 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommCP: Efficient Multi-Agent Coordination via LLM-Based Communication with Conformal Prediction
Feb 05, 2026To complete assignments provided by humans in natural language, robots must interpret commands, generate and answer relevant questions for scene understanding, and manipulate target objects. Real-world deployments often require multiple heterogeneous robots with different manipulation capabilities to handle different assignments cooperatively. Beyond the need for specialized manipulation skills, effective information gathering is important in completing these assignments. To address this component of the problem, we formalize the information-gathering process in a fully cooperative setting as an underexplored multi-agent multi-task Embodied Question Answering (MM-EQA) problem, which is a novel extension of canonical Embodied Question Answering (EQA), where effective communication is crucial for coordinating efforts without redundancy. To address this problem, we propose CommCP, a novel LLM-based decentralized communication framework designed for MM-EQA. Our framework employs conformal prediction to calibrate the generated messages, thereby minimizing receiver distractions and enhancing communication reliability. To evaluate our framework, we introduce an MM-EQA benchmark featuring diverse, photo-realistic household scenarios with embodied questions. Experimental results demonstrate that CommCP significantly enhances the task success rate and exploration efficiency over baselines. The experiment videos, code, and dataset are available on our project website: https://comm-cp.github.io.
SDR-CIR: Semantic Debias Retrieval Framework for Training-Free Zero-Shot Composed Image Retrieval
Feb 05, 2026Composed Image Retrieval (CIR) aims to retrieve a target image from a query composed of a reference image and modification text. Recent training-free zero-shot methods often employ Multimodal Large Language Models (MLLMs) with Chain-of-Thought (CoT) to compose a target image description for retrieval. However, due to the fuzzy matching nature of ZS-CIR, the generated description is prone to semantic bias relative to the target image. We propose SDR-CIR, a training-free Semantic Debias Ranking method based on CoT reasoning. First, Selective CoT guides the MLLM to extract visual content relevant to the modification text during image understanding, thereby reducing visual noise at the source. We then introduce a Semantic Debias Ranking with two steps, Anchor and Debias, to mitigate semantic bias. In the Anchor step, we fuse reference image features with target description features to reinforce useful semantics and supplement omitted cues. In the Debias step, we explicitly model the visual semantic contribution of the reference image to the description and incorporate it into the similarity score as a penalty term. By supplementing omitted cues while suppressing redundancy, SDR-CIR mitigates semantic bias and improves retrieval performance. Experiments on three standard CIR benchmarks show that SDR-CIR achieves state-of-the-art results among one-stage methods while maintaining high efficiency. The code is publicly available at https://github.com/suny105/SDR-CIR.
Toward Autonomous Laboratory Safety Monitoring with Vision Language Models: Learning to See Hazards Through Scene Structure
Jan 31, 2026Laboratories are prone to severe injuries from minor unsafe actions, yet continuous safety monitoring -- beyond mandatory pre-lab safety training -- is limited by human availability. Vision language models (VLMs) offer promise for autonomous laboratory safety monitoring, but their effectiveness in realistic settings is unclear due to the lack of visual evaluation data, as most safety incidents are documented primarily as unstructured text. To address this gap, we first introduce a structured data generation pipeline that converts textual laboratory scenarios into aligned triples of (image, scene graph, ground truth), using large language models as scene graph architects and image generation models as renderers. Our experiments on the synthetic dataset of 1,207 samples across 362 unique scenarios and seven open- and closed-source models show that VLMs perform effectively given textual scene graph, but degrade substantially in visual-only settings indicating difficulty in extracting structured object relationships directly from pixels. To overcome this, we propose a post-training context-engineering approach, scene-graph-guided alignment, to bridge perceptual gaps in VLMs by translating visual inputs into structured scene graphs better aligned with VLM reasoning, improving hazard detection performance in visual only settings.
