 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Jun 12, 2025Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists' First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
Safety-Critical Traffic Simulation with Adversarial Transfer of Driving Intentions
Mar 07, 2025Traffic simulation, complementing real-world data with a long-tail distribution, allows for effective evaluation and enhancement of the ability of autonomous vehicles to handle accident-prone scenarios. Simulating such safety-critical scenarios is nontrivial, however, from log data that are typically regular scenarios, especially in consideration of dynamic adversarial interactions between the future motions of autonomous vehicles and surrounding traffic participants. To address it, this paper proposes an innovative and efficient strategy, termed IntSim, that explicitly decouples the driving intentions of surrounding actors from their motion planning for realistic and efficient safety-critical simulation. We formulate the adversarial transfer of driving intention as an optimization problem, facilitating extensive exploration of diverse attack behaviors and efficient solution convergence. Simultaneously, intention-conditioned motion planning benefits from powerful deep models and large-scale real-world data, permitting the simulation of realistic motion behaviors for actors. Specially, through adapting driving intentions based on environments, IntSim facilitates the flexible realization of dynamic adversarial interactions with autonomous vehicles. Finally, extensive open-loop and closed-loop experiments on real-world datasets, including nuScenes and Waymo, demonstrate that the proposed IntSim achieves state-of-the-art performance in simulating realistic safety-critical scenarios and further improves planners in handling such scenarios.
AMM: Adaptive Modularized Reinforcement Model for Multi-city Traffic Signal Control
Jan 05, 2025



Traffic signal control (TSC) is an important and widely studied direction. Recently, reinforcement learning (RL) methods have been used to solve TSC problems and achieve superior performance over conventional TSC methods. However, applying RL methods to the real world is challenging due to the huge cost of experiments in real-world traffic environments. One possible solution is TSC domain adaptation, which adapts trained models to target environments and reduces the number of interactions and the training cost. However, existing TSC domain adaptation methods still face two major issues: the lack of consideration for differences across cities and the low utilization of multi-city data. To solve aforementioned issues, we propose an approach named Adaptive Modularized Model (AMM). By modularizing TSC problems and network models, we overcome the challenge of possible changes in environmental observations. We also aggregate multi-city experience through meta-learning. We conduct extensive experiments on different cities and show that AMM can achieve excellent performance with limited interactions in target environments and outperform existing methods. We also demonstrate the feasibility and generalizability of our method.
How Much Can Time-related Features Enhance Time Series Forecasting?
Dec 02, 2024



Recent advancements in long-term time series forecasting (LTSF) have primarily focused on capturing cross-time and cross-variate (channel) dependencies within historical data. However, a critical aspect often overlooked by many existing methods is the explicit incorporation of \textbf{time-related features} (e.g., season, month, day of the week, hour, minute), which are essential components of time series data. The absence of this explicit time-related encoding limits the ability of current models to capture cyclical or seasonal trends and long-term dependencies, especially with limited historical input. To address this gap, we introduce a simple yet highly efficient module designed to encode time-related features, Time Stamp Forecaster (TimeSter), thereby enhancing the backbone's forecasting performance. By integrating TimeSter with a linear backbone, our model, TimeLinear, significantly improves the performance of a single linear projector, reducing MSE by an average of 23\% on benchmark datasets such as Electricity and Traffic. Notably, TimeLinear achieves these gains while maintaining exceptional computational efficiency, delivering results that are on par with or exceed state-of-the-art models, despite using a fraction of the parameters.
What can LLM tell us about cities?
Nov 25, 2024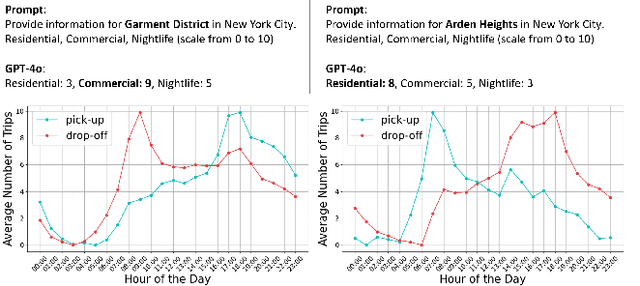
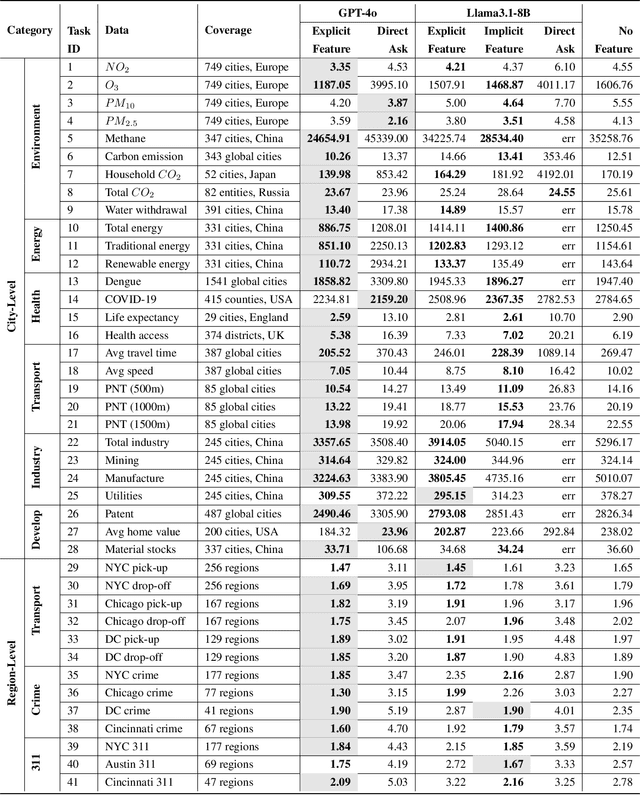
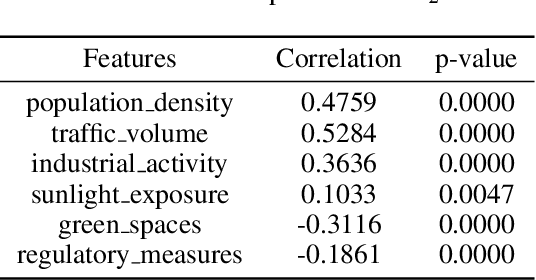
This study explores the capabilities of large language models (LLMs) in providing knowledge about cities and regions on a global scale. We employ two methods: directly querying the LLM for target variable values and extracting explicit and implicit features from the LLM correlated with the target variable. Our experiments reveal that LLMs embed a broad but varying degree of knowledge across global cities, with ML models trained on LLM-derived features consistently leading to improved predictive accuracy. Additionally, we observe that LLMs demonstrate a certain level of knowledge across global cities on all continents, but it is evident when they lack knowledge, as they tend to generate generic or random outputs for unfamiliar tasks. These findings suggest that LLMs can offer new opportunities for data-driven decision-making in the study of cities.
UMGAD: Unsupervised Multiplex Graph Anomaly Detection
Nov 19, 2024



