 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
Nov 21, 2024



In this paper, we introduce DINO-X, which is a unified object-centric vision model developed by IDEA Research with the best open-world object detection performance to date. DINO-X employs the same Transformer-based encoder-decoder architecture as Grounding DINO 1.5 to pursue an object-level representation for open-world object understanding. To make long-tailed object detection easy, DINO-X extends its input options to support text prompt, visual prompt, and customized prompt. With such flexible prompt options, we develop a universal object prompt to support prompt-free open-world detection, making it possible to detect anything in an image without requiring users to provide any prompt. To enhance the model's core grounding capability, we have constructed a large-scale dataset with over 100 million high-quality grounding samples, referred to as Grounding-100M, for advancing the model's open-vocabulary detection performance. Pre-training on such a large-scale grounding dataset leads to a foundational object-level representation, which enables DINO-X to integrate multiple perception heads to simultaneously support multiple object perception and understanding tasks, including detection, segmentation, pose estimation, object captioning, object-based QA, etc. Experimental results demonstrate the superior performance of DINO-X. Specifically, the DINO-X Pro model achieves 56.0 AP, 59.8 AP, and 52.4 AP on the COCO, LVIS-minival, and LVIS-val zero-shot object detection benchmarks, respectively. Notably, it scores 63.3 AP and 56.5 AP on the rare classes of LVIS-minival and LVIS-val benchmarks, both improving the previous SOTA performance by 5.8 AP. Such a result underscores its significantly improved capacity for recognizing long-tailed objects.
Control Pneumatic Soft Bending Actuator with Feedforward Hysteresis Compensation by Pneumatic Physical Reservoir Computing
Sep 11, 2024The nonlinearities of soft robots bring control challenges like hysteresis but also provide them with computational capacities. This paper introduces a fuzzy pneumatic physical reservoir computing (FPRC) model for feedforward hysteresis compensation in motion tracking control of soft actuators. Our method utilizes a pneumatic bending actuator as a physical reservoir with nonlinear computing capacities to control another pneumatic bending actuator. The FPRC model employs a Takagi-Sugeno (T-S) fuzzy model to process outputs from the physical reservoir. In comparative evaluations, the FPRC model shows equivalent training performance to an Echo State Network (ESN) model, whereas it exhibits better test accuracies with significantly reduced execution time. Experiments validate the proposed FPRC model's effectiveness in controlling the bending motion of the pneumatic soft actuator with open and closed-loop control systems. The proposed FPRC model's robustness against environmental disturbances has also been experimentally verified. To the authors' knowledge, this is the first implementation of a physical system in the feedforward hysteresis compensation model for controlling soft actuators. This study is expected to advance physical reservoir computing in nonlinear control applications and extend the feedforward hysteresis compensation methods for controlling soft actuators.
Two Degree of Freedom Adaptive Control for Hysteresis Compensation of Pneumatic Continuum Bending Actuator
Sep 18, 2023



Soft robotics, with their inherent flexibility and infinite degrees of freedom (DoF), offer promising advancements in human-machine interfaces. Particularly, pneumatic artificial muscles (PAMs) and pneumatic bending actuators have been fundamental in driving this evolution, capitalizing on their mimetic nature to natural muscle movements. However, with the versatility of these actuators comes the intricate challenge of hysteresis - a nonlinear phenomenon that hampers precise positioning, especially pronounced in pneumatic actuators due to gas compressibility. In this study, we introduce a novel 2-DoF adaptive control for precise bending tracking using a pneumatic continuum actuator. Notably, our control method integrates adaptability into both the feedback and the feedforward element, enhancing trajectory tracking in the presence of profound nonlinear effects. Comparative analysis with existing approaches underscores the superior tracking accuracy of our proposed strategy. This work discusses a new way of simple yet effective control designs for soft actuators with hysteresis properties.
Trajectory Tracking Control of Dual-PAM Soft Actuator with Hysteresis Compensator
Aug 23, 2023
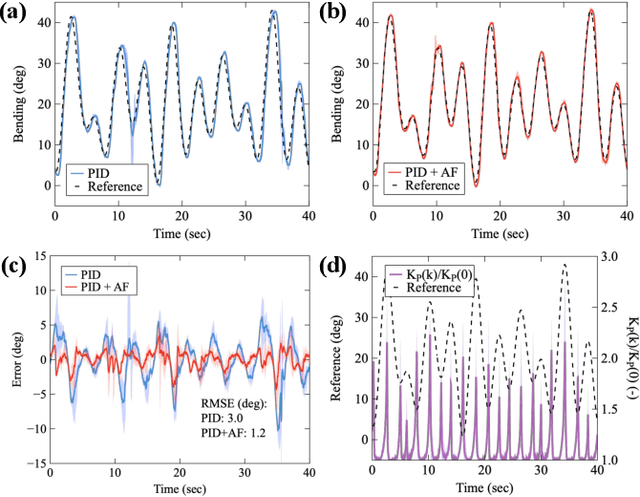


