 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoca-Splat: Collaborative Optimization for Camera Parameters and 3D Gaussians
Apr 01, 2025In this work, we introduce Coca-Splat, a novel approach to addressing the challenges of sparse view pose-free scene reconstruction and novel view synthesis (NVS) by jointly optimizing camera parameters with 3D Gaussians. Inspired by deformable DEtection TRansformer, we design separate queries for 3D Gaussians and camera parameters and update them layer by layer through deformable Transformer layers, enabling joint optimization in a single network. This design demonstrates better performance because to accurately render views that closely approximate ground-truth images relies on precise estimation of both 3D Gaussians and camera parameters. In such a design, the centers of 3D Gaussians are projected onto each view by camera parameters to get projected points, which are regarded as 2D reference points in deformable cross-attention. With camera-aware multi-view deformable cross-attention (CaMDFA), 3D Gaussians and camera parameters are intrinsically connected by sharing the 2D reference points. Additionally, 2D reference point determined rays (RayRef) defined from camera centers to the reference points assist in modeling relationship between 3D Gaussians and camera parameters through RQ-decomposition on an overdetermined system of equations derived from the rays, enhancing the relationship between 3D Gaussians and camera parameters. Extensive evaluation shows that our approach outperforms previous methods, both pose-required and pose-free, on RealEstate10K and ACID within the same pose-free setting.
HumanMM: Global Human Motion Recovery from Multi-shot Videos
Mar 10, 2025In this paper, we present a novel framework designed to reconstruct long-sequence 3D human motion in the world coordinates from in-the-wild videos with multiple shot transitions. Such long-sequence in-the-wild motions are highly valuable to applications such as motion generation and motion understanding, but are of great challenge to be recovered due to abrupt shot transitions, partial occlusions, and dynamic backgrounds presented in such videos. Existing methods primarily focus on single-shot videos, where continuity