 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOLO-MPPI: Multi-Scenario Motion Planning via Hierarchical Policy Optimization
Jun 15, 2026Robots deployed in the real world must plan motions across diverse scenarios without per-scenario retuning. End-to-end reinforcement learning (RL) can generalize across scenarios but often becomes brittle under distribution shift, reward misspecification, and stochastic interactions. Model predictive path integral (MPPI) control enables strong real-time refinement without gradients, but its performance depends on a well-shaped sampling prior, while manually designing the priors does not scale to multi-scenario deployment. We present HOLO-MPPI (High-level Offline, Low-level Online MPPI), a multi-scenario motion planning framework that combines high-level policy learning with low-level stochastic optimal control. Offline, we learn a high-level policy that proposes scenario-robust plans in an abstract action space, with a learned world model for online rollout. Online, the policy serves as a data-driven prior generator that parameterizes MPPI's sampling distribution conditioned on the current observation and goal. MPPI then optimizes low-level control sequences around this prior in real time to adapt to local disturbances. We instantiate HOLO-MPPI in autonomous driving by designing an effective high-level action space and tailored model architectures. Our evaluation across diverse driving scenarios shows that HOLO-MPPI improves upon MPPI and end-to-end RL baselines while maintaining real-time control.
Exact, Efficient, and Safe Occlusion-Aware Planning Using AH-Polyhedrons
Jun 13, 2026Safely handling occlusions is a fundamental challenge for autonomous mobile robots operating in dynamic environments. This issue is especially prominent in autonomous valet parking (AVP), where traffic rules are lax, occlusions are frequent and cluttered, and overly conservative behavior can leave vehicles stuck. However, existing methods either lack formal safety guarantees, assume agents follow road structures, or introduce conservatism, leaving occlusion-aware planning for AVP an open challenge. In this paper, we propose APRO (AH-Polyhedron Reachability for Occlusions), an exact and efficient occlusion-aware planning framework based on game-theoretic active perception and AH-polyhedron reachability analysis with AVP as our canonical use case. Our key insight is to reformulate set-based safety conditions in prior work as unions of AH-polyhedrons, enabling exact safety verification through linear programming (LP) without any additional conservatism in set computations or assumptions on road topology. We further show how the resulting safety conditions can be integrated into optimization-based planners or a bisection search scheme for real-time applications. We validate our method in simulation and hardware experiments, including data replay on a real-world parking lot dataset. Experimental results demonstrate that our method consistently achieved a 100% safety rate across all evaluated scenarios while maintaining real-time performance, resulting in safer and more optimal decisions than existing methods with formal safety guarantees.
VLM-Based Advanced Rider Assistance System for Motorcycle Safety
May 27, 2026Motorcycles face disproportionately high crash risks compared to cars due to limited protection and heightened sensitivity to surface hazards, yet Advanced Rider Assistance Systems (ARAS) remain underdeveloped relative to Advanced Driver Assistance Systems (ADAS). We propose a novel ARAS that enhances motorcycle safety through semantic perception and risk-aware planning. Our approach leverages Vision-Language Models (VLMs) for contextual hazard reasoning and integrates them with segmentation-based detection to construct dense risk maps. These maps encode both semantic characteristics (e.g., pothole severity, puddle slipperiness) and physical attributes (e.g., size, depth), which produce per-pixel hazard costs that capture motorcycle-specific risks. These maps are used by a sampling-based planner tailored to motorcycle dynamics to recommend throttle and steering actions that minimize hazard exposure while advancing toward the destination. We evaluate our system in different scenarios in the CARLA simulator. Compared to the baseline method, our method achieves higher success rates and lower hazard exposure, while qualitative results demonstrate interpretable risk maps and safe trajectory recommendations.
N3P: Accelerated Automated Parking via a Learning-Based Naturalistic Three-Stage Scheme
May 21, 2026Autonomous parking requires efficient path planning that ensures kinematic feasibility and collision avoidance in constrained environments. Hybrid A* is widely used but computationally expensive, while reinforcement learning (RL) methods lack reliability and often struggle with long-horizon geometric constraints, leading to suboptimal trajectories. We present N3P, a fast learning-based three-stage framework for automated parking. By introducing an intermediate preparatory pose and using a learning module to predict it, N3P decomposes the maneuver into simpler subproblems, thereby reducing computational complexity and accelerating path generation. We validate the framework by integrating it with Hybrid A* algorithms. Experiments in perpendicular and parallel parking scenarios show that N3P-enhanced Hybrid A* speeds up planning by more than 80%. It also outperforms RL baselines in success rate and trajectory quality, producing shorter trajectories with fewer gear changes, while achieving comparable or lower planning time in most cases.
