 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe.FM: Open Foundation Models for Human Behavior
May 29, 2025



Despite their success in numerous fields, the potential of foundation models for modeling and understanding human behavior remains largely unexplored. We introduce Be.FM, one of the first open foundation models designed for human behavior modeling. Built upon open-source large language models and fine-tuned on a diverse range of behavioral data, Be.FM can be used to understand and predict human decision-making. We construct a comprehensive set of benchmark tasks for testing the capabilities of behavioral foundation models. Our results demonstrate that Be.FM can predict behaviors, infer characteristics of individuals and populations, generate insights about contexts, and apply behavioral science knowledge.
Generative AI in Transportation Planning: A Survey
Mar 10, 2025

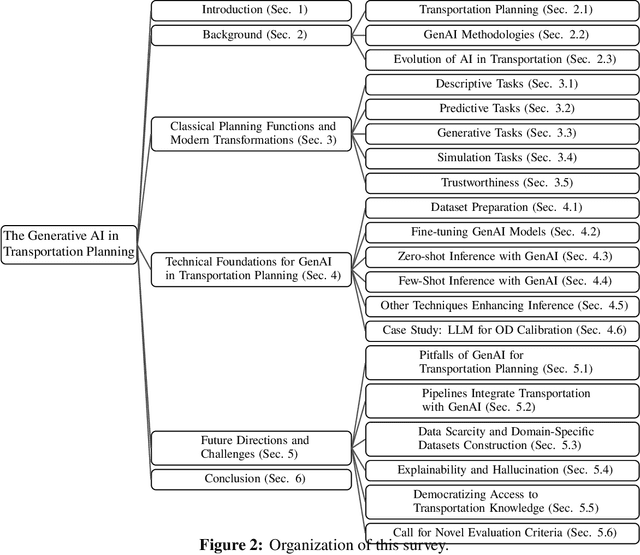
The integration of generative artificial intelligence (GenAI) into transportation planning has the potential to revolutionize tasks such as demand forecasting, infrastructure design, policy evaluation, and traffic simulation. However, there is a critical need for a systematic framework to guide the adoption of GenAI in this interdisciplinary domain. In this survey, we, a multidisciplinary team of researchers spanning computer science and transportation engineering, present the first comprehensive framework for leveraging GenAI in transportation planning. Specifically, we introduce a new taxonomy that categorizes existing applications and methodologies into two perspectives: transportation planning tasks and computational techniques. From the transportation planning perspective, we examine the role of GenAI in automating descriptive, predictive, generative, simulation, and explainable tasks to enhance mobility systems. From the computational perspective, we detail advancements in data preparation, domain-specific fine-tuning, and inference strategies, such as retrieval-augmented generation and zero-shot learning tailored to transportation applications. Additionally, we address critical challenges, including data scarcity, explainability, bias mitigation, and the development of domain-specific evaluation frameworks that align with transportation goals like sustainability, equity, and system efficiency. This survey aims to bridge the gap between traditional transportation planning methodologies and modern AI techniques, fostering collaboration and innovation. By addressing these challenges and opportunities, we seek to inspire future research that ensures ethical, equitable, and impactful use of generative AI in transportation planning.
HumanMM: Global Human Motion Recovery from Multi-shot Videos
Mar 10, 2025In this paper, we present a novel framework designed to reconstruct long-sequence 3D human motion in the world coordinates from in-the-wild videos with multiple shot transitions. Such long-sequence in-the-wild motions are highly valuable to applications such as motion generation and motion understanding, but are of great challenge to be recovered due to abrupt shot transitions, partial occlusions, and dynamic backgrounds presented in such videos. Existing methods primarily focus on single-shot videos, where continuity is maintained within a single camera view, or simplify multi-shot alignment in camera space only. In this work, we tackle the challenges by integrating an enhanced camera pose estimation with Human Motion Recovery (HMR) by incorporating a shot transition detector and a robust alignment module for accurate pose and orientation continuity across shots. By leveraging a custom motion integrator, we effectively mitigate the problem of foot sliding and ensure temporal consistency in human pose. Extensive evaluations on our created multi-shot dataset from public 3D human datasets demonstrate the robustness of our method in reconstructing realistic human motion in world coordinates.
Accounting for Focus Ambiguity in Visual Questions
Jan 04, 2025