Graph anomaly detection (GAD) is a critical task in graph machine learning, with the primary objective of identifying anomalous nodes that deviate significantly from the majority. This task is widely applied in various real-world scenarios, including fraud detection and social network analysis. However, existing GAD methods still face two major challenges: (1) They are often limited to detecting anomalies in single-type interaction graphs and struggle with multiple interaction types in multiplex heterogeneous graphs; (2) In unsupervised scenarios, selecting appropriate anomaly score thresholds remains a significant challenge for accurate anomaly detection. To address the above challenges, we propose a novel Unsupervised Multiplex Graph Anomaly Detection method, named UMGAD. We first learn multi-relational correlations among nodes in multiplex heterogeneous graphs and capture anomaly information during node attribute and structure reconstruction through graph-masked autoencoder (GMAE). Then, to further weaken the influence of noise and redundant information on abnormal information extraction, we generate attribute-level and subgraph-level augmented-view graphs respectively, and perform attribute and structure reconstruction through GMAE. Finally, We learn to optimize node attributes and structural features through contrastive learning between original-view and augmented-view graphs to improve the model's ability to capture anomalies. Meanwhile, we also propose a new anomaly score threshold selection strategy, which allows the model to be independent of the ground truth in real unsupervised scenarios. Extensive experiments on four datasets show that our \model significantly outperforms state-of-the-art methods, achieving average improvements of 13.48% in AUC and 11.68% in Macro-F1 across all datasets.
MTSCI: A Conditional Diffusion Model for Multivariate Time Series Consistent Imputation
Aug 11, 2024



Missing values are prevalent in multivariate time series, compromising the integrity of analyses and degrading the performance of downstream tasks. Consequently, research has focused on multivariate time series imputation, aiming to accurately impute the missing values based on available observations. A key research question is how to ensure imputation consistency, i.e., intra-consistency between observed and imputed values, and inter-consistency between adjacent windows after imputation. However, previous methods rely solely on the inductive bias of the imputation targets to guide the learning process, ignoring imputation consistency and ultimately resulting in poor performance. Diffusion models, known for their powerful generative abilities, prefer to generate consistent results based on available observations. Therefore, we propose a conditional diffusion model for Multivariate Time Series Consistent Imputation (MTSCI). Specifically, MTSCI employs a contrastive complementary mask to generate dual views during the forward noising process. Then, the intra contrastive loss is calculated to ensure intra-consistency between the imputed and observed values. Meanwhile, MTSCI utilizes a mixup mechanism to incorporate conditional information from adjacent windows during the denoising process, facilitating the inter-consistency between imputed samples. Extensive experiments on multiple real-world datasets demonstrate that our method achieves the state-of-the-art performance on multivariate time series imputation task under different missing scenarios. Code is available at https://github.com/JeremyChou28/MTSCI.
C-Mamba: Channel Correlation Enhanced State Space Models for Multivariate Time Series Forecasting
Jun 08, 2024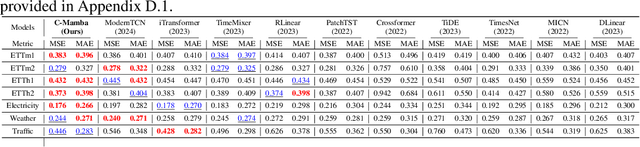