Scale-Plan: Scalable Language-Enabled Task Planning for Heterogeneous Multi-Robot Teams
Mar 09, 2026Long-horizon task planning for heterogeneous multi-robot systems is essential for deploying collaborative teams in real-world environments; yet, it remains challenging due to the large volume of perceptual information, much of which is irrelevant to task objectives and burdens planning. Traditional symbolic planners rely on manually constructed problem specifications, limiting scalability and adaptability, while recent large language model (LLM)-based approaches often suffer from hallucinations and weak grounding-i.e., poor alignment between generated plans and actual environmental objects and constraints-in object-rich settings. We present Scale-Plan, a scalable LLM-assisted framework that generates compact, task-relevant problem representations from natural language instructions. Given a PDDL domain specification, Scale-Plan constructs an action graph capturing domain structure and uses shallow LLM reasoning to guide a structured graph search that identifies a minimal subset of relevant actions and objects. By filtering irrelevant information prior to planning, Scale-Plan enables efficient decomposition, allocation, and long-horizon plan generation. We evaluate our approach on complex multi-agent tasks and introduce MAT2-THOR, a cleaned benchmark built on AI2-THOR for reliable evaluation of multi-robot planning systems. Scale-Plan outperforms pure LLM and hybrid LLM-PDDL baselines across all metrics, improving scalability and reliability.
Selecting Spots by Explicitly Predicting Intention from Motion History Improves Performance in Autonomous Parking
Mar 05, 2026In many applications of social navigation, existing works have shown that predicting and reasoning about human intentions can help robotic agents make safer and more socially acceptable decisions. In this work, we study this problem for autonomous valet parking (AVP), where an autonomous vehicle ego agent must drop off its passengers, explore the parking lot, find a parking spot, negotiate for the spot with other vehicles, and park in the spot without human supervision. Specifically, we propose an AVP pipeline that selects parking spots by explicitly predicting where other agents are going to park from their motion history using learned models and probabilistic belief maps. To test this pipeline, we build a simulation environment with reactive agents and realistic modeling assumptions on the ego agent, such as occlusion-aware observations, and imperfect trajectory prediction. Simulation experiments show that our proposed method outperforms existing works that infer intentions from future predicted motion or embed them implicitly in end-to-end models, yielding better results in prediction accuracy, social acceptance, and task completion. Our key insight is that, in parking, where driving regulations are more lax, explicit intention prediction is crucial for reasoning about diverse and ambiguous long-term goals, which cannot be reliably inferred from short-term motion prediction alone, but can be effectively learned from motion history.
Adaptive Time Step Flow Matching for Autonomous Driving Motion Planning
Feb 14, 2026Autonomous driving requires reasoning about interactions with surrounding traffic. A prevailing approach is large-scale imitation learning on expert driving datasets, aimed at generalizing across diverse real-world scenarios. For online trajectory generation, such methods must operate at real-time rates. Diffusion models require hundreds of denoising steps at inference, resulting in high latency. Consistency models mitigate this issue but rely on carefully tuned noise schedules to capture the multimodal action distributions common in autonomous driving. Adapting the schedule, typically requires expensive retraining. To address these limitations, we propose a framework based on conditional flow matching that jointly predicts future motions of surrounding agents and plans the ego trajectory in real time. We train a lightweight variance estimator that selects the number of inference steps online, removing the need for retraining to balance runtime and imitation learning performance. To further enhance ride quality, we introduce a trajectory post-processing step cast as a convex quadratic program, with negligible computational overhead. Trained on the Waymo Open Motion Dataset, the framework performs maneuvers such as lane changes, cruise control, and navigating unprotected left turns without requiring scenario-specific tuning. Our method maintains a 20 Hz update rate on an NVIDIA RTX 3070 GPU, making it suitable for online deployment. Compared to transformer, diffusion, and consistency model baselines, we achieve improved trajectory smoothness and better adherence to dynamic constraints. Experiment videos and code implementations can be found at https://flow-matching-self-driving.github.io/.
