 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuSpeech: Silent Thought, Spoken Answer via Unified Speech-Text Diffusion
Jan 30, 2026Current speech language models generate responses directly without explicit reasoning, leading to errors that cannot be corrected once audio is produced. We introduce \textbf{``Silent Thought, Spoken Answer''} -- a paradigm where speech LLMs generate internal text reasoning alongside spoken responses, with thinking traces informing speech quality. To realize this, we present \method{}, the first diffusion-based speech-text language model supporting both understanding and generation, unifying discrete text and tokenized speech under a single masked diffusion framework. Unlike autoregressive approaches, \method{} jointly generates reasoning traces and speech tokens through iterative denoising, with modality-specific masking schedules. We also construct \dataset{}, the first speech QA dataset with paired text reasoning traces, containing 26K samples totaling 319 hours. Experiments show \method{} achieves state-of-the-art speech-to-speech QA accuracy, outperforming the best baseline by up to 9 points, while attaining the best TTS quality among generative models (6.2\% WER) and preserving language understanding (66.2\% MMLU). Ablations confirm that both the diffusion architecture and thinking traces contribute to these gains.
What can LLM tell us about cities?
Nov 25, 2024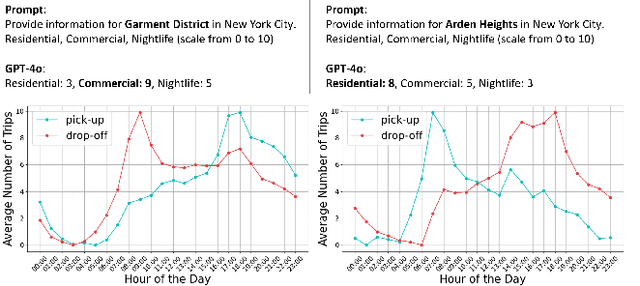
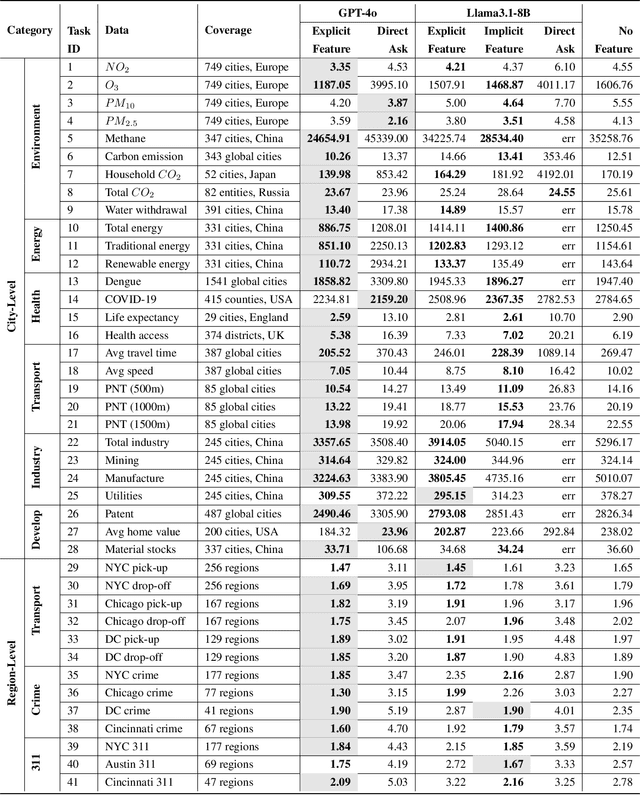
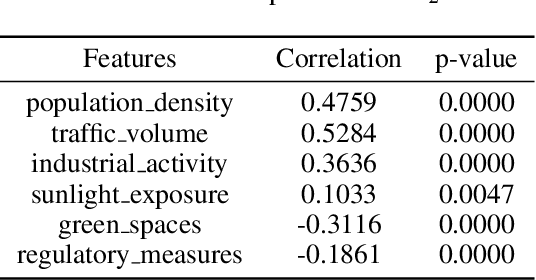
This study explores the capabilities of large language models (LLMs) in providing knowledge about cities and regions on a global scale. We employ two methods: directly querying the LLM for target variable values and extracting explicit and implicit features from the LLM correlated with the target variable. Our experiments reveal that LLMs embed a broad but varying degree of knowledge across global cities, with ML models trained on LLM-derived features consistently leading to improved predictive accuracy. Additionally, we observe that LLMs demonstrate a certain level of knowledge across global cities on all continents, but it is evident when they lack knowledge, as they tend to generate generic or random outputs for unfamiliar tasks. These findings suggest that LLMs can offer new opportunities for data-driven decision-making in the study of cities.
MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark
Feb 07, 2024Multimodal Large Language Models (MLLMs) have gained significant attention recently, showing remarkable potential in artificial general intelligence. However, assessing the utility of MLLMs presents considerable challenges, primarily due to the absence multimodal benchmarks that align with human preferences. Inspired by LLM-as-a-Judge in LLMs, this paper introduces a novel benchmark, termed MLLM-as-a-Judge, to assess the ability of MLLMs in assisting judges including three distinct tasks: Scoring Evaluation, Pair Comparison, and Batch Ranking. Our study reveals that, while MLLMs demonstrate remarkable human-like discernment in Pair Comparisons, there is a significant divergence from human preferences in Scoring Evaluation and Batch Ranking tasks. Furthermore, MLLMs still face challenges in judgment, including diverse biases, hallucinatory responses, and inconsistencies, even for advanced models such as GPT-4V. These findings emphasize the pressing need for enhancements and further research efforts regarding MLLMs as fully reliable evaluators. Code and dataset are available at https://github.com/Dongping-Chen/MLLM-as-a-Judge.