 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDVISTAGYM: A Scalable Training Environment for Thinking with Medical Images via Tool-Integrated Reinforcement Learning
Jan 12, 2026Vision language models (VLMs) achieve strong performance on general image understanding but struggle to think with medical images, especially when performing multi-step reasoning through iterative visual interaction. Medical VLMs often rely on static visual embeddings and single-pass inference, preventing models from re-examining, verifying, or refining visual evidence during reasoning. While tool-integrated reasoning offers a promising path forward, open-source VLMs lack the training infrastructure to learn effective tool selection, invocation, and coordination in multi-modal medical reasoning. We introduce MedVistaGym, a scalable and interactive training environment that incentivizes tool-integrated visual reasoning for medical image analysis. MedVistaGym equips VLMs to determine when and which tools to invoke, localize task-relevant image regions, and integrate single or multiple sub-image evidence into interleaved multimodal reasoning within a unified, executable interface for agentic training. Using MedVistaGym, we train MedVistaGym-R1 to interleave tool use with agentic reasoning through trajectory sampling and end-to-end reinforcement learning. Across six medical VQA benchmarks, MedVistaGym-R1-8B exceeds comparably sized tool-augmented baselines by 19.10% to 24.21%, demonstrating that structured agentic training--not tool access alone--unlocks effective tool-integrated reasoning for medical image analysis.
Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline
May 28, 2025Multilingual large language models (LLMs) often exhibit factual inconsistencies across languages, with significantly better performance in factual recall tasks in English than in other languages. The causes of these failures, however, remain poorly understood. Using mechanistic analysis techniques, we uncover the underlying pipeline that LLMs employ, which involves using the English-centric factual recall mechanism to process multilingual queries and then translating English answers back into the target language. We identify two primary sources of error: insufficient engagement of the reliable English-centric mechanism for factual recall, and incorrect translation from English back into the target language for the final answer. To address these vulnerabilities, we introduce two vector interventions, both independent of languages and datasets, to redirect the model toward better internal paths for higher factual consistency. Our interventions combined increase the recall accuracy by over 35 percent for the lowest-performing language. Our findings demonstrate how mechanistic insights can be used to unlock latent multilingual capabilities in LLMs.
DEBATE, TRAIN, EVOLVE: Self Evolution of Language Model Reasoning
May 21, 2025Large language models (LLMs) have improved significantly in their reasoning through extensive training on massive datasets. However, relying solely on additional data for improvement is becoming increasingly impractical, highlighting the need for models to autonomously enhance their reasoning without external supervision. In this paper, we propose Debate, Train, Evolve (DTE), a novel ground truth-free training framework that uses multi-agent debate traces to evolve a single language model. We also introduce a new prompting strategy Reflect-Critique-Refine, to improve debate quality by explicitly instructing agents to critique and refine their reasoning. Extensive evaluations on five reasoning benchmarks with six open-weight models show that our DTE framework achieve substantial improvements, with an average accuracy gain of 8.92% on the challenging GSM-PLUS dataset. Furthermore, we observe strong cross-domain generalization, with an average accuracy gain of 5.8% on all other benchmarks, suggesting that our method captures general reasoning capabilities.
Cross-Encoder Rediscovers a Semantic Variant of BM25
Feb 07, 2025