is maintained within a single camera view, or simplify multi-shot alignment in camera space only. In this work, we tackle the challenges by integrating an enhanced camera pose estimation with Human Motion Recovery (HMR) by incorporating a shot transition detector and a robust alignment module for accurate pose and orientation continuity across shots. By leveraging a custom motion integrator, we effectively mitigate the problem of foot sliding and ensure temporal consistency in human pose. Extensive evaluations on our created multi-shot dataset from public 3D human datasets demonstrate the robustness of our method in reconstructing realistic human motion in world coordinates.
HandOS: 3D Hand Reconstruction in One Stage
Dec 02, 2024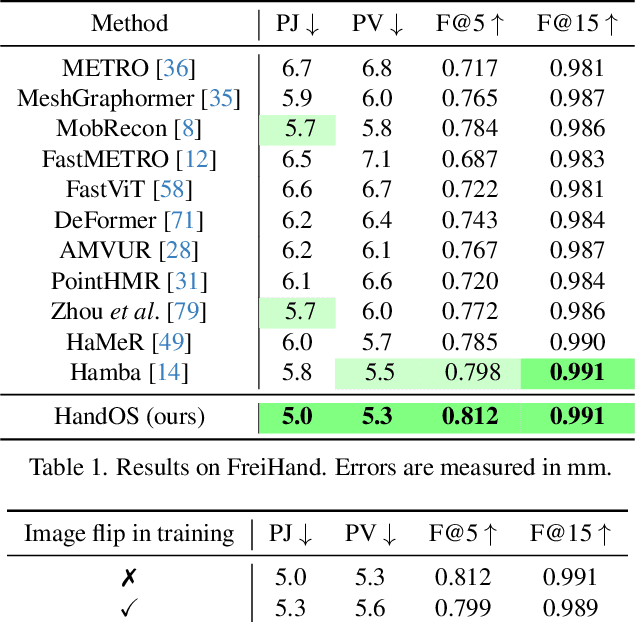
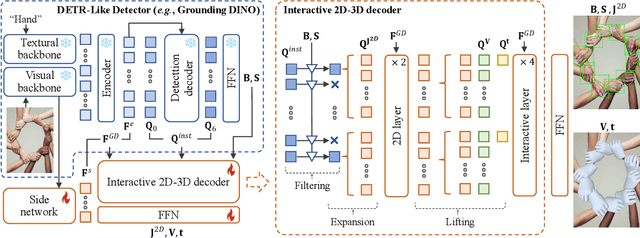
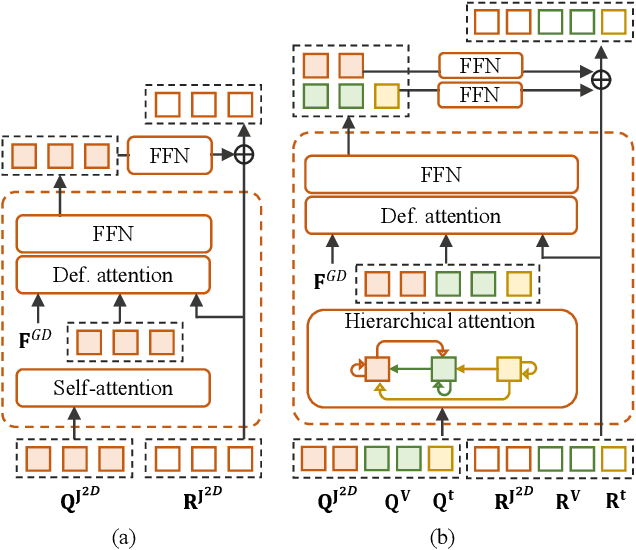
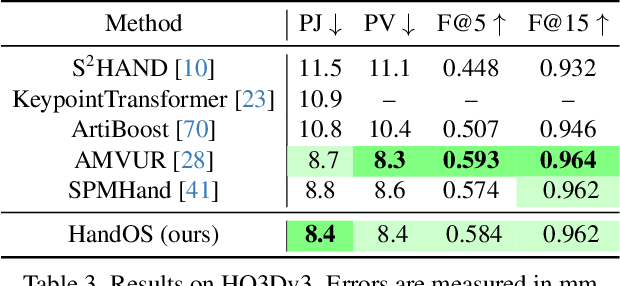
Existing approaches of hand reconstruction predominantly adhere to a multi-stage framework, encompassing detection, left-right classification, and pose estimation. This paradigm induces redundant computation and cumulative errors. In this work, we propose HandOS, an end-to-end framework for 3D hand reconstruction. Our central motivation lies in leveraging a frozen detector as the foundation while incorporating auxiliary modules for 2D and 3D keypoint estimation. In this manner, we integrate the pose estimation capacity into the detection framework, while at the same time obviating the necessity of using the left-right category as a prerequisite. Specifically, we propose an interactive 2D-3D decoder, where 2D joint semantics is derived from detection cues while 3D representation is lifted from those of 2D joints. Furthermore, hierarchical attention is designed to enable the concurrent modeling of 2D joints, 3D vertices, and camera translation. Consequently, we achieve an end-to-end integration of hand detection, 2D pose estimation, and 3D mesh reconstruction within a one-stage framework, so that the above multi-stage drawbacks are overcome. Meanwhile, the HandOS reaches state-of-the-art performances on public benchmarks, e.g., 5.0 PA-MPJPE on FreiHand and 64.6\% PCK@0.05 on HInt-Ego4D. Project page: idea-research.github.io/HandOSweb.
DINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
Nov 21, 2024



In this paper, we introduce DINO-X, which is a unified object-centric vision model developed by IDEA Research with the best open-world object detection performance to date. DINO-X employs the same Transformer-based encoder-decoder architecture as Grounding DINO 1.5 to pursue an object-level representation for open-world object understanding. To make long-tailed object detection easy, DINO-X extends its input options to support text prompt, visual prompt, and customized prompt. With such flexible prompt options, we develop a universal object prompt to support prompt-free open-world detection, making it possible to detect anything in an image without requiring users to provide any prompt. To enhance the model's core grounding capability, we have constructed a large-scale dataset with over 100 million high-quality grounding samples, referred to as Grounding-100M, for advancing the model's open-vocabulary detection performance. Pre-training on such a large-scale grounding dataset leads to a foundational object-level representation, which enables DINO-X to integrate multiple perception heads to simultaneously support multiple object perception and understanding tasks, including detection, segmentation, pose estimation, object captioning, object-based QA, etc. Experimental results demonstrate the superior performance of DINO-X. Specifically, the DINO-X Pro model achieves 56.0 AP, 59.8 AP, and 52.4 AP on the COCO, LVIS-minival, and LVIS-val zero-shot object detection benchmarks, respectively. Notably, it scores 63.3 AP and 56.5 AP on the rare classes of LVIS-minival and LVIS-val benchmarks, both improving the previous SOTA performance by 5.8 AP. Such a result underscores its significantly improved capacity for recognizing long-tailed objects.
UniG: Modelling Unitary 3D Gaussians for View-consistent 3D Reconstruction
Oct 17, 2024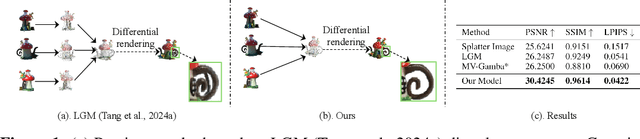
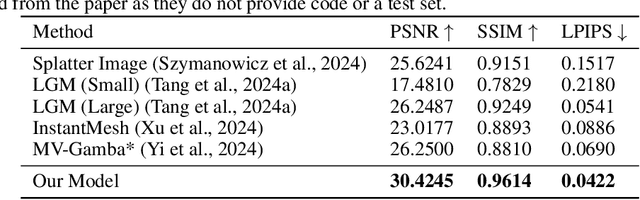
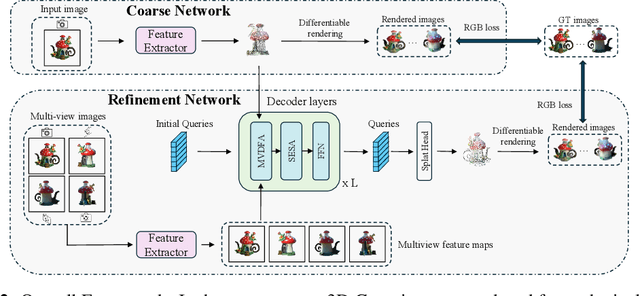

In this work, we present UniG, a view-consistent 3D reconstruction and novel view synthesis model that generates a high-fidelity representation of 3D Gaussians from sparse images. Existing 3D Gaussians-based methods usually regress Gaussians per-pixel of each view, create 3D Gaussians per view separately, and merge them through point concatenation. Such a view-independent reconstruction approach often results in a view inconsistency issue, where the predicted positions of the same 3D point from different views may have discrepancies. To address this problem, we develop a DETR (DEtection TRansformer)-like framework, which treats 3D Gaussians as decoder queries and updates their parameters layer by layer by performing multi-view cross-attention (MVDFA) over multiple input images. In this way, multiple views naturally contribute to modeling a unitary representation of 3D Gaussians, thereby making 3D reconstruction more view-consistent. Moreover, as the number of 3D Gaussians used as decoder queries is irrespective of the number of input views, allow an arbitrary number of input images without causing memory explosion. Extensive experiments validate the advantages of our approach, showcasing superior performance over existing methods quantitatively (improving PSNR by 4.2 dB when trained on Objaverse and tested on the GSO benchmark) and qualitatively.
Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
May 16, 2024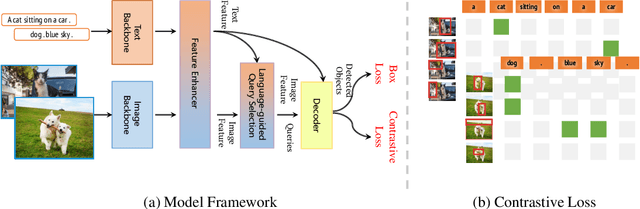
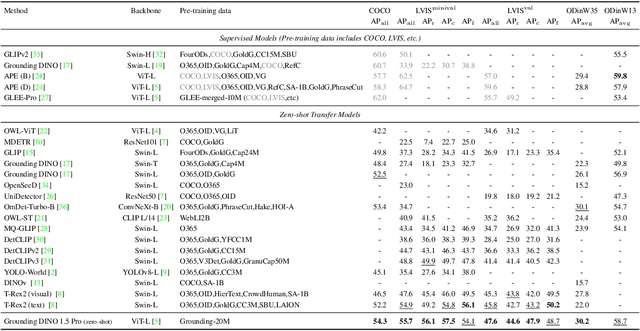
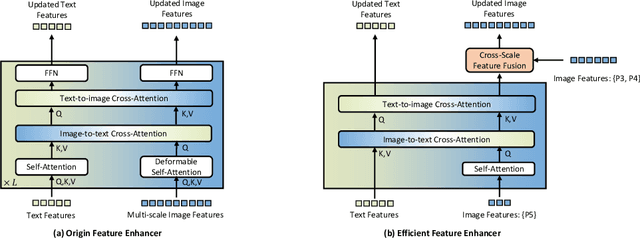

This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the "Edge" of open-set object detection. The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment. The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding. The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection. Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios. Model examples and demos with API will be released at https://github.com/IDEA-Research/Grounding-DINO-1.5-API
DIG3D: Marrying Gaussian Splatting with Deformable Transformer for Single Image 3D Reconstruction
Apr 25, 2024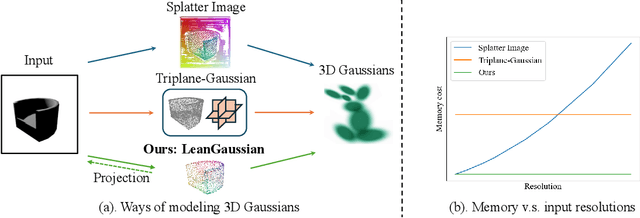

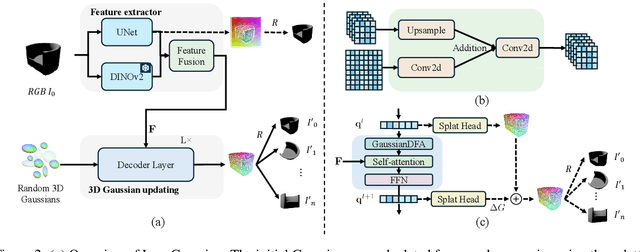

In this paper, we study the problem of 3D reconstruction from a single-view RGB image and propose a novel approach called DIG3D for 3D object reconstruction and novel view synthesis. Our method utilizes an encoder-decoder framework which generates 3D Gaussians in decoder with the guidance of depth-aware image features from encoder. In particular, we introduce the use of deformable transformer, allowing efficient and effective decoding through 3D reference point and multi-layer refinement adaptations. By harnessing the benefits of 3D Gaussians, our approach offers an efficient and accurate solution for 3D reconstruction from single-view images. We evaluate our method on the ShapeNet SRN dataset, getting PSNR of 24.21 and 24.98 in car and chair dataset, respectively. The result outperforming the recent method by around 2.25%, demonstrating the effectiveness of our method in achieving superior results.