 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Regularized Federated Learning for Cross-Domain Aspect Sentiment Triplet Extraction
Apr 10, 2026Aspect Sentiment Triplet Extraction (ASTE) aims to extract all sentiment triplets of aspect terms, opinion terms, and sentiment polarities from a sentence. Existing methods are typically trained on individual datasets in isolation, failing to jointly capture the common feature representations shared across domains. Moreover, data privacy constraints prevent centralized data aggregation. To address these challenges, we propose Prototype-based Cross-Domain Span Prototype extraction (PCD-SpanProto), a prototype-regularized federated learning framework to enable distributed clients to exchange class-level prototypes instead of full model parameters. Specifically, we design a weighted performance-aware aggregation strategy and a contrastive regularization module to improve the global prototype under domain heterogeneity and the promotion between intra-class compactness and inter-class separability across clients. Extensive experiments on four ASTE datasets demonstrate that our method outperforms baselines and reduces communication costs, validating the effectiveness of prototype-based cross-domain knowledge transfer.
LLM-assisted Semantic Option Discovery for Facilitating Adaptive Deep Reinforcement Learning
Mar 02, 2026Despite achieving remarkable success in complex tasks, Deep Reinforcement Learning (DRL) is still suffering from critical issues in practical applications, such as low data efficiency, lack of interpretability, and limited cross-environment transferability. However, the learned policy generating actions based on states are sensitive to the environmental changes, struggling to guarantee behavioral safety and compliance. Recent research shows that integrating Large Language Models (LLMs) with symbolic planning is promising in addressing these challenges. Inspired by this, we introduce a novel LLM-driven closed-loop framework, which enables semantic-driven skill reuse and real-time constraint monitoring by mapping natural language instructions into executable rules and semantically annotating automatically created options. The proposed approach utilizes the general knowledge of LLMs to facilitate exploration efficiency and adapt to transferable options for similar environments, and provides inherent interpretability through semantic annotations. To validate the effectiveness of this framework, we conduct experiments on two domains, Office World and Montezuma's Revenge, respectively. The results demonstrate superior performance in data efficiency, constraint compliance, and cross-task transferability.
BalMCTS: Balancing Objective Function and Search Nodes in MCTS for Constraint Optimization Problems
Dec 26, 2023Constraint Optimization Problems (COP) pose intricate challenges in combinatorial problems usually addressed through Branch and Bound (B\&B) methods, which involve maintaining priority queues and iteratively selecting branches to search for solutions. However, conventional approaches take a considerable amount of time to find optimal solutions, and it is also crucial to quickly identify a near-optimal feasible solution in a shorter time. In this paper, we aim to investigate the effectiveness of employing a depth-first search algorithm for solving COP, specifically focusing on identifying optimal or near-optimal solutions within top $n$ solutions. Hence, we propose a novel heuristic neural network algorithm based on MCTS, which, by simultaneously conducting search and training, enables the neural network to effectively serve as a heuristic during Backtracking. Furthermore, our approach incorporates encoding COP problems and utilizing graph neural networks to aggregate information about variables and constraints, offering more appropriate variables for assignments. Experimental results on stochastic COP instances demonstrate that our method identifies feasible solutions with a gap of less than 17.63% within the initial 5 feasible solutions. Moreover, when applied to attendant Constraint Satisfaction Problem (CSP) instances, our method exhibits a remarkable reduction of less than 5% in searching nodes compared to state-of-the-art approaches.
Planning with Logical Graph-based Language Model for Instruction Generation
Aug 26, 2023Despite the superior performance of large language models to generate natural language texts, it is hard to generate texts with correct logic according to a given task, due to the difficulties for neural models to capture implied rules from free-form texts. In this paper, we propose a novel graph-based language model, Logical-GLM, to infuse logic into language models for more valid text generation and interpretability. Specifically, we first capture information from natural language instructions and construct logical bayes graphs that generally describe domains. Next, we generate logical skeletons to guide language model training, infusing domain knowledge into language models. Finally, we alternately optimize the searching policy of graphs and language models until convergence. The experimental results show that Logical-GLM is both effective and efficient compared with traditional language models, despite using smaller-scale training data and fewer parameters. Our approach can generate instructional texts with more correct logic owing to the internalized domain knowledge. Moreover, the usage of logical graphs reflects the inner mechanism of the language models, which improves the interpretability of black-box models.
DPBERT: Efficient Inference for BERT based on Dynamic Planning
Jul 26, 2023