Soft robotics is an emergent and swiftly evolving field. Pneumatic actuators are suitable for driving soft robots because of their superior performance. However, their control is not easy due to their hysteresis characteristics. In response to these challenges, we propose an adaptive control method to compensate hysteresis of a soft actuator. Employing a novel dual pneumatic artificial muscle (PAM) bending actuator, the innovative control strategy abates hysteresis effects by dynamically modulating gains within a traditional PID controller corresponding with the predicted motion of the reference trajectory. Through comparative experimental evaluation, we found that the new control method outperforms its conventional counterparts regarding tracking accuracy and response speed. Our work reveals a new direction for advancing control in soft actuators.
ChatHaruhi: Reviving Anime Character in Reality via Large Language Model
Aug 18, 2023



Role-playing chatbots built on large language models have drawn interest, but better techniques are needed to enable mimicking specific fictional characters. We propose an algorithm that controls language models via an improved prompt and memories of the character extracted from scripts. We construct ChatHaruhi, a dataset covering 32 Chinese / English TV / anime characters with over 54k simulated dialogues. Both automatic and human evaluations show our approach improves role-playing ability over baselines. Code and data are available at https://github.com/LC1332/Chat-Haruhi-Suzumiya .
CLS: Cross Labeling Supervision for Semi-Supervised Learning
Feb 17, 2022
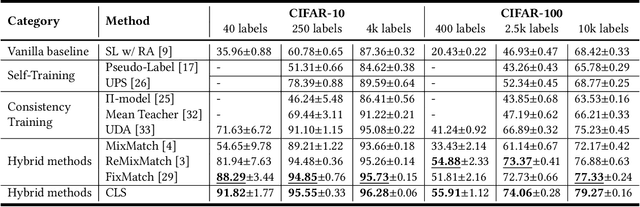

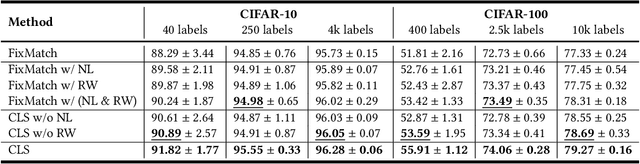
It is well known that the success of deep neural networks is greatly attributed to large-scale labeled datasets. However, it can be extremely time-consuming and laborious to collect sufficient high-quality labeled data in most practical applications. Semi-supervised learning (SSL) provides an effective solution to reduce the cost of labeling by simultaneously leveraging both labeled and unlabeled data. In this work, we present Cross Labeling Supervision (CLS), a framework that generalizes the typical pseudo-labeling process. Based on FixMatch, where a pseudo label is generated from a weakly-augmented sample to teach the prediction on a strong augmentation of the same input sample, CLS allows the creation of both pseudo and complementary labels to support both positive and negative learning. To mitigate the confirmation bias of self-labeling and boost the tolerance to false labels, two different initialized networks with the same structure are trained simultaneously. Each network utilizes high-confidence labels from the other network as additional supervision signals. During the label generation phase, adaptive sample weights are assigned to artificial labels according to their prediction confidence. The sample weight plays two roles: quantify the generated labels' quality and reduce the disruption of inaccurate labels on network training. Experimental results on the semi-supervised classification task show that our framework outperforms existing approaches by large margins on the CIFAR-10 and CIFAR-100 datasets.
Transfer Value Iteration Networks
Nov 27, 2019

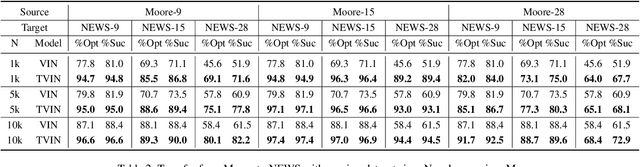

Value iteration networks (VINs) have been demonstrated to have a good generalization ability for reinforcement learning tasks across similar domains. However, based on our experiments, a policy learned by VINs still fail to generalize well on the domain whose action space and feature space are not identical to those in the domain where it is trained. In this paper, we propose a transfer learning approach on top of VINs, termed Transfer VINs (TVINs), such that a learned policy from a source domain can be generalized to a target domain with only limited training data, even if the source domain and the target domain have domain-specific actions and features. We empirically verify that our proposed TVINs outperform VINs when the source and the target domains have similar but not identical action and feature spaces. Furthermore, we show that the performance improvement is consistent across different environments, maze sizes, dataset sizes as well as different values of hyperparameters such as number of iteration and kernel size.