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Aug 15, 2022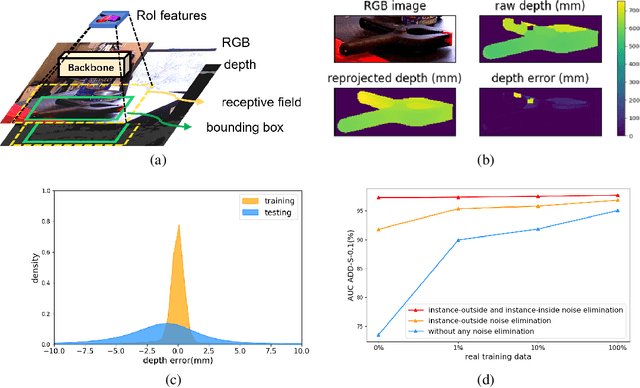
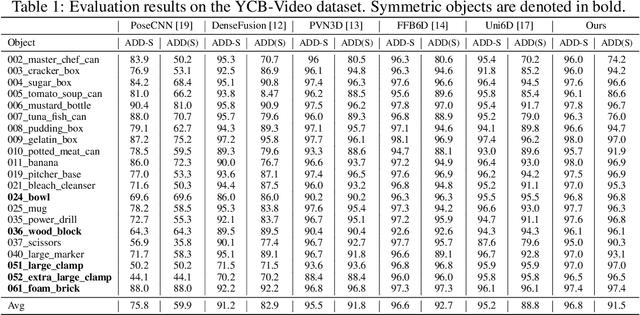
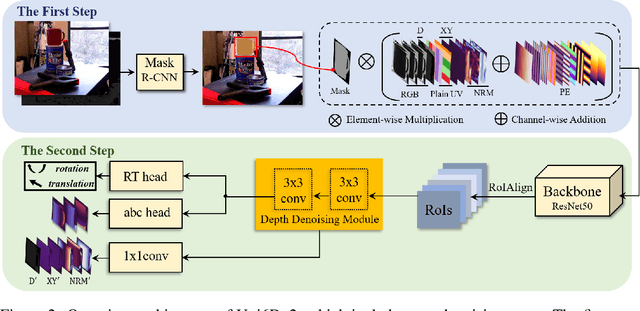
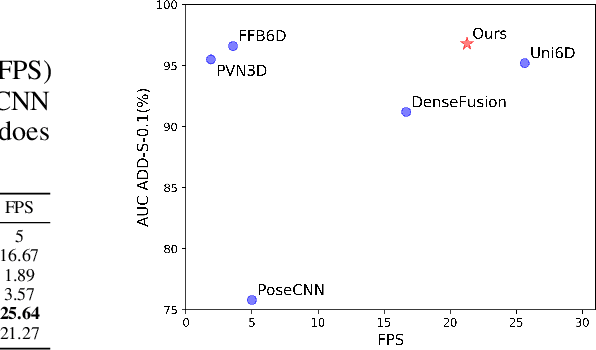
Few prior 6D pose estimation methods use a backbone network to extract features from RGB and depth images, and Uni6D is the pioneer to do so. We find that primary causes of the performance limitation in Uni6D are Instance-Outside and Instance-Inside noise. Uni6D inevitably introduces Instance-Outside noise from background pixels in the receptive field due to its inherently straightforward pipeline design and ignores the Instance-Inside noise in the input depth data. In this work, we propose a two-step denoising method to handle aforementioned noise in Uni6D. In the first step, an instance segmentation network is used to crop and mask the instance to remove noise from non-instance regions. In the second step, a lightweight depth denoising module is proposed to calibrate the depth feature before feeding it into the pose regression network. Extensive experiments show that our method called Uni6Dv2 is able to eliminate the noise effectively and robustly, outperforming Uni6D without sacrificing too much inference efficiency. It also reduces the need for annotated real data that requires costly labeling.
