 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
RDD: Retrieval-Based Demonstration Decomposer for Planner Alignment in Long-Horizon Tasks
Oct 16, 2025



To tackle long-horizon tasks, recent hierarchical vision-language-action (VLAs) frameworks employ vision-language model (VLM)-based planners to decompose complex manipulation tasks into simpler sub-tasks that low-level visuomotor policies can easily handle. Typically, the VLM planner is finetuned to learn to decompose a target task. This finetuning requires target task demonstrations segmented into sub-tasks by either human annotation or heuristic rules. However, the heuristic subtasks can deviate significantly from the training data of the visuomotor policy, which degrades task performance. To address these issues, we propose a Retrieval-based Demonstration Decomposer (RDD) that automatically decomposes demonstrations into sub-tasks by aligning the visual features of the decomposed sub-task intervals with those from the training data of the low-level visuomotor policies. Our method outperforms the state-of-the-art sub-task decomposer on both simulation and real-world tasks, demonstrating robustness across diverse settings. Code and more results are available at rdd-neurips.github.io.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
UniOcc: A Unified Benchmark for Occupancy Forecasting and Prediction in Autonomous Driving
Mar 31, 2025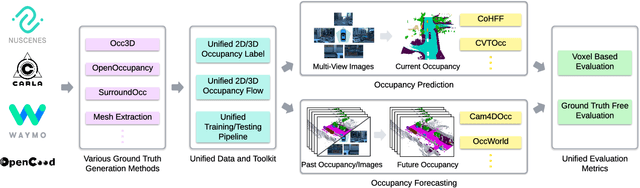

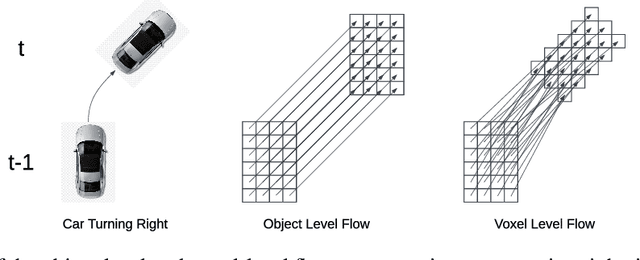
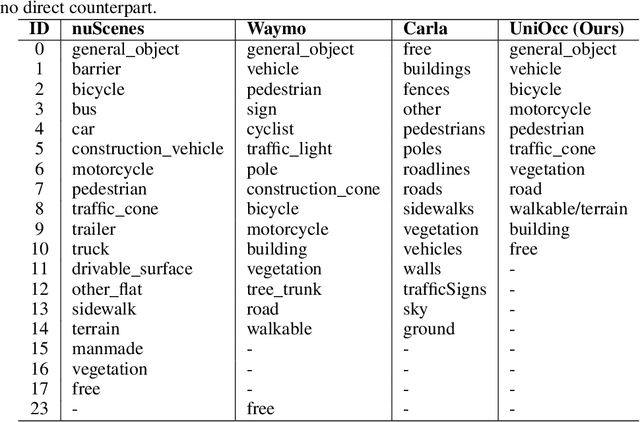
We introduce UniOcc, a comprehensive, unified benchmark for occupancy forecasting (i.e., predicting future occupancies based on historical information) and current-frame occupancy prediction from camera images. UniOcc unifies data from multiple real-world datasets (i.e., nuScenes, Waymo) and high-fidelity driving simulators (i.e., CARLA, OpenCOOD), which provides 2D/3D occupancy labels with per-voxel flow annotations and support for cooperative autonomous driving. In terms of evaluation, unlike existing studies that rely on suboptimal pseudo labels for evaluation, UniOcc incorporates novel metrics that do not depend on ground-truth occupancy, enabling robust assessment of additional aspects of occupancy quality. Through extensive experiments on state-of-the-art models, we demonstrate that large-scale, diverse training data and explicit flow information significantly enhance occupancy prediction and forecasting performance.
DetVPCC: RoI-based Point Cloud Sequence Compression for 3D Object Detection
Feb 07, 2025While MPEG-standardized video-based point cloud compression (VPCC) achieves high compression efficiency for human perception, it struggles with a poor trade-off between bitrate savings and detection accuracy when supporting 3D object detectors. This limitation stems from VPCC's inability to prioritize regions of different importance within point clouds. To address this issue, we propose DetVPCC, a novel method integrating region-of-interest (RoI) encoding with VPCC for efficient point cloud sequence compression while preserving the 3D object detection accuracy. Specifically, we augment VPCC to support RoI-based compression by assigning spatially non-uniform quality levels. Then, we introduce a lightweight RoI detector to identify crucial regions that potentially contain objects. Experiments on the nuScenes dataset demonstrate that our approach significantly improves the detection accuracy. The code and demo video are available in supplementary materials.
Towards Controlled Table-to-Text Generation with Scientific Reasoning
Dec 08, 2023The sheer volume of scientific experimental results and complex technical statements, often presented in tabular formats, presents a formidable barrier to individuals acquiring preferred information. The realms of scientific reasoning and content generation that adhere to user preferences encounter distinct challenges. In this work, we present a new task for generating fluent and logical descriptions that match user preferences over scientific tabular data, aiming to automate scientific document analysis. To facilitate research in this direction, we construct a new challenging dataset CTRLSciTab consisting of table-description pairs extracted from the scientific literature, with highlighted cells and corresponding domain-specific knowledge base. We evaluated popular pre-trained language models to establish a baseline and proposed a novel architecture outperforming competing approaches. The results showed that large models struggle to produce accurate content that aligns with user preferences. As the first of its kind, our work should motivate further research in scientific domains.