SyncTwin: Fast Digital Twin Construction and Synchronization for Safe Robotic Grasping
Jan 14, 2026Accurate and safe grasping under dynamic and visually occluded conditions remains a core challenge in real-world robotic manipulation. We present SyncTwin, a digital twin framework that unifies fast 3D scene reconstruction and real-to-sim synchronization for robust and safety-aware grasping in such environments. In the offline stage, we employ VGGT to rapidly reconstruct object-level 3D assets from RGB images, forming a reusable geometry library for simulation. During execution, SyncTwin continuously synchronizes the digital twin by tracking real-world object states via point cloud segmentation updates and aligning them through colored-ICP registration. The updated twin enables motion planners to compute collision-free and dynamically feasible trajectories in simulation, which are safely executed on the real robot through a closed real-to-sim-to-real loop. Experiments in dynamic and occluded scenes show that SyncTwin improves grasp accuracy and motion safety, demonstrating the effectiveness of digital-twin synchronization for real-world robotic execution.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
Priority-Aware Multi-Robot Coverage Path Planning
Jan 02, 2026Multi-robot systems are widely used for coverage tasks that require efficient coordination across large environments. In Multi-Robot Coverage Path Planning (MCPP), the objective is typically to minimize the makespan by generating non-overlapping paths for full-area coverage. However, most existing methods assume uniform importance across regions, limiting their effectiveness in scenarios where some zones require faster attention. We introduce the Priority-Aware MCPP (PA-MCPP) problem, where a subset of the environment is designated as prioritized zones with associated weights. The goal is to minimize, in lexicographic order, the total priority-weighted latency of zone coverage and the overall makespan. To address this, we propose a scalable two-phase framework combining (1) greedy zone assignment with local search, spanning-tree-based path planning, and (2) Steiner-tree-guided residual coverage. Experiments across diverse scenarios demonstrate that our method significantly reduces priority-weighted latency compared to standard MCPP baselines, while maintaining competitive makespan. Sensitivity analyses further show that the method scales well with the number of robots and that zone coverage behavior can be effectively controlled by adjusting priority weights.
Natural Geometry of Robust Data Attribution: From Convex Models to Deep Networks
Dec 09, 2025



Data attribution methods identify which training examples are responsible for a model's predictions, but their sensitivity to distributional perturbations undermines practical reliability. We present a unified framework for certified robust attribution that extends from convex models to deep networks. For convex settings, we derive Wasserstein-Robust Influence Functions (W-RIF) with provable coverage guarantees. For deep networks, we demonstrate that Euclidean certification is rendered vacuous by spectral amplification -- a mechanism where the inherent ill-conditioning of deep representations inflates Lipschitz bounds by over $10{,}000\times$. This explains why standard TRAK scores, while accurate point estimates, are geometrically fragile: naive Euclidean robustness analysis yields 0\% certification. Our key contribution is the Natural Wasserstein metric, which measures perturbations in the geometry induced by the model's own feature covariance. This eliminates spectral amplification, reducing worst-case sensitivity by $76\times$ and stabilizing attribution estimates. On CIFAR-10 with ResNet-18, Natural W-TRAK certifies 68.7\% of ranking pairs compared to 0\% for Euclidean baselines -- to our knowledge, the first non-vacuous certified bounds for neural network attribution. Furthermore, we prove that the Self-Influence term arising from our analysis equals the Lipschitz constant governing attribution stability, providing theoretical grounding for leverage-based anomaly detection. Empirically, Self-Influence achieves 0.970 AUROC for label noise detection, identifying 94.1\% of corrupted labels by examining just the top 20\% of training data.
