 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELP: HyperNode Expansion and Logical Path-Guided Evidence Localization for Accurate and Efficient GraphRAG
Feb 24, 2026Large Language Models (LLMs) often struggle with inherent knowledge boundaries and hallucinations, limiting their reliability in knowledge-intensive tasks. While Retrieval-Augmented Generation (RAG) mitigates these issues, it frequently overlooks structural interdependencies essential for multi-hop reasoning. Graph-based RAG approaches attempt to bridge this gap, yet they typically face trade-offs between accuracy and efficiency due to challenges such as costly graph traversals and semantic noise in LLM-generated summaries. In this paper, we propose HyperNode Expansion and Logical Path-Guided Evidence Localization strategies for GraphRAG (HELP), a novel framework designed to balance accuracy with practical efficiency through two core strategies: 1) HyperNode Expansion, which iteratively chains knowledge triplets into coherent reasoning paths abstracted as HyperNodes to capture complex structural dependencies and ensure retrieval accuracy; and 2) Logical Path-Guided Evidence Localization, which leverages precomputed graph-text correlations to map these paths directly to the corpus for superior efficiency. HELP avoids expensive random walks and semantic distortion, preserving knowledge integrity while drastically reducing retrieval latency. Extensive experiments demonstrate that HELP achieves competitive performance across multiple simple and multi-hop QA benchmarks and up to a 28.8$\times$ speedup over leading Graph-based RAG baselines.
REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents
Feb 15, 2026Large language models are transitioning from generalpurpose knowledge engines to realworld problem solvers, yet optimizing them for deep search tasks remains challenging. The central bottleneck lies in the extreme sparsity of highquality search trajectories and reward signals, arising from the difficulty of scalable longhorizon task construction and the high cost of interactionheavy rollouts involving external tool calls. To address these challenges, we propose REDSearcher, a unified framework that codesigns complex task synthesis, midtraining, and posttraining for scalable searchagent optimization. Specifically, REDSearcher introduces the following improvements: (1) We frame task synthesis as a dualconstrained optimization, where task difficulty is precisely governed by graph topology and evidence dispersion, allowing scalable generation of complex, highquality tasks. (2) We introduce toolaugmented queries to encourage proactive tool use rather than passive recall.(3) During midtraining, we strengthen core atomic capabilities knowledge, planning, and function calling substantially reducing the cost of collecting highquality trajectories for downstream training. (4) We build a local simulated environment that enables rapid, lowcost algorithmic iteration for reinforcement learning experiments. Across both textonly and multimodal searchagent benchmarks, our approach achieves stateoftheart performance. To facilitate future research on longhorizon search agents, we will release 10K highquality complex text search trajectories, 5K multimodal trajectories and 1K text RL query set, and together with code and model checkpoints.
Quantum-Enhanced Neural Contextual Bandit Algorithms
Jan 06, 2026Stochastic contextual bandits are fundamental for sequential decision-making but pose significant challenges for existing neural network-based algorithms, particularly when scaling to quantum neural networks (QNNs) due to issues such as massive over-parameterization, computational instability, and the barren plateau phenomenon. This paper introduces the Quantum Neural Tangent Kernel-Upper Confidence Bound (QNTK-UCB) algorithm, a novel algorithm that leverages the Quantum Neural Tangent Kernel (QNTK) to address these limitations. By freezing the QNN at a random initialization and utilizing its static QNTK as a kernel for ridge regression, QNTK-UCB bypasses the unstable training dynamics inherent in explicit parameterized quantum circuit training while fully exploiting the unique quantum inductive bias. For a time horizon $T$ and $K$ actions, our theoretical analysis reveals a significantly improved parameter scaling of $Ω((TK)^3)$ for QNTK-UCB, a substantial reduction compared to $Ω((TK)^8)$ required by classical NeuralUCB algorithms for similar regret guarantees. Empirical evaluations on non-linear synthetic benchmarks and quantum-native variational quantum eigensolver tasks demonstrate QNTK-UCB's superior sample efficiency in low-data regimes. This work highlights how the inherent properties of QNTK provide implicit regularization and a sharper spectral decay, paving the way for achieving ``quantum advantage'' in online learning.
