 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARC: Soft Actor Retrospective Critic
Paper and Code



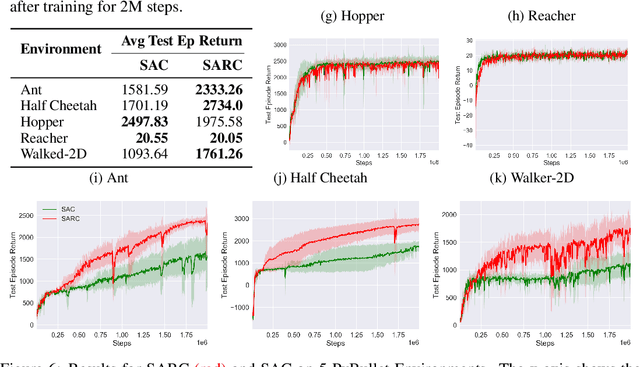
The two-time scale nature of SAC, which is an actor-critic algorithm, is characterised by the fact that the critic estimate has not converged for the actor at any given time, but since the critic learns faster than the actor, it ensures eventual consistency between the two. Various strategies have been introduced in literature to learn better gradient estimates to help achieve better convergence. Since gradient estimates depend upon the critic, we posit that improving the critic can provide a better gradient estimate for the actor at each time. Utilizing this, we propose Soft Actor Retrospective Critic (SARC), where we augment the SAC critic loss with another loss term - retrospective loss - leading to faster critic convergence and consequently, better policy gradient estimates for the actor. An existing implementation of SAC can be easily adapted to SARC with minimal modifications. Through extensive experimentation and analysis, we show that SARC provides consistent improvement over SAC on benchmark environments. We plan to open-source the code and all experiment data at: https://github.com/sukritiverma1996/SARC.