No existing work on visual question answering explicitly accounts for ambiguity regarding where the content described in the question is located in the image. To fill this gap, we introduce VQ-FocusAmbiguity, the first VQA dataset that visually grounds each region described in the question that is necessary to arrive at the answer. We then provide an analysis showing how our dataset for visually grounding `questions' is distinct from visually grounding `answers', and characterize the properties of the questions and segmentations provided in our dataset. Finally, we benchmark modern models for two novel tasks: recognizing whether a visual question has focus ambiguity and localizing all plausible focus regions within the image. Results show that the dataset is challenging for modern models. To facilitate future progress on these tasks, we publicly share the dataset with an evaluation server at https://focusambiguity.github.io/.
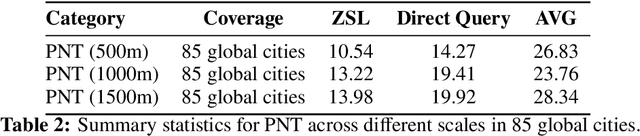
What can LLM tell us about cities?
Nov 25, 2024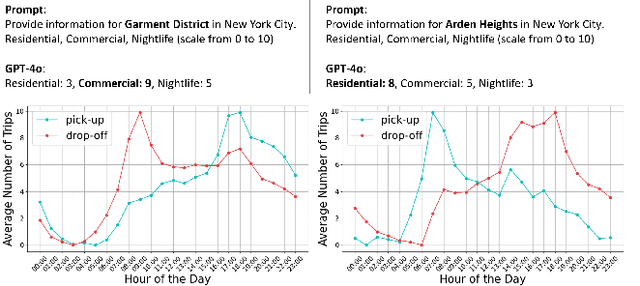
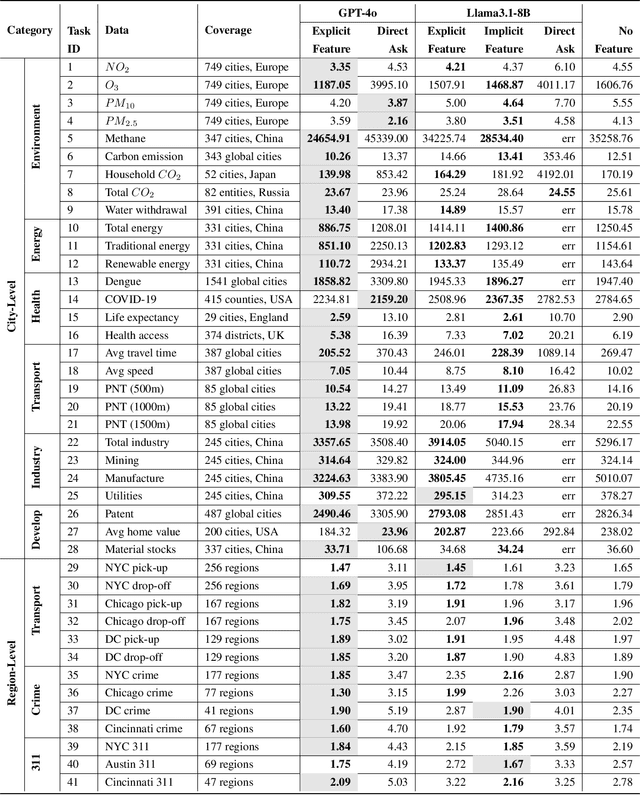
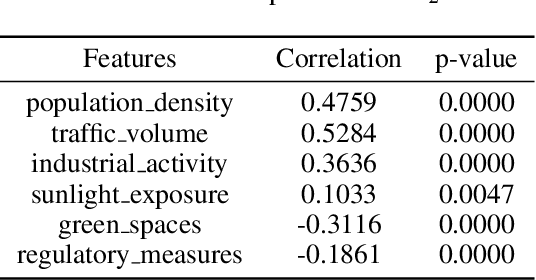
This study explores the capabilities of large language models (LLMs) in providing knowledge about cities and regions on a global scale. We employ two methods: directly querying the LLM for target variable values and extracting explicit and implicit features from the LLM correlated with the target variable. Our experiments reveal that LLMs embed a broad but varying degree of knowledge across global cities, with ML models trained on LLM-derived features consistently leading to improved predictive accuracy. Additionally, we observe that LLMs demonstrate a certain level of knowledge across global cities on all continents, but it is evident when they lack knowledge, as they tend to generate generic or random outputs for unfamiliar tasks. These findings suggest that LLMs can offer new opportunities for data-driven decision-making in the study of cities.
A Survey of AI-Generated Video Evaluation
Oct 24, 2024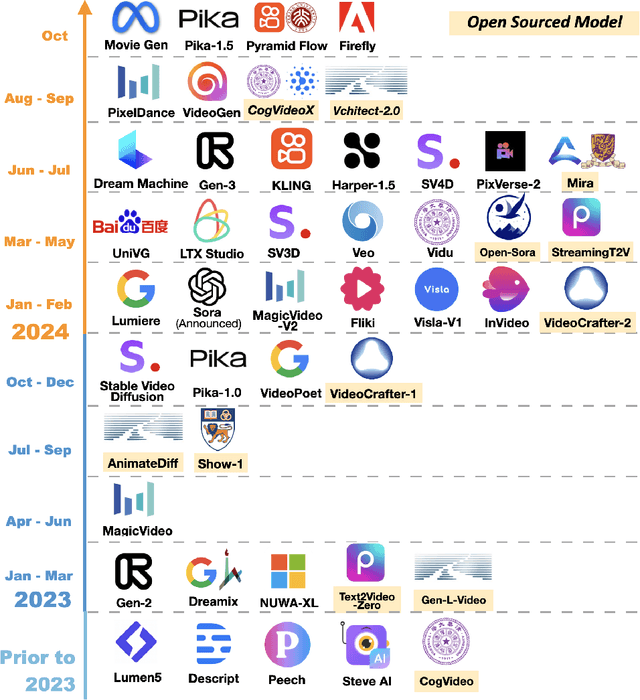
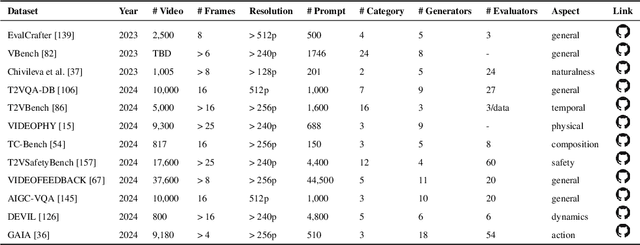