Scale-Aware Relay and Scale-Adaptive Loss for Tiny Object Detection in Aerial Images
Nov 13, 2025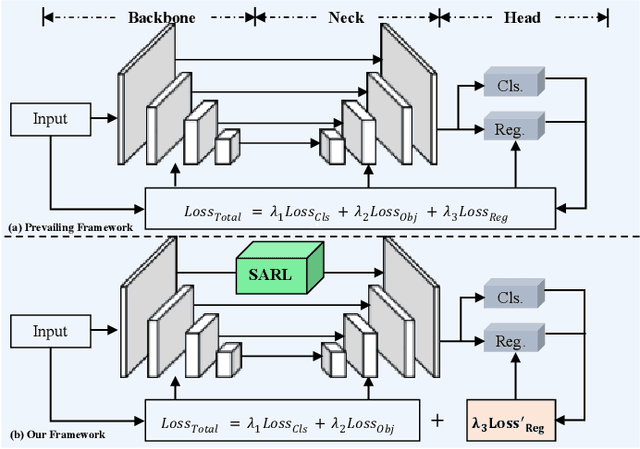
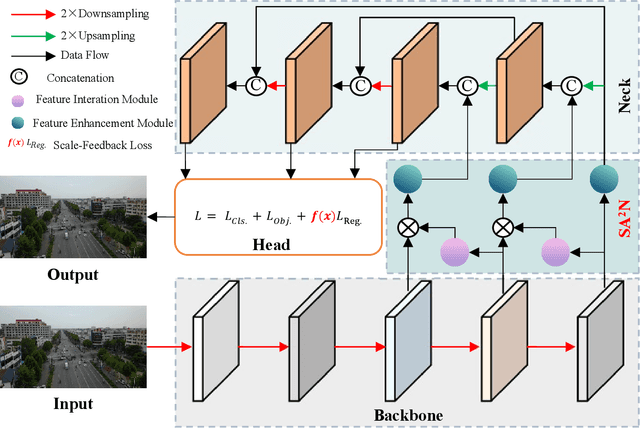
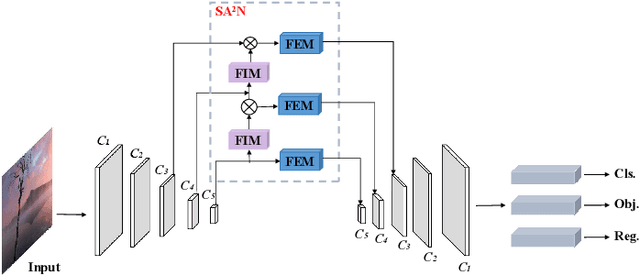
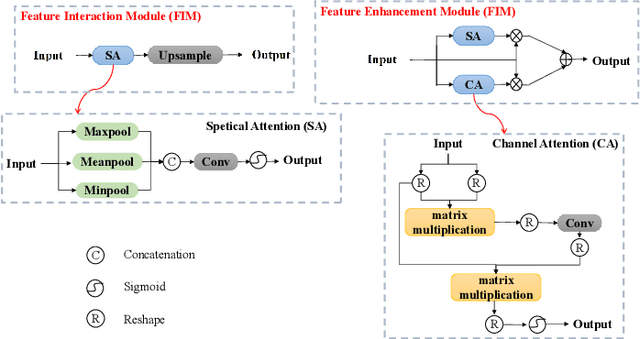
Recently, despite the remarkable advancements in object detection, modern detectors still struggle to detect tiny objects in aerial images. One key reason is that tiny objects carry limited features that are inevitably degraded or lost during long-distance network propagation. Another is that smaller objects receive disproportionately greater regression penalties than larger ones during training. To tackle these issues, we propose a Scale-Aware Relay Layer (SARL) and a Scale-Adaptive Loss (SAL) for tiny object detection, both of which are seamlessly compatible with the top-performing frameworks. Specifically, SARL employs a cross-scale spatial-channel attention to progressively enrich the meaningful features of each layer and strengthen the cross-layer feature sharing. SAL reshapes the vanilla IoU-based losses so as to dynamically assign lower weights to larger objects. This loss is able to focus training on tiny objects while reducing the influence on large objects. Extensive experiments are conducted on three benchmarks (\textit{i.e.,} AI-TOD, DOTA-v2.0 and VisDrone2019), and the results demonstrate that the proposed method boosts the generalization ability by 5.5\% Average Precision (AP) when embedded in YOLOv5 (anchor-based) and YOLOx (anchor-free) baselines. Moreover, it also promotes the robust performance with 29.0\% AP on the real-world noisy dataset (\textit{i.e.,} AI-TOD-v2.0).
