 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoICE: Automatically Synthesizing Verifiable C Code via LLM-driven Evolution
Dec 08, 2025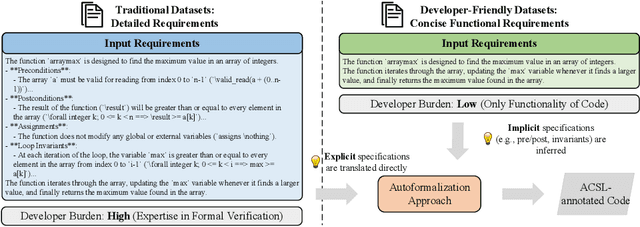
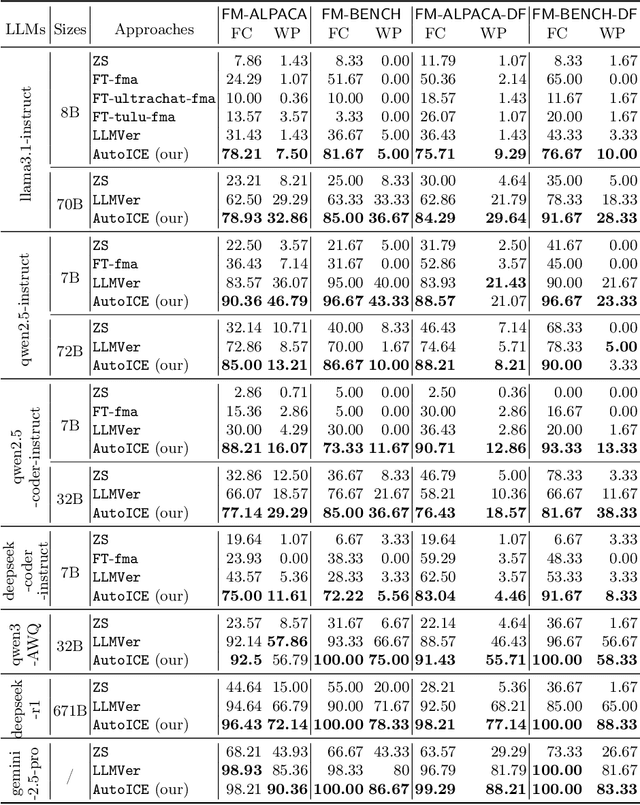

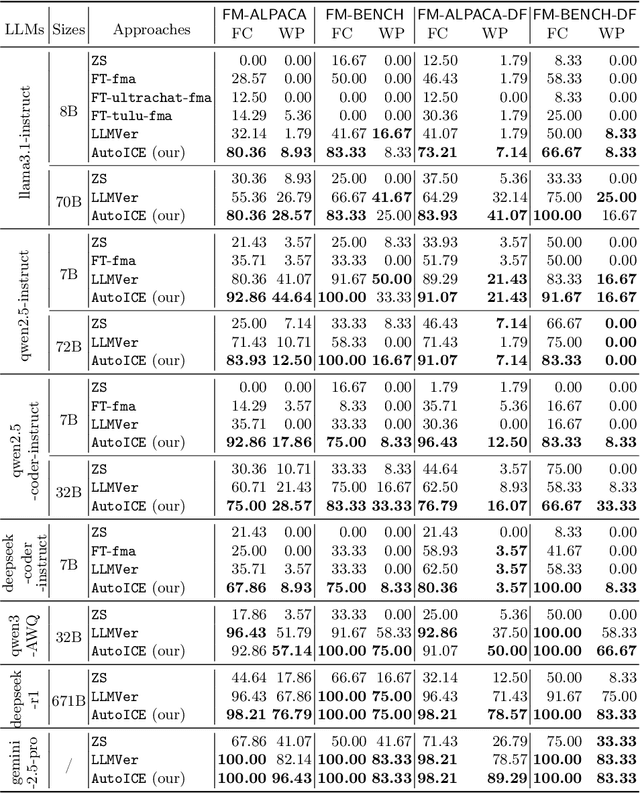
Automatically synthesizing verifiable code from natural language requirements ensures software correctness and reliability while significantly lowering the barrier to adopting the techniques of formal methods. With the rise of large language models (LLMs), long-standing efforts at autoformalization have gained new momentum. However, existing approaches suffer from severe syntactic and semantic errors due to the scarcity of domain-specific pre-training corpora and often fail to formalize implicit knowledge effectively. In this paper, we propose AutoICE, an LLM-driven evolutionary search for synthesizing verifiable C code. It introduces the diverse individual initialization and the collaborative crossover to enable diverse iterative updates, thereby mitigating error propagation inherent in single-agent iterations. Besides, it employs the self-reflective mutation to facilitate the discovery of implicit knowledge. Evaluation results demonstrate the effectiveness of AutoICE: it successfully verifies $90.36$\% of code, outperforming the state-of-the-art (SOTA) approach. Besides, on a developer-friendly dataset variant, AutoICE achieves a $88.33$\% verification success rate, significantly surpassing the $65$\% success rate of the SOTA approach.