Large-scale pre-trained language models such as BERT have contributed significantly to the development of NLP. However, those models require large computational resources, making it difficult to be applied to mobile devices where computing power is limited. In this paper we aim to address the weakness of existing input-adaptive inference methods which fail to take full advantage of the structure of BERT. We propose Dynamic Planning in BERT, a novel fine-tuning strategy that can accelerate the inference process of BERT through selecting a subsequence of transformer layers list of backbone as a computational path for an input sample. To do this, our approach adds a planning module to the original BERT model to determine whether a layer is included or bypassed during inference. Experimental results on the GLUE benchmark exhibit that our method reduces latency to 75\% while maintaining 98\% accuracy, yielding a better accuracy-speed trade-off compared to state-of-the-art input-adaptive methods.
Hierarchical Task Network Planning for Facilitating Cooperative Multi-Agent Reinforcement Learning
Jun 14, 2023
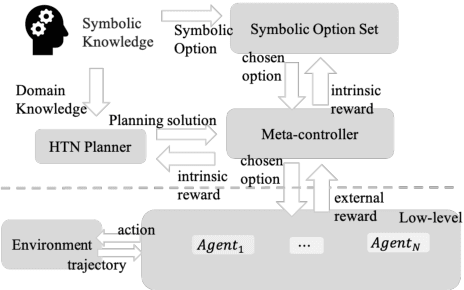


Exploring sparse reward multi-agent reinforcement learning (MARL) environments with traps in a collaborative manner is a complex task. Agents typically fail to reach the goal state and fall into traps, which affects the overall performance of the system. To overcome this issue, we present SOMARL, a framework that uses prior knowledge to reduce the exploration space and assist learning. In SOMARL, agents are treated as part of the MARL environment, and symbolic knowledge is embedded using a tree structure to build a knowledge hierarchy. The framework has a two-layer hierarchical structure, comprising a hybrid module with a Hierarchical Task Network (HTN) planning and meta-controller at the higher level, and a MARL-based interactive module at the lower level. The HTN module and meta-controller use Hierarchical Domain Definition Language (HDDL) and the option framework to formalize symbolic knowledge and obtain domain knowledge and a symbolic option set, respectively. Moreover, the HTN module leverages domain knowledge to guide low-level agent exploration by assisting the meta-controller in selecting symbolic options. The meta-controller further computes intrinsic rewards of symbolic options to limit exploration behavior and adjust HTN planning solutions as needed. We evaluate SOMARL on two benchmarks, FindTreasure and MoveBox, and report superior performance over state-of-the-art MARL and subgoal-based baselines for MARL environments significantly.
Sequential Condition Evolved Interaction Knowledge Graph for Traditional Chinese Medicine Recommendation
May 29, 2023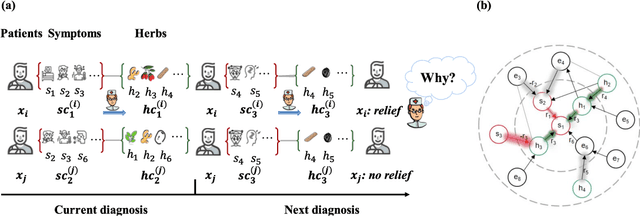