DualDiff: Dual-branch Diffusion Model for Autonomous Driving with Semantic Fusion
May 03, 2025Accurate and high-fidelity driving scene reconstruction relies on fully leveraging scene information as conditioning. However, existing approaches, which primarily use 3D bounding boxes and binary maps for foreground and background control, fall short in capturing the complexity of the scene and integrating multi-modal information. In this paper, we propose DualDiff, a dual-branch conditional diffusion model designed to enhance multi-view driving scene generation. We introduce Occupancy Ray Sampling (ORS), a semantic-rich 3D representation, alongside numerical driving scene representation, for comprehensive foreground and background control. To improve cross-modal information integration, we propose a Semantic Fusion Attention (SFA) mechanism that aligns and fuses features across modalities. Furthermore, we design a foreground-aware masked (FGM) loss to enhance the generation of tiny objects. DualDiff achieves state-of-the-art performance in FID score, as well as consistently better results in downstream BEV segmentation and 3D object detection tasks.
What can LLM tell us about cities?
Nov 25, 2024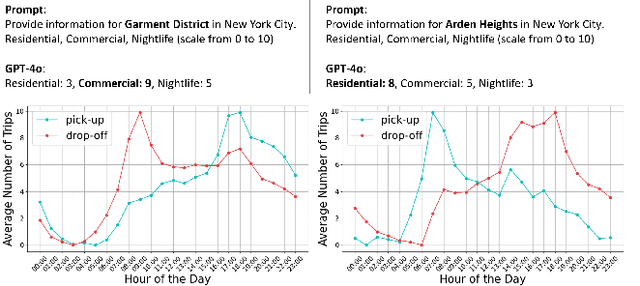
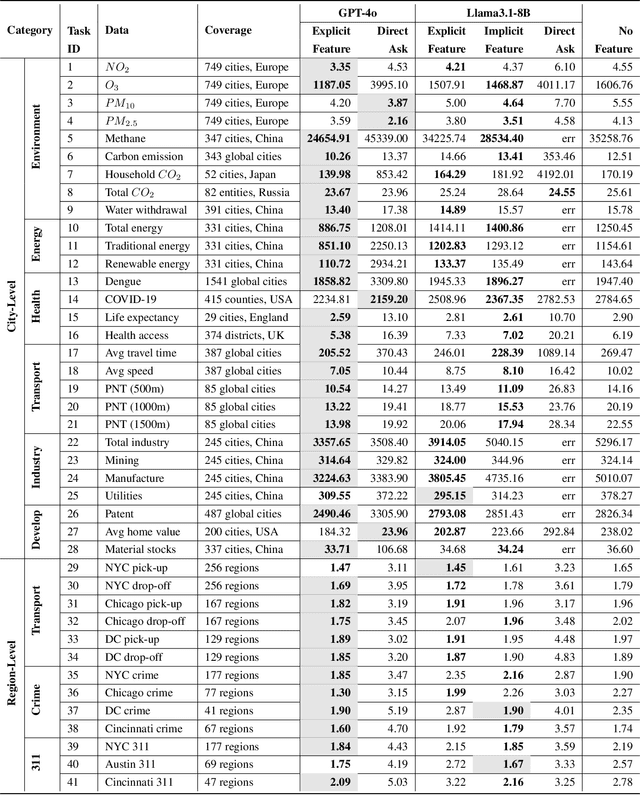
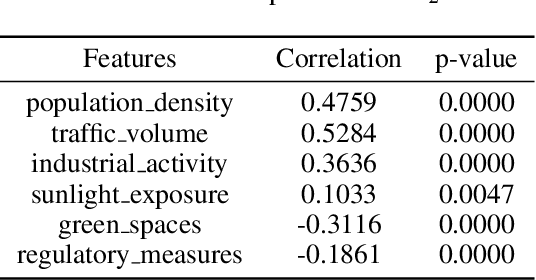
This study explores the capabilities of large language models (LLMs) in providing knowledge about cities and regions on a global scale. We employ two methods: directly querying the LLM for target variable values and extracting explicit and implicit features from the LLM correlated with the target variable. Our experiments reveal that LLMs embed a broad but varying degree of knowledge across global cities, with ML models trained on LLM-derived features consistently leading to improved predictive accuracy. Additionally, we observe that LLMs demonstrate a certain level of knowledge across global cities on all continents, but it is evident when they lack knowledge, as they tend to generate generic or random outputs for unfamiliar tasks. These findings suggest that LLMs can offer new opportunities for data-driven decision-making in the study of cities.
A General Framework for Clustering and Distribution Matching with Bandit Feedback
Sep 08, 2024