KnowLogic: A Benchmark for Commonsense Reasoning via Knowledge-Driven Data Synthesis
Mar 08, 2025Current evaluations of commonsense reasoning in LLMs are hindered by the scarcity of natural language corpora with structured annotations for reasoning tasks. To address this, we introduce KnowLogic, a benchmark generated through a knowledge-driven synthetic data strategy. KnowLogic integrates diverse commonsense knowledge, plausible scenarios, and various types of logical reasoning. One of the key advantages of KnowLogic is its adjustable difficulty levels, allowing for flexible control over question complexity. It also includes fine-grained labels for in-depth evaluation of LLMs' reasoning abilities across multiple dimensions. Our benchmark consists of 3,000 bilingual (Chinese and English) questions across various domains, and presents significant challenges for current LLMs, with the highest-performing model achieving only 69.57\%. Our analysis highlights common errors, such as misunderstandings of low-frequency commonsense, logical inconsistencies, and overthinking. This approach, along with our benchmark, provides a valuable tool for assessing and enhancing LLMs' commonsense reasoning capabilities and can be applied to a wide range of knowledge domains.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024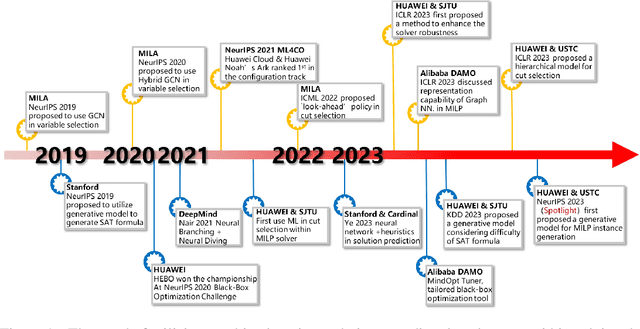
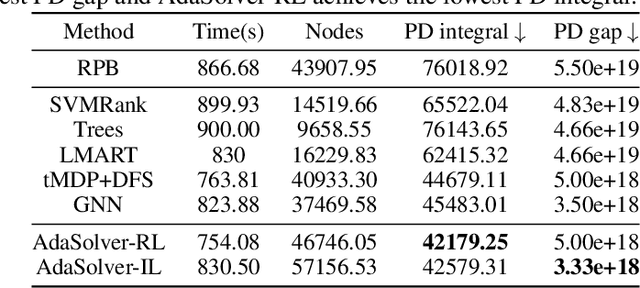

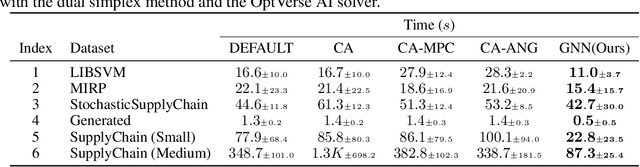
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Reinforcement Learning with Knowledge Representation and Reasoning: A Brief Survey
Apr 24, 2023Reinforcement Learning(RL) has achieved tremendous development in recent years, but still faces significant obstacles in addressing complex real-life problems due to the issues of poor system generalization, low sample efficiency as well as safety and interpretability concerns. The core reason underlying such dilemmas can be attributed to the fact that most of the work has focused on the computational aspect of value functions or policies using a representational model to describe atomic components of rewards, states and actions etc, thus neglecting the rich high-level declarative domain knowledge of facts, relations and rules that can be either provided a priori or acquired through reasoning over time. Recently, there has been a rapidly growing interest in the use of Knowledge Representation and Reasoning(KRR) methods, usually using logical languages, to enable more abstract representation and efficient learning in RL. In this survey, we provide a preliminary overview on these endeavors that leverage the strengths of KRR to help solving various problems in RL, and discuss the challenging open problems and possible directions for future work in this area.