Uni6D: A Unified CNN Framework without Projection Breakdown for 6D Pose Estimation
Apr 05, 2022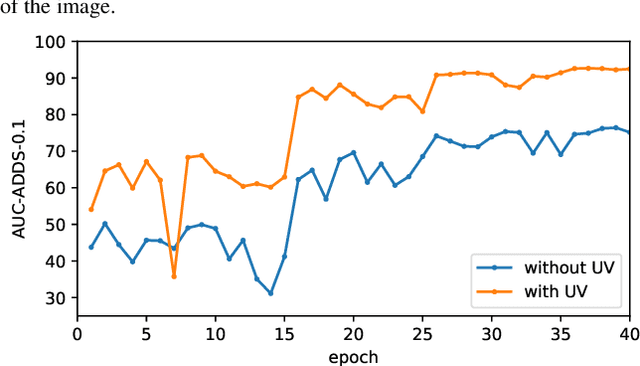
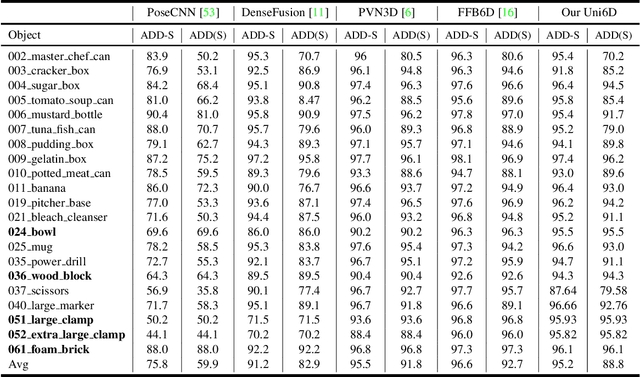
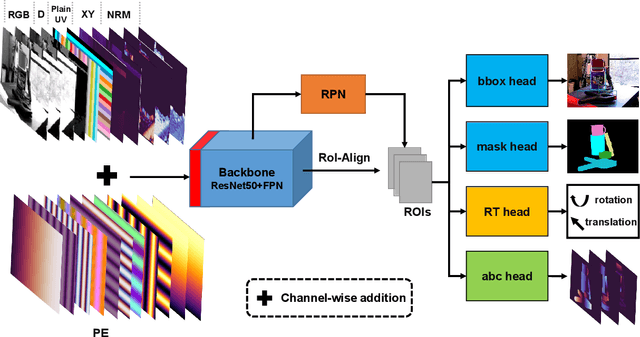
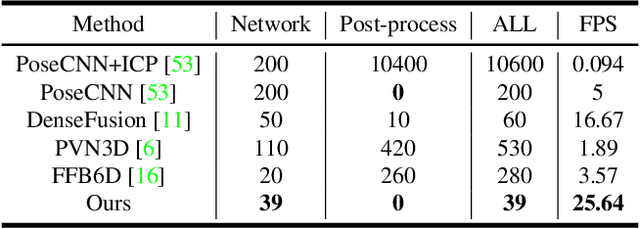
As RGB-D sensors become more affordable, using RGB-D images to obtain high-accuracy 6D pose estimation results becomes a better option. State-of-the-art approaches typically use different backbones to extract features for RGB and depth images. They use a 2D CNN for RGB images and a per-pixel point cloud network for depth data, as well as a fusion network for feature fusion. We find that the essential reason for using two independent backbones is the "projection breakdown" problem. In the depth image plane, the projected 3D structure of the physical world is preserved by the 1D depth value and its built-in 2D pixel coordinate (UV). Any spatial transformation that modifies UV, such as resize, flip, crop, or pooling operations in the CNN pipeline, breaks the binding between the pixel value and UV coordinate. As a consequence, the 3D structure is no longer preserved by a modified depth image or feature. To address this issue, we propose a simple yet effective method denoted as Uni6D that explicitly takes the extra UV data along with RGB-D images as input. Our method has a Unified CNN framework for 6D pose estimation with a single CNN backbone. In particular, the architecture of our method is based on Mask R-CNN with two extra heads, one named RT head for directly predicting 6D pose and the other named abc head for guiding the network to map the visible points to their coordinates in the 3D model as an auxiliary module. This end-to-end approach balances simplicity and accuracy, achieving comparable accuracy with state of the arts and 7.2x faster inference speed on the YCB-Video dataset.
