 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGLAMP: Knowledge Graph-guided Language model for Adaptive Multi-robot Planning and Replanning
Feb 04, 2026Heterogeneous multi-robot systems are increasingly deployed in long-horizon missions that require coordination among robots with diverse capabilities. However, existing planning approaches struggle to construct accurate symbolic representations and maintain plan consistency in dynamic environments. Classical PDDL planners require manually crafted symbolic models, while LLM-based planners often ignore agent heterogeneity and environmental uncertainty. We introduce KGLAMP, a knowledge-graph-guided LLM planning framework for heterogeneous multi-robot teams. The framework maintains a structured knowledge graph encoding object relations, spatial reachability, and robot capabilities, which guides the LLM in generating accurate PDDL problem specifications. The knowledge graph serves as a persistent, dynamically updated memory that incorporates new observations and triggers replanning upon detecting inconsistencies, enabling symbolic plans to adapt to evolving world states. Experiments on the MAT-THOR benchmark show that KGLAMP improves performance by at least 25.5% over both LLM-only and PDDL-based variants.
IANN-MPPI: Interaction-Aware Neural Network-Enhanced Model Predictive Path Integral Approach for Autonomous Driving
Jul 16, 2025Motion planning for autonomous vehicles (AVs) in dense traffic is challenging, often leading to overly conservative behavior and unmet planning objectives. This challenge stems from the AVs' limited ability to anticipate and respond to the interactive behavior of surrounding agents. Traditional decoupled prediction and planning pipelines rely on non-interactive predictions that overlook the fact that agents often adapt their behavior in response to the AV's actions. To address this, we propose Interaction-Aware Neural Network-Enhanced Model Predictive Path Integral (IANN-MPPI) control, which enables interactive trajectory planning by predicting how surrounding agents may react to each control sequence sampled by MPPI. To improve performance in structured lane environments, we introduce a spline-based prior for the MPPI sampling distribution, enabling efficient lane-changing behavior. We evaluate IANN-MPPI in a dense traffic merging scenario, demonstrating its ability to perform efficient merging maneuvers. Our project website is available at https://sites.google.com/berkeley.edu/iann-mppi
Graph-Grounded LLMs: Leveraging Graphical Function Calling to Minimize LLM Hallucinations
Mar 13, 2025The adoption of Large Language Models (LLMs) is rapidly expanding across various tasks that involve inherent graphical structures. Graphs are integral to a wide range of applications, including motion planning for autonomous vehicles, social networks, scene understanding, and knowledge graphs. Many problems, even those not initially perceived as graph-based, can be effectively addressed through graph theory. However, when applied to these tasks, LLMs often encounter challenges, such as hallucinations and mathematical inaccuracies. To overcome these limitations, we propose Graph-Grounded LLMs, a system that improves LLM performance on graph-related tasks by integrating a graph library through function calls. By grounding LLMs in this manner, we demonstrate significant reductions in hallucinations and improved mathematical accuracy in solving graph-based problems, as evidenced by the performance on the NLGraph benchmark. Finally, we showcase a disaster rescue application where the Graph-Grounded LLM acts as a decision-support system.
GFlowVLM: Enhancing Multi-step Reasoning in Vision-Language Models with Generative Flow Networks
Mar 09, 2025



Vision-Language Models (VLMs) have recently shown promising advancements in sequential decision-making tasks through task-specific fine-tuning. However, common fine-tuning methods, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) techniques like Proximal Policy Optimization (PPO), present notable limitations: SFT assumes Independent and Identically Distributed (IID) data, while PPO focuses on maximizing cumulative rewards. These limitations often restrict solution diversity and hinder generalization in multi-step reasoning tasks. To address these challenges, we introduce a novel framework, GFlowVLM, a framework that fine-tune VLMs using Generative Flow Networks (GFlowNets) to promote generation of diverse solutions for complex reasoning tasks. GFlowVLM models the environment as a non-Markovian decision process, allowing it to capture long-term dependencies essential for real-world applications. It takes observations and task descriptions as inputs to prompt chain-of-thought (CoT) reasoning which subsequently guides action selection. We use task based rewards to fine-tune VLM with GFlowNets. This approach enables VLMs to outperform prior fine-tuning methods, including SFT and RL. Empirical results demonstrate the effectiveness of GFlowVLM on complex tasks such as card games (NumberLine, BlackJack) and embodied planning tasks (ALFWorld), showing enhanced training efficiency, solution diversity, and stronger generalization capabilities across both in-distribution and out-of-distribution scenarios.
Generalized Mission Planning for Heterogeneous Multi-Robot Teams via LLM-constructed Hierarchical Trees
Jan 27, 2025We present a novel mission-planning strategy for heterogeneous multi-robot teams, taking into account the specific constraints and capabilities of each robot. Our approach employs hierarchical trees to systematically break down complex missions into manageable sub-tasks. We develop specialized APIs and tools, which are utilized by Large Language Models (LLMs) to efficiently construct these hierarchical trees. Once the hierarchical tree is generated, it is further decomposed to create optimized schedules for each robot, ensuring adherence to their individual constraints and capabilities. We demonstrate the effectiveness of our framework through detailed examples covering a wide range of missions, showcasing its flexibility and scalability.
Fast Inventory for 3GPP Ambient IoT Considering Device Unavailability due to Energy Harvesting
Jan 25, 2025