ONRAP: Occupancy-driven Noise-Resilient Autonomous Path Planning
Feb 14, 2026Dynamic path planning must remain reliable in the presence of sensing noise, uncertain localization, and incomplete semantic perception. We propose a practical, implementation-friendly planner that operates on occupancy grids and optionally incorporates occupancy-flow predictions to generate ego-centric, kinematically feasible paths that safely navigate through static and dynamic obstacles. The core is a nonlinear program in the spatial domain built on a modified bicycle model with explicit feasibility and collision-avoidance penalties. The formulation naturally handles unknown obstacle classes and heterogeneous agent motion by operating purely in occupancy space. The pipeline runs in real-time (faster than 10 Hz on average), requires minimal tuning, and interfaces cleanly with standard control stacks. We validate our approach in simulation with severe localization and perception noises, and on an F1TENTH platform, demonstrating smooth and safe maneuvering through narrow passages and rough routes. The approach provides a robust foundation for noise-resilient, prediction-aware planning, eliminating the need for handcrafted heuristics. The project website can be accessed at https://honda-research-institute.github.io/onrap/
KGLAMP: Knowledge Graph-guided Language model for Adaptive Multi-robot Planning and Replanning
Feb 04, 2026Heterogeneous multi-robot systems are increasingly deployed in long-horizon missions that require coordination among robots with diverse capabilities. However, existing planning approaches struggle to construct accurate symbolic representations and maintain plan consistency in dynamic environments. Classical PDDL planners require manually crafted symbolic models, while LLM-based planners often ignore agent heterogeneity and environmental uncertainty. We introduce KGLAMP, a knowledge-graph-guided LLM planning framework for heterogeneous multi-robot teams. The framework maintains a structured knowledge graph encoding object relations, spatial reachability, and robot capabilities, which guides the LLM in generating accurate PDDL problem specifications. The knowledge graph serves as a persistent, dynamically updated memory that incorporates new observations and triggers replanning upon detecting inconsistencies, enabling symbolic plans to adapt to evolving world states. Experiments on the MAT-THOR benchmark show that KGLAMP improves performance by at least 25.5% over both LLM-only and PDDL-based variants.
Measuring What Matters: Scenario-Driven Evaluation for Trajectory Predictors in Autonomous Driving
Dec 13, 2025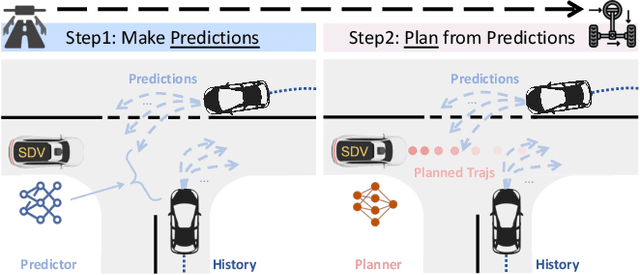
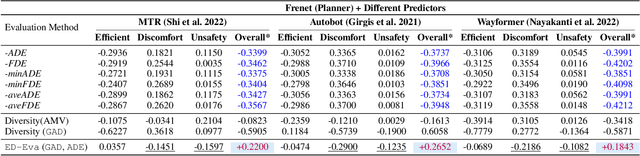
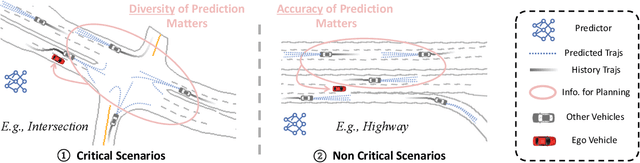
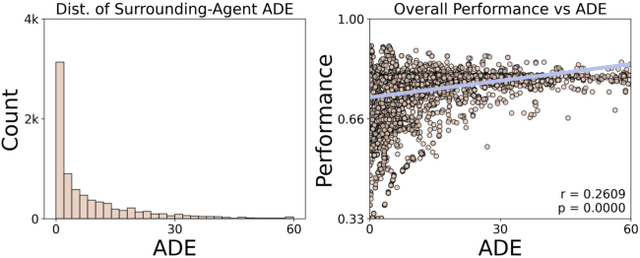
Being able to anticipate the motion of surrounding agents is essential for the safe operation of autonomous driving systems in dynamic situations. While various methods have been proposed for trajectory prediction, the current evaluation practices still rely on error-based metrics (e.g., ADE, FDE), which reveal the accuracy from a post-hoc view but ignore the actual effect the predictor brings to the self-driving vehicles (SDVs), especially in complex interactive scenarios: a high-quality predictor not only chases accuracy, but should also captures all possible directions a neighbor agent might move, to support the SDVs' cautious decision-making. Given that the existing metrics hardly account for this standard, in our work, we propose a comprehensive pipeline that adaptively evaluates the predictor's performance by two dimensions: accuracy and diversity. Based on the criticality of the driving scenario, these two dimensions are dynamically combined and result in a final score for the predictor's performance. Extensive experiments on a closed-loop benchmark using real-world datasets show that our pipeline yields a more reasonable evaluation than traditional metrics by better reflecting the correlation of the predictors' evaluation with the autonomous vehicles' driving performance. This evaluation pipeline shows a robust way to select a predictor that potentially contributes most to the SDV's driving performance.