 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP4GCN: Vertical Federated Social Recommendation with Privacy-Preserving Two-Party Graph Convolution Networks
Oct 16, 2024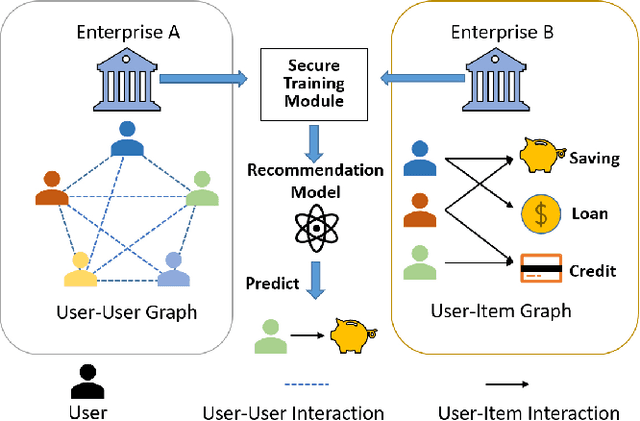
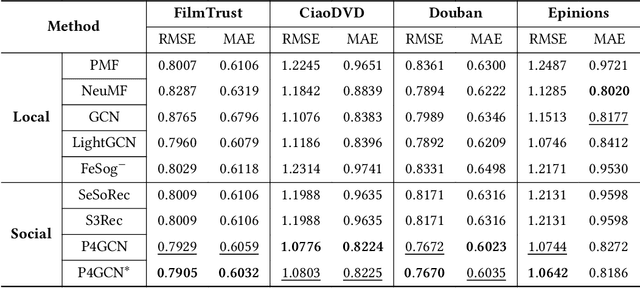

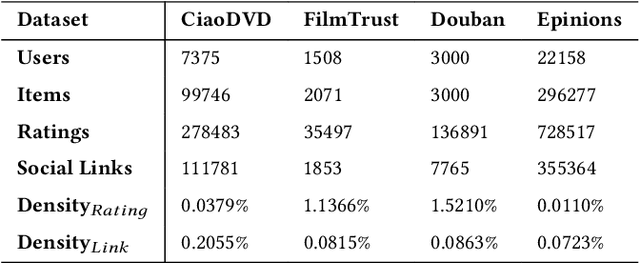
In recent years, graph neural networks (GNNs) have been commonly utilized for social recommendation systems. However, real-world scenarios often present challenges related to user privacy and business constraints, inhibiting direct access to valuable social information from other platforms. While many existing methods have tackled matrix factorization-based social recommendations without direct social data access, developing GNN-based federated social recommendation models under similar conditions remains largely unexplored. To address this issue, we propose a novel vertical federated social recommendation method leveraging privacy-preserving two-party graph convolution networks (P4GCN) to enhance recommendation accuracy without requiring direct access to sensitive social information. First, we introduce a Sandwich-Encryption module to ensure comprehensive data privacy during the collaborative computing process. Second, we provide a thorough theoretical analysis of the privacy guarantees, considering the participation of both curious and honest parties. Extensive experiments on four real-world datasets demonstrate that P4GCN outperforms state-of-the-art methods in terms of recommendation accuracy. The code is available at https://github.com/WwZzz/P4GCN.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024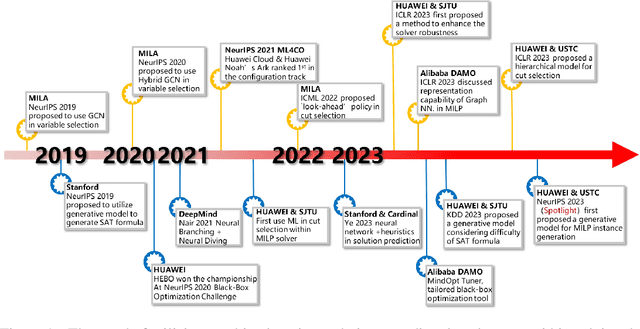
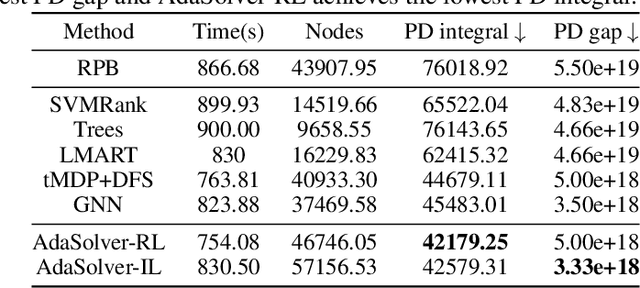

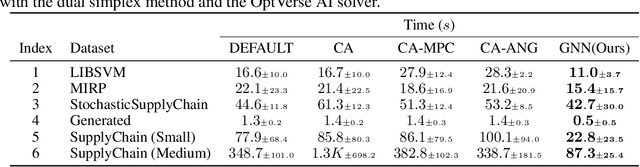
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
A Lipschitz Bandits Approach for Continuous Hyperparameter Optimization