A Noise-tolerant Differentiable Learning Approach for Single Occurrence Regular Expression with Interleaving
Dec 02, 2022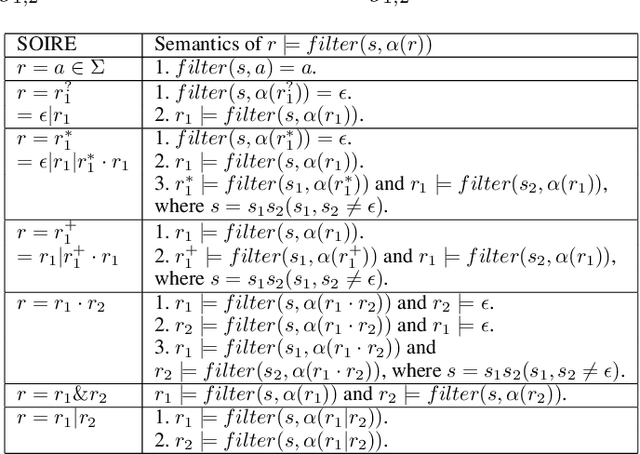
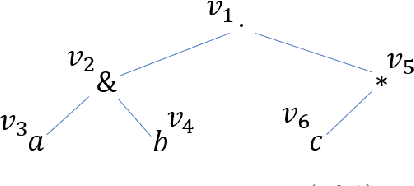
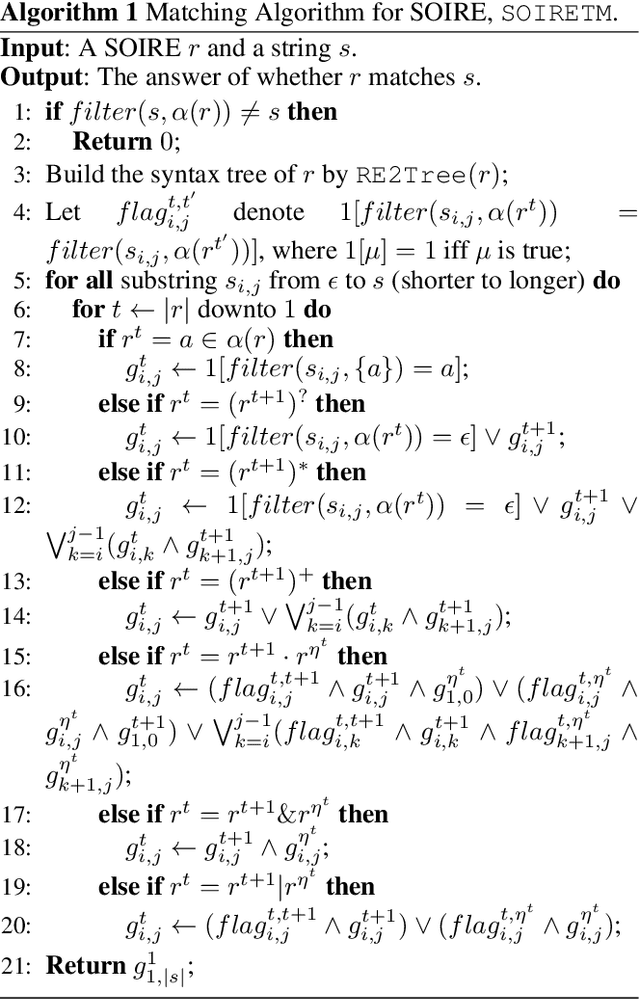
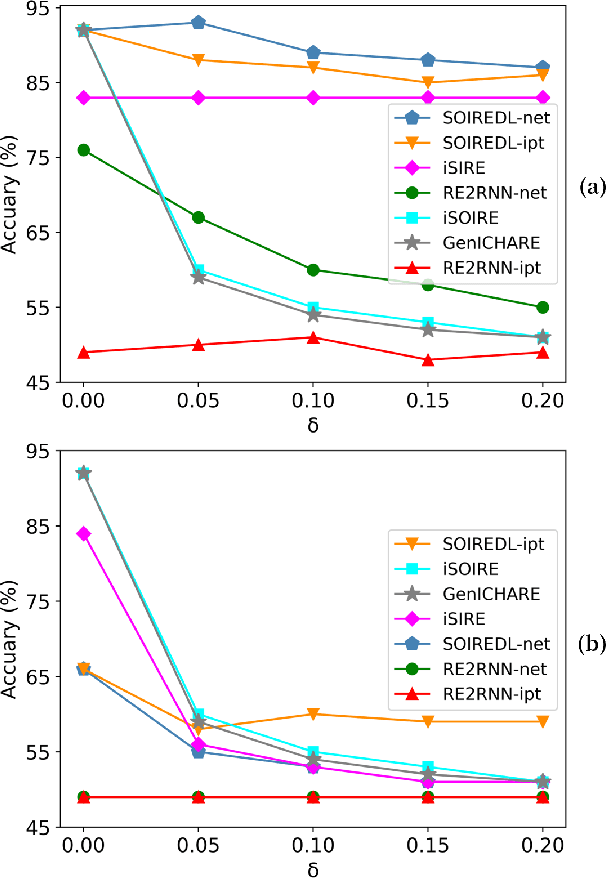
We study the problem of learning a single occurrence regular expression with interleaving (SOIRE) from a set of text strings possibly with noise. SOIRE fully supports interleaving and covers a large portion of regular expressions used in practice. Learning SOIREs is challenging because it requires heavy computation and text strings usually contain noise in practice. Most of the previous studies only learn restricted SOIREs and are not robust on noisy data. To tackle these issues, we propose a noise-tolerant differentiable learning approach SOIREDL for SOIRE. We design a neural network to simulate SOIRE matching and theoretically prove that certain assignments of the set of parameters learnt by the neural network, called faithful encodings, are one-to-one corresponding to SOIREs for a bounded size. Based on this correspondence, we interpret the target SOIRE from an assignment of the set of parameters of the neural network by exploring the nearest faithful encodings. Experimental results show that SOIREDL outperforms the state-of-the-art approaches, especially on noisy data.
Learning to Optimize Industry-Scale Dynamic Pickup and Delivery Problems