Modality-Aware Bias Mitigation and Invariance Learning for Unsupervised Visible-Infrared Person Re-Identification
Dec 08, 2025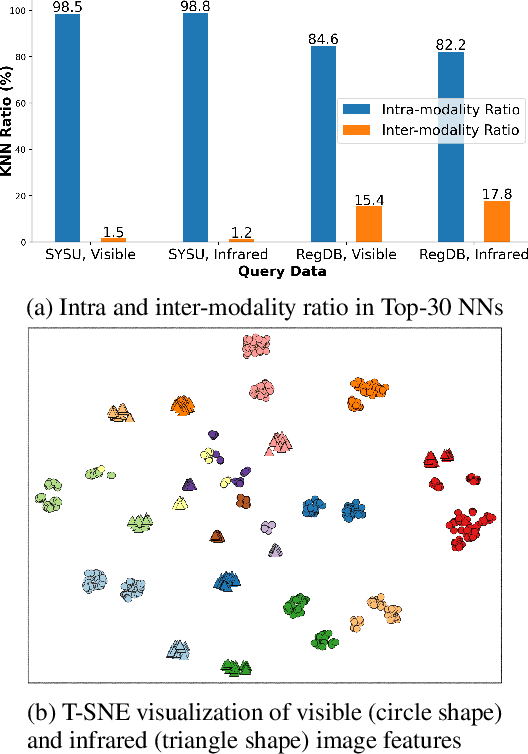
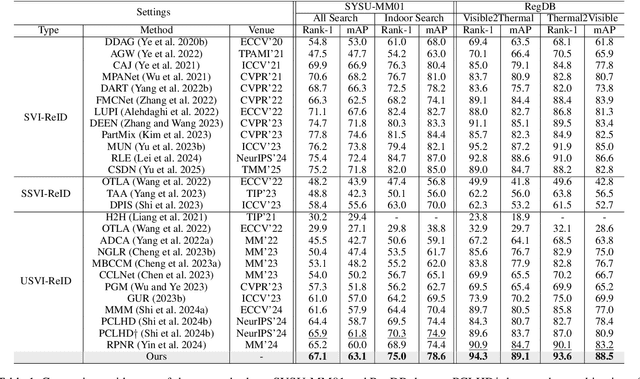
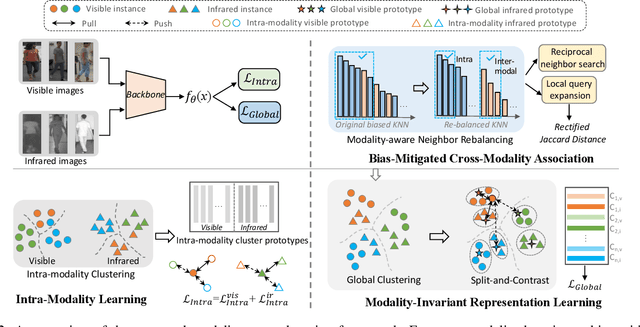
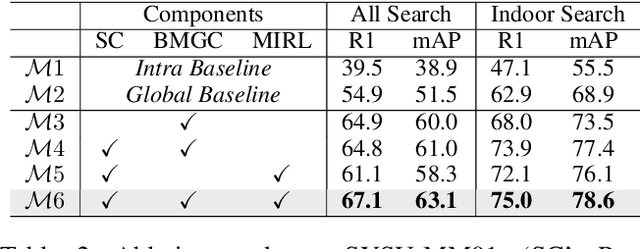
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match individuals across visible and infrared cameras without relying on any annotation. Given the significant gap across visible and infrared modality, estimating reliable cross-modality association becomes a major challenge in USVI-ReID. Existing methods usually adopt optimal transport to associate the intra-modality clusters, which is prone to propagating the local cluster errors, and also overlooks global instance-level relations. By mining and attending to the visible-infrared modality bias, this paper focuses on addressing cross-modality learning from two aspects: bias-mitigated global association and modality-invariant representation learning. Motivated by the camera-aware distance rectification in single-modality re-ID, we propose modality-aware Jaccard distance to mitigate the distance bias caused by modality discrepancy, so that more reliable cross-modality associations can be estimated through global clustering. To further improve cross-modality representation learning, a `split-and-contrast' strategy is designed to obtain modality-specific global prototypes. By explicitly aligning these prototypes under global association guidance, modality-invariant yet ID-discriminative representation learning can be achieved. While conceptually simple, our method obtains state-of-the-art performance on benchmark VI-ReID datasets and outperforms existing methods by a significant margin, validating its effectiveness.
Algorithm-Relative Trajectory Valuation in Policy Gradient Control
Nov 11, 2025We study how trajectory value depends on the learning algorithm in policy-gradient control. Using Trajectory Shapley in an uncertain LQR, we find a negative correlation between Persistence of Excitation (PE) and marginal value under vanilla REINFORCE ($r\approx-0.38$). We prove a variance-mediated mechanism: (i) for fixed energy, higher PE yields lower gradient variance; (ii) near saddles, higher variance increases escape probability, raising marginal contribution. When stabilized (state whitening or Fisher preconditioning), this variance channel is neutralized and information content dominates, flipping the correlation positive ($r\approx+0.29$). Hence, trajectory value is algorithm-relative. Experiments validate the mechanism and show decision-aligned scores (Leave-One-Out) complement Shapley for pruning, while Shapley identifies toxic subsets.
GUIDES: Guidance Using Instructor-Distilled Embeddings for Pre-trained Robot Policy Enhancement
Nov 05, 2025Pre-trained robot policies serve as the foundation of many validated robotic systems, which encapsulate extensive embodied knowledge. However, they often lack the semantic awareness characteristic of foundation models, and replacing them entirely is impractical in many situations due to high costs and the loss of accumulated knowledge. To address this gap, we introduce GUIDES, a lightweight framework that augments pre-trained policies with semantic guidance from foundation models without requiring architectural redesign. GUIDES employs a fine-tuned vision-language model (Instructor) to generate contextual instructions, which are encoded by an auxiliary module into guidance embeddings. These embeddings are injected into the policy's latent space, allowing the legacy model to adapt to this new semantic input through brief, targeted fine-tuning. For inference-time robustness, a large language model-based Reflector monitors the Instructor's confidence and, when confidence is low, initiates a reasoning loop that analyzes execution history, retrieves relevant examples, and augments the VLM's context to refine subsequent actions. Extensive validation in the RoboCasa simulation environment across diverse policy architectures shows consistent and substantial improvements in task success rates. Real-world deployment on a UR5 robot further demonstrates that GUIDES enhances motion precision for critical sub-tasks such as grasping. Overall, GUIDES offers a practical and resource-efficient pathway to upgrade, rather than replace, validated robot policies.