Neural Ranking Models (NRMs) have rapidly advanced state-of-the-art performance on information retrieval tasks. In this work, we investigate a Cross-Encoder variant of MiniLM to determine which relevance features it computes and where they are stored. We find that it employs a semantic variant of the traditional BM25 in an interpretable manner, featuring localized components: (1) Transformer attention heads that compute soft term frequency while controlling for term saturation and document length effects, and (2) a low-rank component of its embedding matrix that encodes inverse document frequency information for the vocabulary. This suggests that the Cross-Encoder uses the same fundamental mechanisms as BM25, but further leverages their capacity to capture semantics for improved retrieval performance. The granular understanding lays the groundwork for model editing to enhance model transparency, addressing safety concerns, and improving scalability in training and real-world applications.
AI for Biomedicine in the Era of Large Language Models
Mar 23, 2024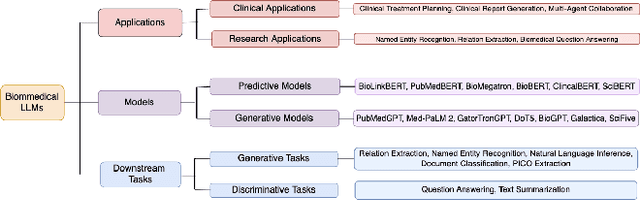
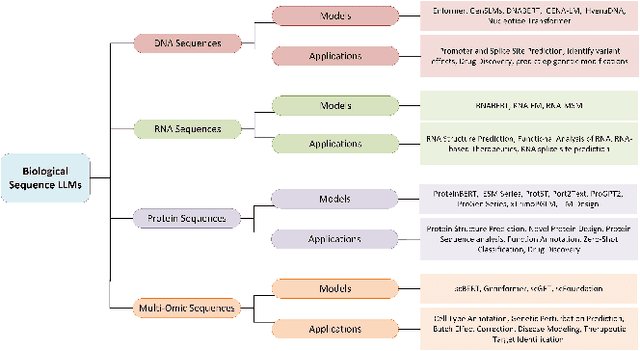
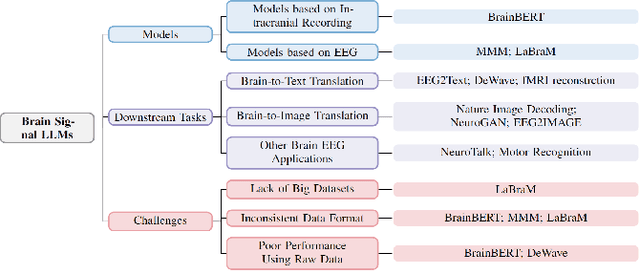
The capabilities of AI for biomedicine span a wide spectrum, from the atomic level, where it solves partial differential equations for quantum systems, to the molecular level, predicting chemical or protein structures, and further extending to societal predictions like infectious disease outbreaks. Recent advancements in large language models, exemplified by models like ChatGPT, have showcased significant prowess in natural language tasks, such as translating languages, constructing chatbots, and answering questions. When we consider biomedical data, we observe a resemblance to natural language in terms of sequences: biomedical literature and health records presented as text, biological sequences or sequencing data arranged in sequences, or sensor data like brain signals as time series. The question arises: Can we harness the potential of recent large language models to drive biomedical knowledge discoveries? In this survey, we will explore the application of large language models to three crucial categories of biomedical data: 1) textual data, 2) biological sequences, and 3) brain signals. Furthermore, we will delve into large language model challenges in biomedical research, including ensuring trustworthiness, achieving personalization, and adapting to multi-modal data representation
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024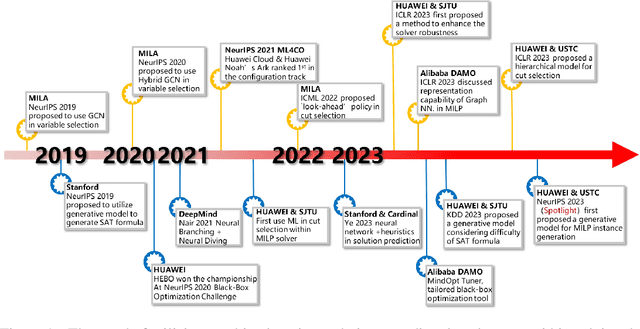
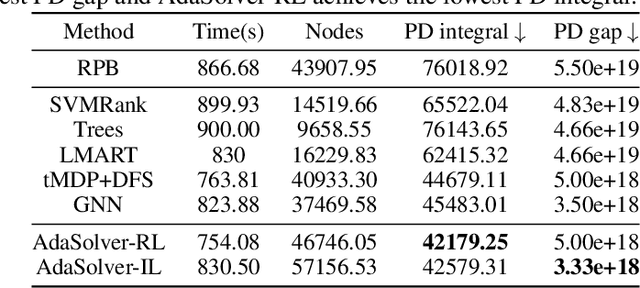

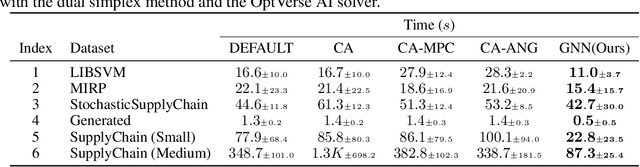
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Accelerate Presolve in Large-Scale Linear Programming via Reinforcement Learning
Oct 18, 2023



Large-scale LP problems from industry usually contain much redundancy that severely hurts the efficiency and reliability of solving LPs, making presolve (i.e., the problem simplification module) one of the most critical components in modern LP solvers. However, how to design high-quality presolve routines -- that is, the program determining (P1) which presolvers to select, (P2) in what order to execute, and (P3) when to stop -- remains a highly challenging task due to the extensive requirements on expert knowledge and the large search space. Due to the sequential decision property of the task and the lack of expert demonstrations, we propose a simple and efficient reinforcement learning (RL) framework -- namely, reinforcement learning for presolve (RL4Presolve) -- to tackle (P1)-(P3) simultaneously. Specifically, we formulate the routine design task as a Markov decision process and propose an RL framework with adaptive action sequences to generate high-quality presolve routines efficiently. Note that adaptive action sequences help learn complex behaviors efficiently and adapt to various benchmarks. Experiments on two solvers (open-source and commercial) and eight benchmarks (real-world and synthetic) demonstrate that RL4Presolve significantly and consistently improves the efficiency of solving large-scale LPs, especially on benchmarks from industry. Furthermore, we optimize the hard-coded presolve routines in LP solvers by extracting rules from learned policies for simple and efficient deployment to Huawei's supply chain. The results show encouraging economic and academic potential for incorporating machine learning to modern solvers.
Spatio-temporal Vision Transformer for Super-resolution Microscopy
Feb 28, 2022



Structured illumination microscopy (SIM) is an optical super-resolution technique that enables live-cell imaging beyond the diffraction limit. Reconstruction of SIM data is prone to artefacts, which becomes problematic when imaging highly dynamic samples because previous methods rely on the assumption that samples are static. We propose a new transformer-based reconstruction method, VSR-SIM, that uses shifted 3-dimensional window multi-head attention in addition to channel attention mechanism to tackle the problem of video super-resolution (VSR) in SIM. The attention mechanisms are found to capture motion in sequences without the need for common motion estimation techniques such as optical flow. We take an approach to training the network that relies solely on simulated data using videos of natural scenery with a model for SIM image formation. We demonstrate a use case enabled by VSR-SIM referred to as rolling SIM imaging, which increases temporal resolution in SIM by a factor of 9. Our method can be applied to any SIM setup enabling precise recordings of dynamic processes in biomedical research with high temporal resolution.