May 27, 2021The Dynamic Pickup and Delivery Problem (DPDP) is aimed at dynamically scheduling vehicles among multiple sites in order to minimize the cost when delivery orders are not known a priori. Although DPDP plays an important role in modern logistics and supply chain management, state-of-the-art DPDP algorithms are still limited on their solution quality and efficiency. In practice, they fail to provide a scalable solution as the numbers of vehicles and sites become large. In this paper, we propose a data-driven approach, Spatial-Temporal Aided Double Deep Graph Network (ST-DDGN), to solve industry-scale DPDP. In our method, the delivery demands are first forecast using spatial-temporal prediction method, which guides the neural network to perceive spatial-temporal distribution of delivery demand when dispatching vehicles. Besides, the relationships of individuals such as vehicles are modelled by establishing a graph-based value function. ST-DDGN incorporates attention-based graph embedding with Double DQN (DDQN). As such, it can make the inference across vehicles more efficiently compared with traditional methods. Our method is entirely data driven and thus adaptive, i.e., the relational representation of adjacent vehicles can be learned and corrected by ST-DDGN from data periodically. We have conducted extensive experiments over real-world data to evaluate our solution. The results show that ST-DDGN reduces 11.27% number of the used vehicles and decreases 13.12% total transportation cost on average over the strong baselines, including the heuristic algorithm deployed in our UAT (User Acceptance Test) environment and a variety of vanilla DRL methods. We are due to fully deploy our solution into our online logistics system and it is estimated that millions of USD logistics cost can be saved per year.