We develop a general framework for clustering and distribution matching problems with bandit feedback. We consider a $K$-armed bandit model where some subset of $K$ arms is partitioned into $M$ groups. Within each group, the random variable associated to each arm follows the same distribution on a finite alphabet. At each time step, the decision maker pulls an arm and observes its outcome from the random variable associated to that arm. Subsequent arm pulls depend on the history of arm pulls and their outcomes. The decision maker has no knowledge of the distributions of the arms or the underlying partitions. The task is to devise an online algorithm to learn the underlying partition of arms with the least number of arm pulls on average and with an error probability not exceeding a pre-determined value $\delta$. Several existing problems fall under our general framework, including finding $M$ pairs of arms, odd arm identification, and $M$-ary clustering of $K$ arms belong to our general framework. We derive a non-asymptotic lower bound on the average number of arm pulls for any online algorithm with an error probability not exceeding $\delta$. Furthermore, we develop a computationally-efficient online algorithm based on the Track-and-Stop method and Frank--Wolfe algorithm, and show that the average number of arm pulls of our algorithm asymptotically matches that of the lower bound. Our refined analysis also uncovers a novel bound on the speed at which the average number of arm pulls of our algorithm converges to the fundamental limit as $\delta$ vanishes.
GazeReader: Detecting Unknown Word Using Webcam for English as a Second Language (ESL) Learners
Mar 18, 2023Automatic unknown word detection techniques can enable new applications for assisting English as a Second Language (ESL) learners, thus improving their reading experiences. However, most modern unknown word detection methods require dedicated eye-tracking devices with high precision that are not easily accessible to end-users. In this work, we propose GazeReader, an unknown word detection method only using a webcam. GazeReader tracks the learner's gaze and then applies a transformer-based machine learning model that encodes the text information to locate the unknown word. We applied knowledge enhancement including term frequency, part of speech, and named entity recognition to improve the performance. The user study indicates that the accuracy and F1-score of our method were 98.09% and 75.73%, respectively. Lastly, we explored the design scope for ESL reading and discussed the findings.