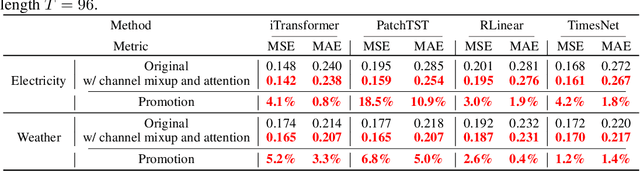

In recent years, significant progress has been made in multivariate time series forecasting using Linear-based, Transformer-based, and Convolution-based models. However, these approaches face notable limitations: linear forecasters struggle with representation capacities, attention mechanisms suffer from quadratic complexity, and convolutional models have a restricted receptive field. These constraints impede their effectiveness in modeling complex time series, particularly those with numerous variables. Additionally, many models adopt the Channel-Independent (CI) strategy, treating multivariate time series as uncorrelated univariate series while ignoring their correlations. For models considering inter-channel relationships, whether through the self-attention mechanism, linear combination, or convolution, they all incur high computational costs and focus solely on weighted summation relationships, neglecting potential proportional relationships between channels. In this work, we address these issues by leveraging the newly introduced state space model and propose \textbf{C-Mamba}, a novel approach that captures cross-channel dependencies while maintaining linear complexity without losing the global receptive field. Our model consists of two key components: (i) channel mixup, where two channels are mixed to enhance the training sets; (ii) channel attention enhanced patch-wise Mamba encoder that leverages the ability of the state space models to capture cross-time dependencies and models correlations between channels by mining their weight relationships. Our model achieves state-of-the-art performance on seven real-world time series datasets. Moreover, the proposed mixup and attention strategy exhibits strong generalizability across other frameworks.
Frequency Enhanced Pre-training for Cross-city Few-shot Traffic Forecasting
Jun 06, 2024



The field of Intelligent Transportation Systems (ITS) relies on accurate traffic forecasting to enable various downstream applications. However, developing cities often face challenges in collecting sufficient training traffic data due to limited resources and outdated infrastructure. Recognizing this obstacle, the concept of cross-city few-shot forecasting has emerged as a viable approach. While previous cross-city few-shot forecasting methods ignore the frequency similarity between cities, we have made an observation that the traffic data is more similar in the frequency domain between cities. Based on this fact, we propose a \textbf{F}requency \textbf{E}nhanced \textbf{P}re-training Framework for \textbf{Cross}-city Few-shot Forecasting (\textbf{FEPCross}). FEPCross has a pre-training stage and a fine-tuning stage. In the pre-training stage, we propose a novel Cross-Domain Spatial-Temporal Encoder that incorporates the information of the time and frequency domain and trains it with self-supervised tasks encompassing reconstruction and contrastive objectives. In the fine-tuning stage, we design modules to enrich training samples and maintain a momentum-updated graph structure, thereby mitigating the risk of overfitting to the few-shot training data. Empirical evaluations performed on real-world traffic datasets validate the exceptional efficacy of FEPCross, outperforming existing approaches of diverse categories and demonstrating characteristics that foster the progress of cross-city few-shot forecasting.
MagiNet: Mask-Aware Graph Imputation Network for Incomplete Traffic Data
Jun 05, 2024



Due to detector malfunctions and communication failures, missing data is ubiquitous during the collection of traffic data. Therefore, it is of vital importance to impute the missing values to facilitate data analysis and decision-making for Intelligent Transportation System (ITS). However, existing imputation methods generally perform zero pre-filling techniques to initialize missing values, introducing inevitable noises. Moreover, we observe prevalent over-smoothing interpolations, falling short in revealing the intrinsic spatio-temporal correlations of incomplete traffic data. To this end, we propose Mask-Aware Graph imputation Network: MagiNet. Our method designs an adaptive mask spatio-temporal encoder to learn the latent representations of incomplete data, eliminating the reliance on pre-filling missing values. Furthermore, we devise a spatio-temporal decoder that stacks multiple blocks to capture the inherent spatial and temporal dependencies within incomplete traffic data, alleviating over-smoothing imputation. Extensive experiments demonstrate that our method outperforms state-of-the-art imputation methods on five real-world traffic datasets, yielding an average improvement of 4.31% in RMSE and 3.72% in MAPE.