Feb 03, 2023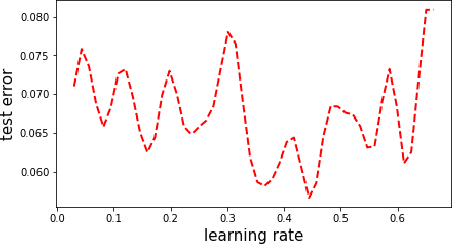



One of the most critical problems in machine learning is HyperParameter Optimization (HPO), since choice of hyperparameters has a significant impact on final model performance. Although there are many HPO algorithms, they either have no theoretical guarantees or require strong assumptions. To this end, we introduce BLiE -- a Lipschitz-bandit-based algorithm for HPO that only assumes Lipschitz continuity of the objective function. BLiE exploits the landscape of the objective function to adaptively search over the hyperparameter space. Theoretically, we show that $(i)$ BLiE finds an $\epsilon$-optimal hyperparameter with $O \left( \frac{1}{\epsilon} \right)^{d_z + \beta}$ total budgets, where $d_z$ and $\beta$ are problem intrinsic; $(ii)$ BLiE is highly parallelizable. Empirically, we demonstrate that BLiE outperforms the state-of-the-art HPO algorithms on benchmark tasks. We also apply BLiE to search for noise schedule of diffusion models. Comparison with the default schedule shows that BLiE schedule greatly improves the sampling speed.
EFMVFL: An Efficient and Flexible Multi-party Vertical Federated Learning without a Third Party
Jan 17, 2022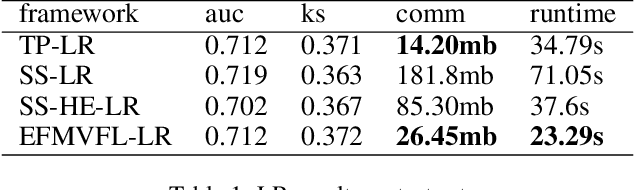
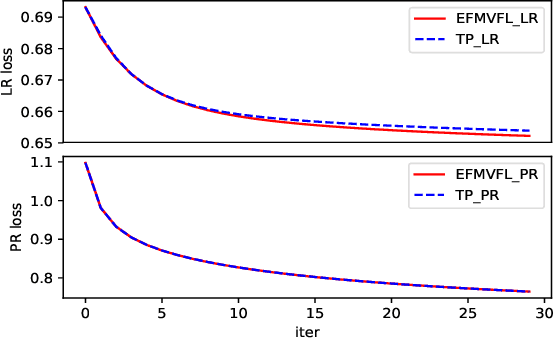
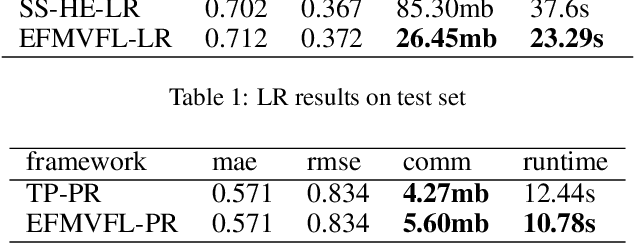
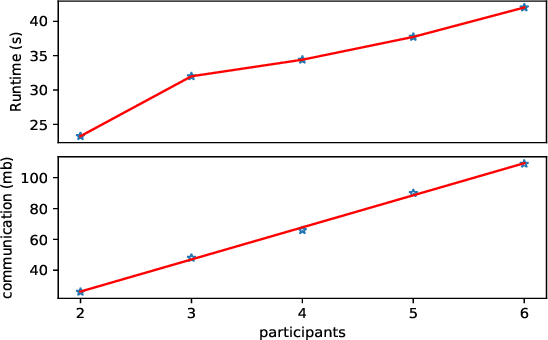
Federated learning allows multiple participants to conduct joint modeling without disclosing their local data. Vertical federated learning (VFL) handles the situation where participants share the same ID space and different feature spaces. In most VFL frameworks, to protect the security and privacy of the participants' local data, a third party is needed to generate homomorphic encryption key pairs and perform decryption operations. In this way, the third party is granted the right to decrypt information related to