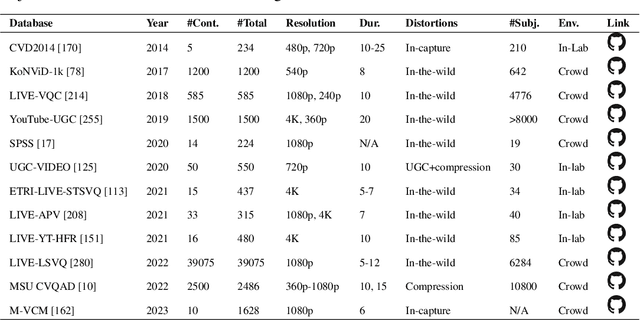
The growing capabilities of AI in generating video content have brought forward significant challenges in effectively evaluating these videos. Unlike static images or text, video content involves complex spatial and temporal dynamics which may require a more comprehensive and systematic evaluation of its contents in aspects like video presentation quality, semantic information delivery, alignment with human intentions, and the virtual-reality consistency with our physical world. This survey identifies the emerging field of AI-Generated Video Evaluation (AIGVE), highlighting the importance of assessing how well AI-generated videos align with human perception and meet specific instructions. We provide a structured analysis of existing methodologies that could be potentially used to evaluate AI-generated videos. By outlining the strengths and gaps in current approaches, we advocate for the development of more robust and nuanced evaluation frameworks that can handle the complexities of video content, which include not only the conventional metric-based evaluations, but also the current human-involved evaluations, and the future model-centered evaluations. This survey aims to establish a foundational knowledge base for both researchers from academia and practitioners from the industry, facilitating the future advancement of evaluation methods for AI-generated video content.
DARK: Denoising, Amplification, Restoration Kit
May 21, 2024



This paper introduces a novel lightweight computational framework for enhancing images under low-light conditions, utilizing advanced machine learning and convolutional neural networks (CNNs). Traditional enhancement techniques often fail to adequately address issues like noise, color distortion, and detail loss in challenging lighting environments. Our approach leverages insights from the Retinex theory and recent advances in image restoration networks to develop a streamlined model that efficiently processes illumination components and integrates context-sensitive enhancements through optimized convolutional blocks. This results in significantly improved image clarity and color fidelity, while avoiding over-enhancement and unnatural color shifts. Crucially, our model is designed to be lightweight, ensuring low computational demand and suitability for real-time applications on standard consumer hardware. Performance evaluations confirm that our model not only surpasses existing methods in enhancing low-light images but also maintains a minimal computational footprint.