Structural Similarity of Boundary Conditions and an Efficient Local Search Algorithm for Goal Conflict Identification
Feb 23, 2021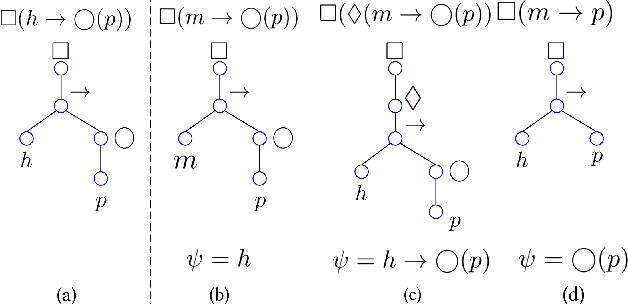
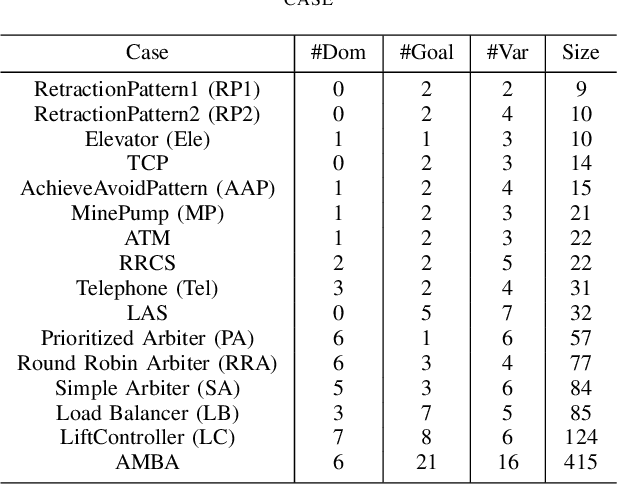
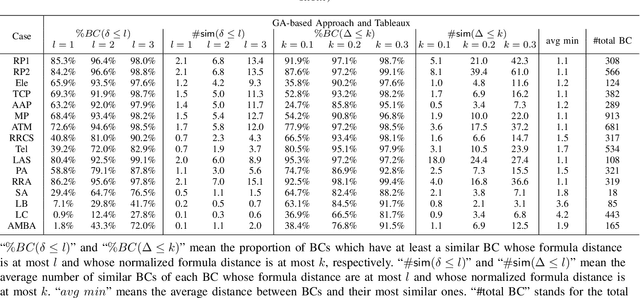
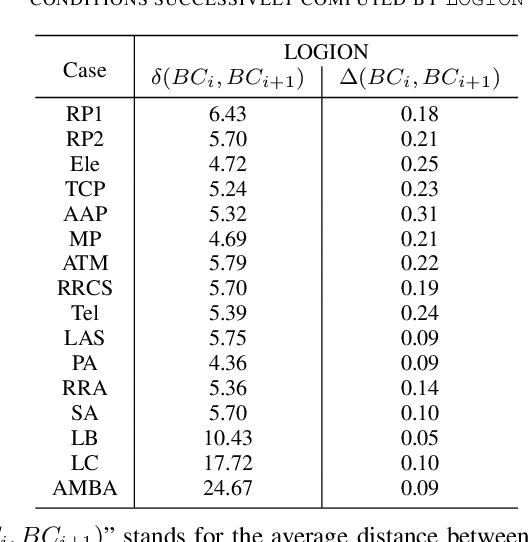
In goal-oriented requirements engineering, goal conflict identification is of fundamental importance for requirements analysis. The task aims to find the feasible situations which make the goals diverge within the domain, called boundary conditions (BCs). However, the existing approaches for goal conflict identification fail to find sufficient BCs and general BCs which cover more combinations of circumstances. From the BCs found by these existing approaches, we have observed an interesting phenomenon that there are some pairs of BCs are similar in formula structure, which occurs frequently in the experimental cases. In other words, once a BC is found, a new BC may be discovered quickly by slightly changing the former. It inspires us to develop a local search algorithm named LOGION to find BCs, in which the structural similarity is captured by the neighborhood relation of formulae. Based on structural similarity, LOGION can find a lot of BCs in a short time. Moreover, due to the large number of BCs identified, it potentially selects more general BCs from them. By taking experiments on a set of cases, we show that LOGION effectively exploits the structural similarity of BCs. We also compare our algorithm against the two state-of-the-art approaches. The experimental results show that LOGION produces one order of magnitude more BCs than the state-of-the-art approaches and confirm that LOGION finds out more general BCs thanks to a large number of BCs.