model parameters. However, it isn't easy to find such a credible entity in the real world. Existing methods for solving this problem are either communication-intensive or unsuitable for multi-party scenarios. By combining secret sharing and homomorphic encryption, we propose a novel VFL framework without a third party called EFMVFL, which supports flexible expansion to multiple participants with low communication overhead and is applicable to generalized linear models. We give instantiations of our framework under logistic regression and Poisson regression. Theoretical analysis and experiments show that our framework is secure, more efficient, and easy to be extended to multiple participants.
On Effective Scheduling of Model-based Reinforcement Learning
Nov 16, 2021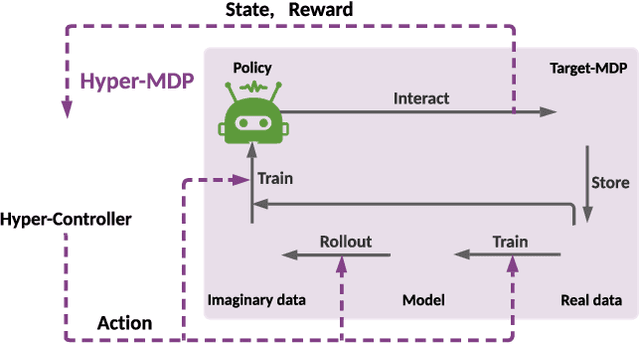
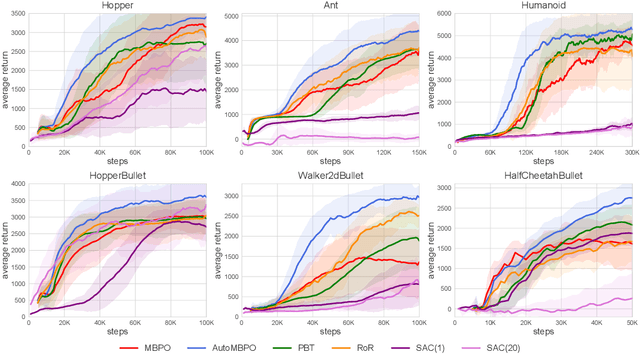

Model-based reinforcement learning has attracted wide attention due to its superior sample efficiency. Despite its impressive success so far, it is still unclear how to appropriately schedule the important hyperparameters to achieve adequate performance, such as the real data ratio for policy optimization in Dyna-style model-based algorithms. In this paper, we first theoretically analyze the role of real data in policy training, which suggests that gradually increasing the ratio of real data yields better performance. Inspired by the analysis, we propose a framework named AutoMBPO to automatically schedule the real data ratio as well as other hyperparameters in training model-based policy optimization (MBPO) algorithm, a representative running case of model-based methods. On several continuous control tasks, the MBPO instance trained with hyperparameters scheduled by AutoMBPO can significantly surpass the original one, and the real data ratio schedule found by AutoMBPO shows consistency with our theoretical analysis.