Meta-Embeddings Based On Self-Attention
Mar 03, 2020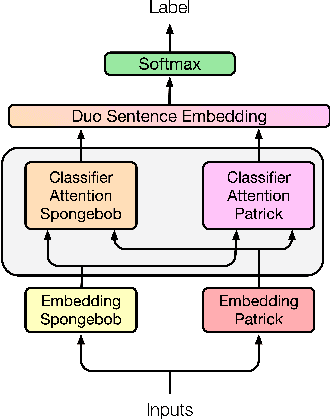
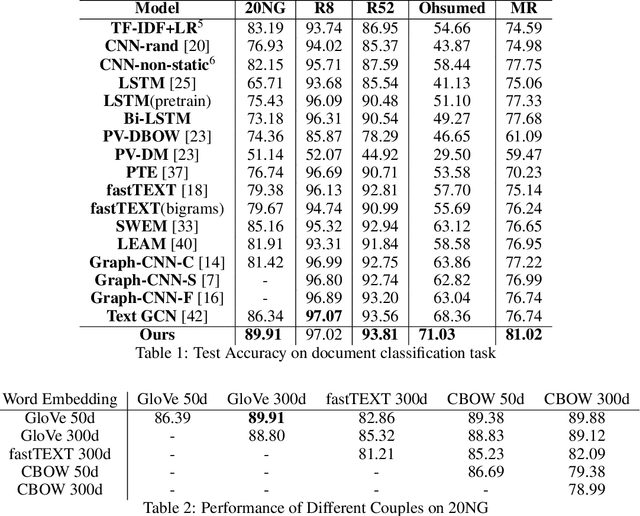
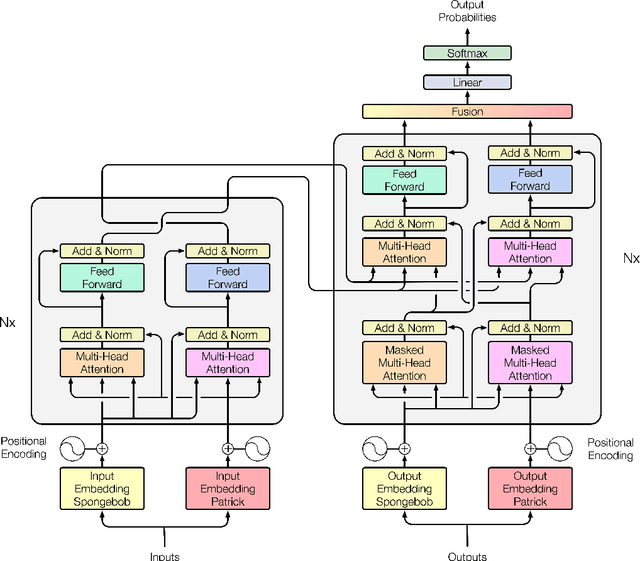
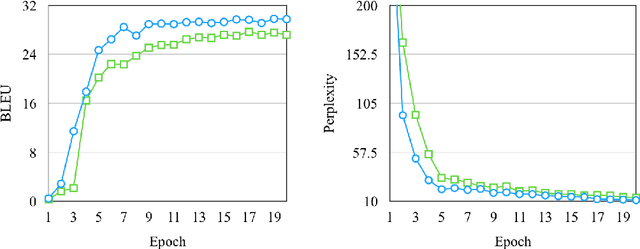
Creating meta-embeddings for better performance in language modelling has received attention lately, and methods based on concatenation or merely calculating the arithmetic mean of more than one separately trained embeddings to perform meta-embeddings have shown to be beneficial. In this paper, we devise a new meta-embedding model based on the self-attention mechanism, namely the Duo. With less than 0.4M parameters, the Duo mechanism achieves state-of-the-art accuracy in text classification tasks such as 20NG. Additionally, we propose a new meta-embedding sequece-to-sequence model for machine translation, which to the best of our knowledge, is the first machine translation model based on more than one word-embedding. Furthermore, it has turned out that our model outperform the Transformer not only in terms of achieving a better result, but also a faster convergence on recognized benchmarks, such as the WMT 2014 English-to-French translation task.