent in taking an action. Existing perturbation-based approaches to compute saliency often highlight regions of the input that are not relevant to the action taken by the agent. Our approach generates more focused saliency maps by balancing two aspects (specificity and relevance) that capture different desiderata of saliency. The first captures the impact of perturbation on the relative expected reward of the action to be explained. The second downweights irrelevant features that alter the relative expected rewards of actions other than the action to be explained. We compare our approach with existing approaches on agents trained to play board games (Chess and Go) and Atari games (Breakout, Pong and Space Invaders). We show through illustrative examples (Chess, Atari, Go), human studies (Chess), and automated evaluation methods (Chess) that our approach generates saliency maps that are more interpretable for humans than existing approaches.
MAGIX: Model Agnostic Globally Interpretable Explanations
Jun 15, 2018
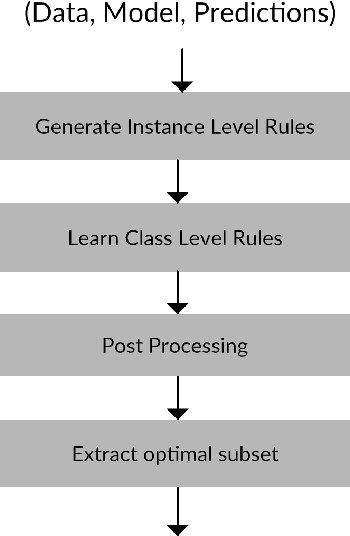

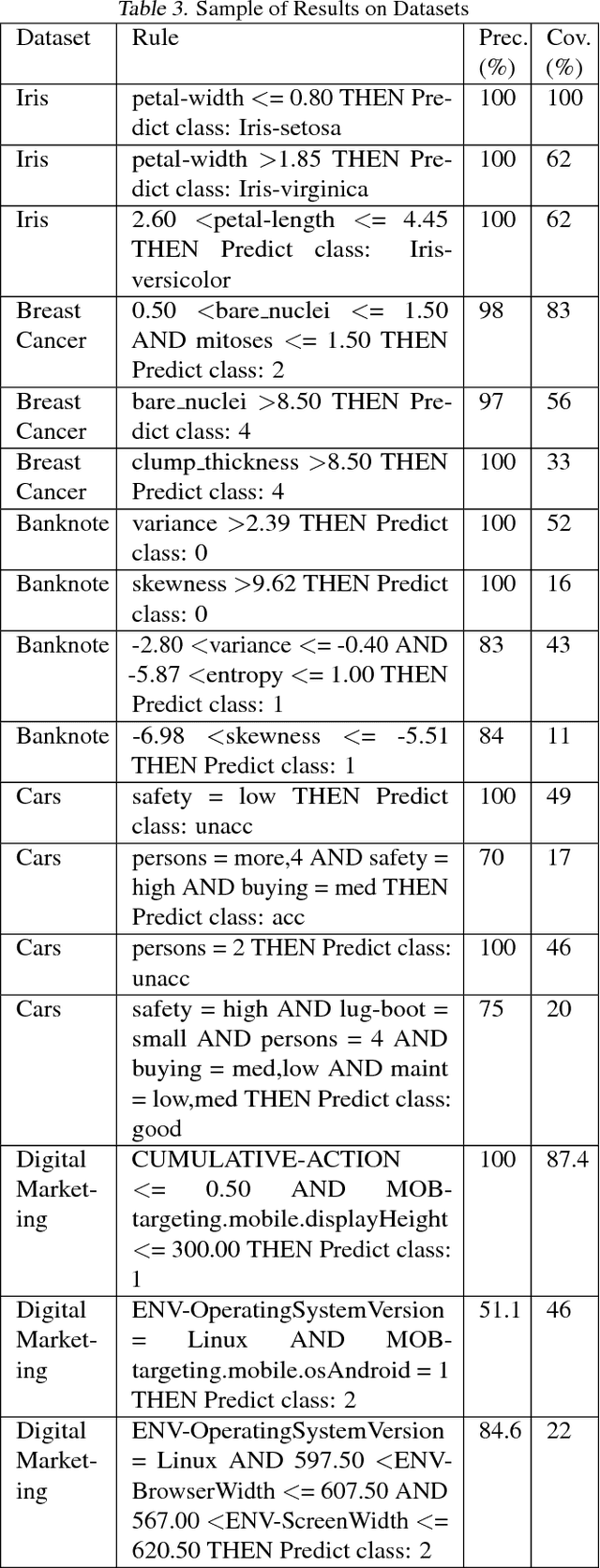
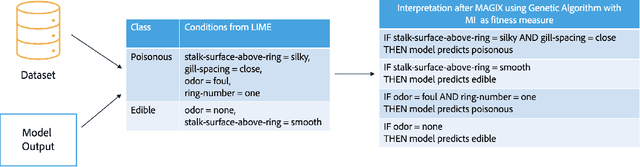
Explaining the behavior of a black box machine learning model at the instance level is useful for building trust. However, it is also important to understand how the model behaves globally. Such an understanding provides insight into both the data on which the model was trained and the patterns that it learned. We present here an approach that learns if-then rules to globally explain the behavior of black box machine learning models that have been used to solve classification problems. The approach works by first extracting conditions that were important at the instance level and then evolving rules through a genetic algorithm with an appropriate fitness function. Collectively, these rules represent the patterns followed by the model for decisioning and are useful for understanding its behavior. We demonstrate the validity and usefulness of the approach by interpreting black box models created using publicly available data sets as well as a private digital marketing data set.