MOFA: Modular Factorial Design for Hyperparameter Optimization
Nov 18, 2020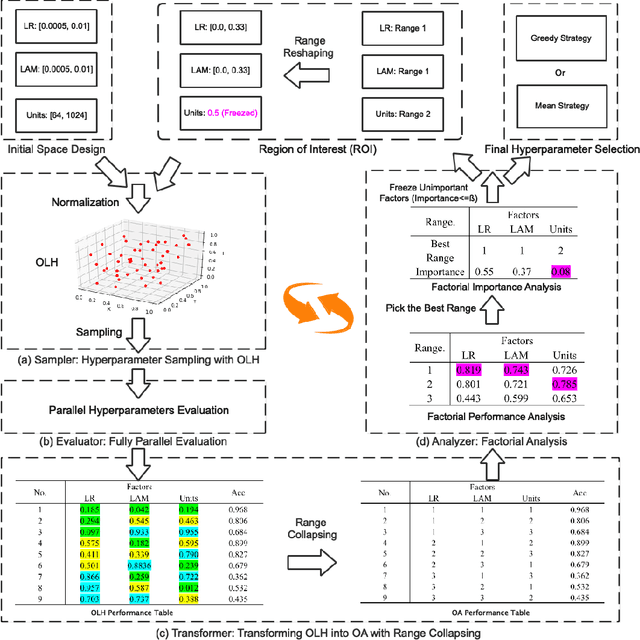
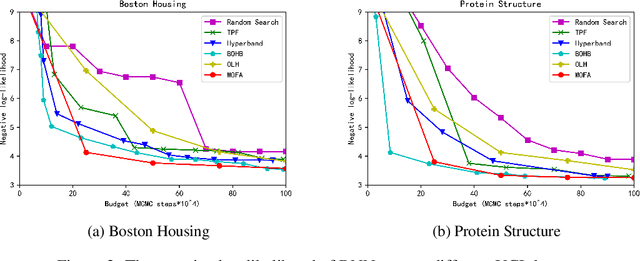
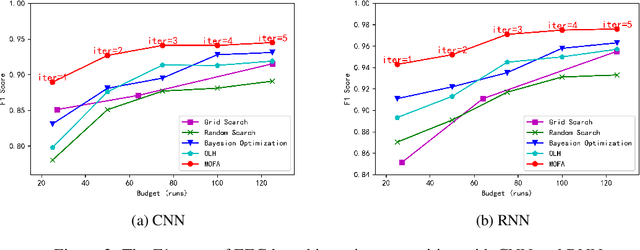
Automated hyperparameter optimization (HPO) has shown great power in many machine learning applications. While existing methods suffer from model selection, parallelism, or sample efficiency, this paper presents a new HPO method, MOdular FActorial Design (MOFA), to address these issues simultaneously. The major idea is to use techniques from Experimental Designs to improve sample efficiency of model-free methods. Particularly, MOFA runs with four modules in each iteration: (1) an Orthogonal Latin Hypercube (OLH)-based sampler preserving both univariate projection uniformity and orthogonality; (2) a highly parallelized evaluator; (3) a transformer to collapse the OLH performance table into a specified Fractional Factorial Design--Orthogonal Array (OA); (4) an analyzer including Factorial Performance Analysis and Factorial Importance Analysis to narrow down the search space. We theoretically and empirically show that MOFA has great advantages over existing model-based and model-free methods.