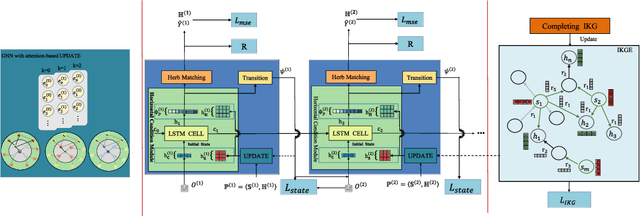

Traditional Chinese Medicine (TCM) has a rich history of utilizing natural herbs to treat a diversity of illnesses. In practice, TCM diagnosis and treatment are highly personalized and organically holistic, requiring comprehensive consideration of the patient's state and symptoms over time. However, existing TCM recommendation approaches overlook the changes in patient status and only explore potential patterns between symptoms and prescriptions. In this paper, we propose a novel Sequential Condition Evolved Interaction Knowledge Graph (SCEIKG), a framework that treats the model as a sequential prescription-making problem by considering the dynamics of the patient's condition across multiple visits. In addition, we incorporate an interaction knowledge graph to enhance the accuracy of recommendations by considering the interactions between different herbs and the patient's condition. Experimental results on a real-world dataset demonstrate that our approach outperforms existing TCM recommendation methods, achieving state-of-the-art performance.
XRoute Environment: A Novel Reinforcement Learning Environment for Routing
May 23, 2023Routing is a crucial and time-consuming stage in modern design automation flow for advanced technology nodes. Great progress in the field of reinforcement learning makes it possible to use those approaches to improve the routing quality and efficiency. However, the scale of the routing problems solved by reinforcement learning-based methods in recent studies is too small for these methods to be used in commercial EDA tools. We introduce the XRoute Environment, a new reinforcement learning environment where agents are trained to select and route nets in an advanced, end-to-end routing framework. Novel algorithms and ideas can be quickly tested in a safe and reproducible manner in it. The resulting environment is challenging, easy to use, customize and add additional scenarios, and it is available under a permissive open-source license. In addition, it provides support for distributed deployment and multi-instance experiments. We propose two tasks for learning and build a full-chip test bed with routing benchmarks of various region sizes. We also pre-define several static routing regions with different pin density and number of nets for easier learning and testing. For net ordering task, we report baseline results for two widely used reinforcement learning algorithms (PPO and DQN) and one searching-based algorithm (TritonRoute). The XRoute Environment will be available at https://github.com/xplanlab/xroute_env.
Reinforcement Learning with Knowledge Representation and Reasoning: A Brief Survey
Apr 24, 2023Reinforcement Learning(RL) has achieved tremendous development in recent years, but still faces significant obstacles in addressing complex real-life problems due to the issues of poor system generalization, low sample efficiency as well as safety and interpretability concerns. The core reason underlying such dilemmas can be attributed to the fact that most of the work has focused on the computational aspect of value functions or policies using a representational model to describe atomic components of rewards, states and actions etc, thus neglecting the rich high-level declarative domain knowledge of facts, relations and rules that can be either provided a priori or acquired through reasoning over time. Recently, there has been a rapidly growing interest in the use of Knowledge Representation and Reasoning(KRR) methods, usually using logical languages, to enable more abstract representation and efficient learning in RL. In this survey, we provide a preliminary overview on these endeavors that leverage the strengths of KRR to help solving various problems in RL, and discuss the challenging open problems and possible directions for future work in this area.
Plan To Predict: Learning an Uncertainty-Foreseeing Model for Model-Based Reinforcement Learning
Jan 20, 2023



In Model-based Reinforcement Learning (MBRL), model learning is critical since an inaccurate model can bias policy learning via generating misleading samples. However, learning an accurate model can be difficult since the policy is continually updated and the induced distribution over visited states used for model learning shifts accordingly. Prior methods alleviate this issue by quantifying the uncertainty of model-generated samples. However, these methods only quantify the uncertainty passively after the samples were generated, rather than foreseeing the uncertainty before model trajectories fall into those highly uncertain regions. The resulting low-quality samples can induce unstable learning targets and hinder the optimization of the policy. Moreover, while being learned to minimize one-step prediction errors, the model is generally used to predict for multiple steps, leading to a mismatch between the objectives of model learning and model usage. To this end, we propose \emph{Plan To Predict} (P2P), an MBRL framework that treats the model rollout process as a sequential decision making problem by reversely considering the model as a decision maker and the current policy as the dynamics. In this way, the model can quickly adapt to the current policy and foresee the multi-step future uncertainty when generating trajectories. Theoretically, we show that the performance of P2P can be guaranteed by approximately optimizing a lower bound of the true environment return. Empirical results demonstrate that P2P achieves state-of-the-art performance on several challenging benchmark tasks.