CoAPI: An Efficient Two-Phase Algorithm Using Core-Guided Over-Approximate Cover for Prime Compilation of Non-Clausal Formulae
Jun 07, 2019
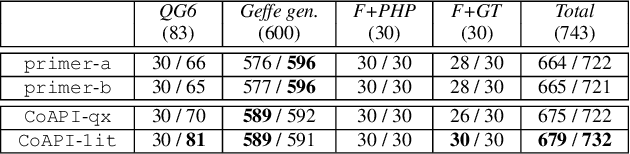
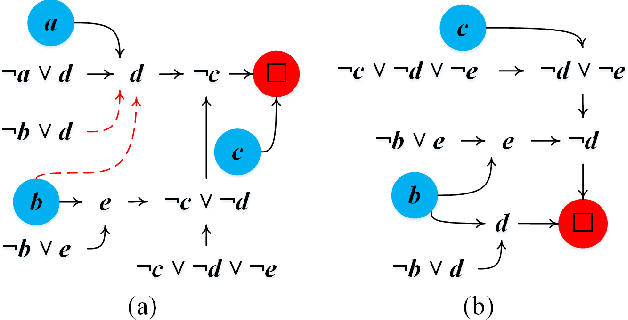
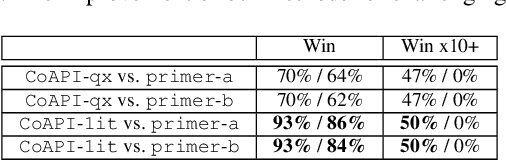
Prime compilation, i.e., the generation of all prime implicates or implicants (primes for short) of formulae, is a prominent fundamental issue for AI. Recently, the prime compilation for non-clausal formulae has received great attention. The state-of-the-art approaches generate all primes along with a prime cover constructed by prime implicates using dual rail encoding. However, the dual rail encoding potentially expands search space. In addition, constructing a prime cover, which is necessary for their methods, is time-consuming. To address these issues, we propose a novel two-phase method -- CoAPI. The two phases are the key to construct a cover without using dual rail encoding. Specifically, given a non-clausal formula, we first propose a core-guided method to rewrite the non-clausal formula into a cover constructed by over-approximate implicates in the first phase. Then, we generate all the primes based on the cover in the second phase. In order to reduce the size of the cover, we provide a multi-order based shrinking method, with a good tradeoff between the small size and efficiency, to compress the size of cover considerably. The experimental results show that CoAPI outperforms state-of-the-art approaches. Particularly, for generating all prime implicates, CoAPI consumes about one order of magnitude less time.
Combining Reinforcement Learning and Configuration Checking for Maximum k-plex Problem
Jun 06, 2019
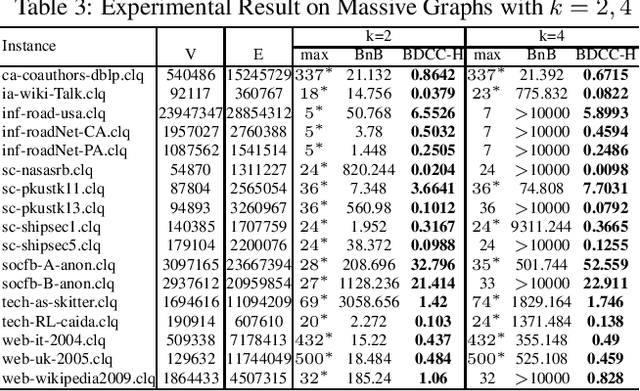
The Maximum k-plex Problem is an important combinatorial optimization problem with increasingly wide applications. Due to its exponential time complexity, many heuristic methods have been proposed which can return a good-quality solution in a reasonable time. However, most of the heuristic algorithms are memoryless and unable to utilize the experience during the search. Inspired by the multi-armed bandit (MAB) problem in reinforcement learning (RL), we propose a novel perturbation mechanism named BLP, which can learn online to select a good vertex for perturbation when getting stuck in local optima. To our best of knowledge, this is the first attempt to combine local search with RL for the maximum $ k $-plex problem. Besides, we also propose a novel strategy, named Dynamic-threshold Configuration Checking (DTCC), which extends the original Configuration Checking (CC) strategy from two aspects. Based on the BLP and DTCC, we develop a local search algorithm named BDCC and improve it by a hyperheuristic strategy. The experimental result shows that our algorithms dominate on the standard DIMACS and BHOSLIB benchmarks and achieve state-of-the-art performance on massive graphs.