AABO: Adaptive Anchor Box Optimization for Object Detection via Bayesian Sub-sampling
Jul 18, 2020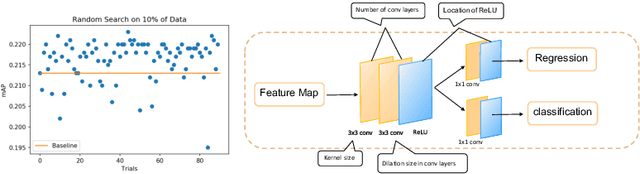
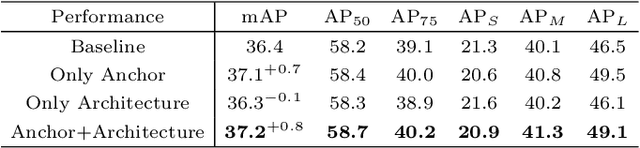
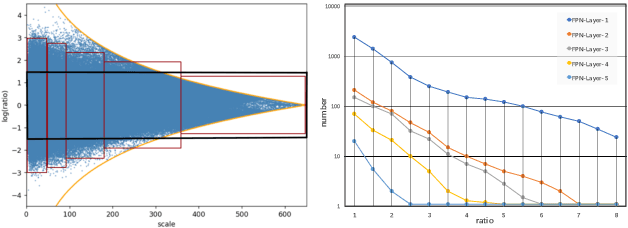

Most state-of-the-art object detection systems follow an anchor-based diagram. Anchor boxes are densely proposed over the images and the network is trained to predict the boxes position offset as well as the classification confidence. Existing systems pre-define anchor box shapes and sizes and ad-hoc heuristic adjustments are used to define the anchor configurations. However, this might be sub-optimal or even wrong when a new dataset or a new model is adopted. In this paper, we study the problem of automatically optimizing anchor boxes for object detection. We first demonstrate that the number of anchors, anchor scales and ratios are crucial factors for a reliable object detection system. By carefully analyzing the existing bounding box patterns on the feature hierarchy, we design a flexible and tight hyper-parameter space for anchor configurations. Then we propose a novel hyper-parameter optimization method named AABO to determine more appropriate anchor boxes for a certain dataset, in which Bayesian Optimization and subsampling method are combined to achieve precise and efficient anchor configuration optimization. Experiments demonstrate the effectiveness of our proposed method on different detectors and datasets, e.g. achieving around 2.4% mAP improvement on COCO, 1.6% on ADE and 1.5% on VG, and the optimal anchors can bring 1.4% to 2.4% mAP improvement on SOTA detectors by only optimizing anchor configurations, e.g. boosting Mask RCNN from 40.3% to 42.3%, and HTC detector from 46.8% to 48.2%.
An Asymptotically Optimal Multi-Armed Bandit Algorithm and Hyperparameter Optimization
Jul 11, 2020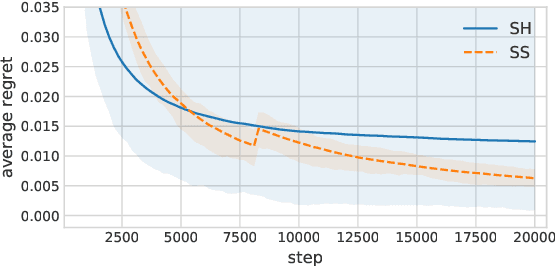
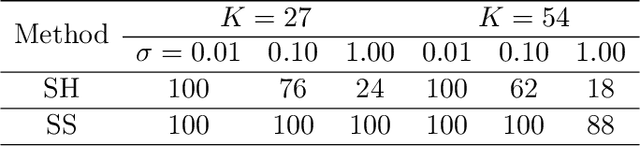

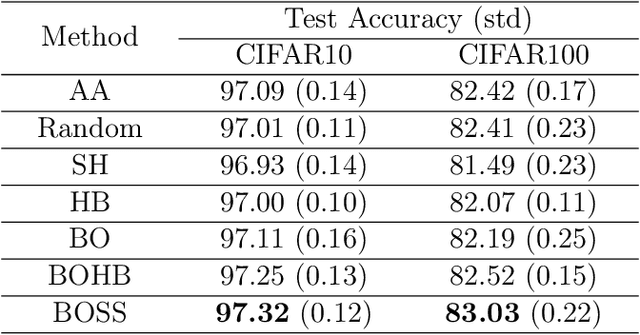
The evaluation of hyperparameters, neural architectures, or data augmentation policies becomes a critical model selection problem in advanced deep learning with a large hyperparameter search space. In this paper, we propose an efficient and robust bandit-based algorithm called Sub-Sampling (SS) in the scenario of hyperparameter search evaluation. It evaluates the potential of hyperparameters by the sub-samples of observations and is theoretically proved to be optimal under the criterion of cumulative regret. We further combine SS with Bayesian Optimization and develop a novel hyperparameter optimization algorithm called BOSS. Empirical studies validate our theoretical arguments of SS and demonstrate the superior performance of BOSS on a number of applications, including Neural Architecture Search (NAS), Data Augmentation (DA), Object Detection (OD), and Reinforcement Learning (RL).