With the growing demand for massive internet of things (IoT), new IoT technology, namely ambient IoT (A-IoT), has been studied in the 3rd Generation Partnership Project (3GPP). A-IoT devices are batteryless and consume ultra-low power, relying on energy harvesting and energy storage to capture a small amount of energy for communication. A promising usecase of A-IoT is inventory, where a reader communicates with hundreds of A-IoT devices to identify them. However, energy harvesting required before communication can significantly delay or even fail inventory completion. In this work, solutions including duty cycled monitoring (DCM), device grouping and low-power receiving chain are proposed. Evaluation results show that the time required for a reader to complete an inventory procedure for hundreds of A-IoT devices can be reduced by 50% to 83% with the proposed methods.
Gaussian Lane Keeping: A Robust Prediction Baseline
Jul 26, 2024



Predicting agents' behavior for vehicles and pedestrians is challenging due to a myriad of factors including the uncertainty attached to different intentions, inter-agent interactions, traffic (environment) rules, individual inclinations, and agent dynamics. Consequently, a plethora of neural network-driven prediction models have been introduced in the literature to encompass these intricacies to accurately predict the agent behavior. Nevertheless, many of these approaches falter when confronted with scenarios beyond their training datasets, and lack interpretability, raising concerns about their suitability for real-world applications such as autonomous driving. Moreover, these models frequently demand additional training, substantial computational resources, or specific input features necessitating extensive implementation endeavors. In response, we propose Gaussian Lane Keeping (GLK), a robust prediction method for autonomous vehicles that can provide a solid baseline for comparison when developing new algorithms and a sanity check for real-world deployment. We provide several extensions to the GLK model, evaluate it on the CitySim dataset, and show that it outperforms the neural-network based predictions.
Towards Scalable & Efficient Interaction-Aware Planning in Autonomous Vehicles using Knowledge Distillation
Apr 02, 2024



Real-world driving involves intricate interactions among vehicles navigating through dense traffic scenarios. Recent research focuses on enhancing the interaction awareness of autonomous vehicles to leverage these interactions in decision-making. These interaction-aware planners rely on neural-network-based prediction models to capture inter-vehicle interactions, aiming to integrate these predictions with traditional control techniques such as Model Predictive Control. However, this integration of deep learning-based models with traditional control paradigms often results in computationally demanding optimization problems, relying on heuristic methods. This study introduces a principled and efficient method for combining deep learning with constrained optimization, employing knowledge distillation to train smaller and more efficient networks, thereby mitigating complexity. We demonstrate that these refined networks maintain the problem-solving efficacy of larger models while significantly accelerating optimization. Specifically, in the domain of interaction-aware trajectory planning for autonomous vehicles, we illustrate that training a smaller prediction network using knowledge distillation speeds up optimization without sacrificing accuracy.
SARC: Soft Actor Retrospective Critic
Jun 28, 2023


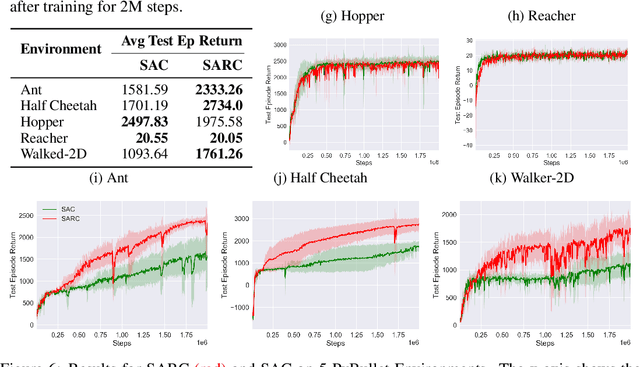
The two-time scale nature of SAC, which is an actor-critic algorithm, is characterised by the fact that the critic estimate has not converged for the actor at any given time, but since the critic learns faster than the actor, it ensures eventual consistency between the two. Various strategies have been introduced in literature to learn better gradient estimates to help achieve better convergence. Since gradient estimates depend upon the critic, we posit that improving the critic can provide a better gradient estimate for the actor at each time. Utilizing this, we propose Soft Actor Retrospective Critic (SARC), where we augment the SAC critic loss with another loss term - retrospective loss - leading to faster critic convergence and consequently, better policy gradient estimates for the actor. An existing implementation of SAC can be easily adapted to SARC with minimal modifications. Through extensive experimentation and analysis, we show that SARC provides consistent improvement over SAC on benchmark environments. We plan to open-source the code and all experiment data at: https://github.com/sukritiverma1996/SARC.
Interaction-Aware Trajectory Planning for Autonomous Vehicles with Analytic Integration of Neural Networks into Model Predictive Control
Jan 13, 2023



Autonomous vehicles (AVs) must share the driving space with other drivers and often employ conservative motion planning strategies to ensure safety. These conservative strategies can negatively impact AV's performance and significantly slow traffic throughput. Therefore, to avoid conservatism, we design an interaction-aware motion planner for the ego vehicle (AV) that interacts with surrounding vehicles to perform complex maneuvers in a locally optimal manner. Our planner uses a neural network-based interactive trajectory predictor and analytically integrates it with model predictive control (MPC). We solve the MPC optimization using the alternating direction method of multipliers (ADMM) and prove the algorithm's convergence. We provide an empirical study and compare our method with a baseline heuristic method.