Meta-Learning PAC-Bayes Priors in Model Averaging
Dec 25, 2019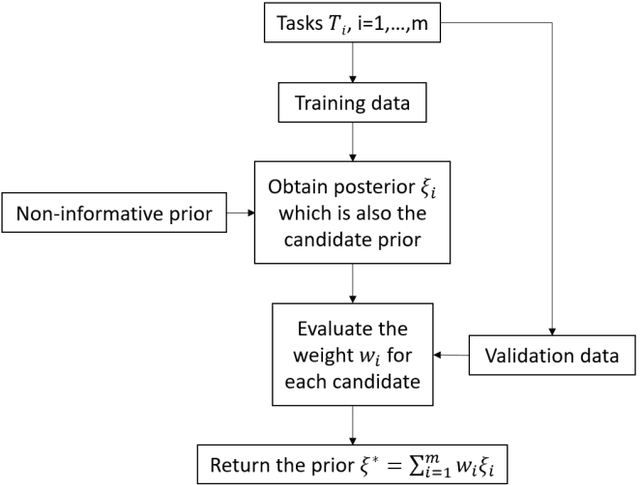

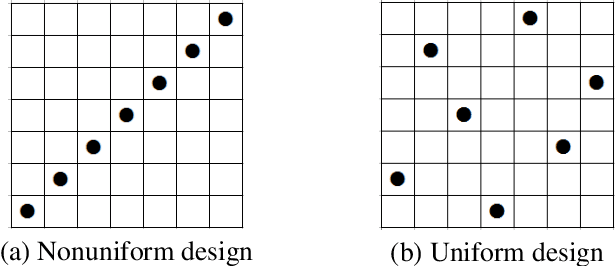
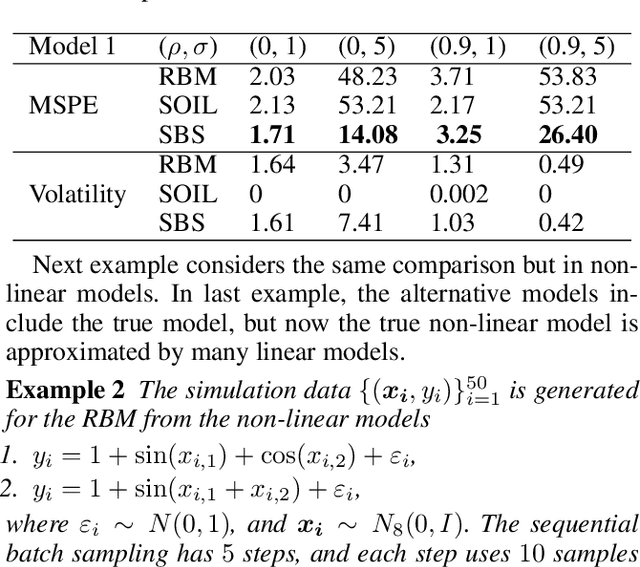
Nowadays model uncertainty has become one of the most important problems in both academia and industry. In this paper, we mainly consider the scenario in which we have a common model set used for model averaging instead of selecting a single final model via a model selection procedure to account for this model's uncertainty to improve reliability and accuracy of inferences. Here one main challenge is to learn the prior over the model set. To tackle this problem, we propose two data-based algorithms to get proper priors for model averaging. One is for meta-learner, the analysts should use historical similar tasks to extract the information about the prior. The other one is for base-learner, a subsampling method is used to deal with the data step by step. Theoretically, an upper bound of risk for our algorithm is presented to guarantee the performance of the worst situation. In practice, both methods perform well in simulations and real data studies, especially with poor quality data.
Pearl's Calculus of Intervention Is Complete
Jun 27, 2012This paper is concerned with graphical criteria that can be used to solve the problem of identifying casual effects from nonexperimental data in a causal Bayesian network structure, i.e., a directed acyclic graph that represents causal relationships. We first review Pearl's work on this topic [Pearl, 1995], in which several useful graphical criteria are presented. Then we present a complete algorithm [Huang and Valtorta, 2006b] for the identifiability problem. By exploiting the completeness of this algorithm, we prove that the three basic do-calculus rules that Pearl presents are complete, in the sense that, if a causal effect is identifiable, there exists a sequence of applications of the rules of the do-calculus that transforms the causal effect formula into a formula that only includes observational quantities.