 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILP-StuDio: MILP Instance Generation via Block Structure Decomposition
Oct 31, 2024



Mixed-integer linear programming (MILP) is one of the most popular mathematical formulations with numerous applications. In practice, improving the performance of MILP solvers often requires a large amount of high-quality data, which can be challenging to collect. Researchers thus turn to generation techniques to generate additional MILP instances. However, existing approaches do not take into account specific block structures -- which are closely related to the problem formulations -- in the constraint coefficient matrices (CCMs) of MILPs. Consequently, they are prone to generate computationally trivial or infeasible instances due to the disruptions of block structures and thus problem formulations. To address this challenge, we propose a novel MILP generation framework, called Block Structure Decomposition (MILP-StuDio), to generate high-quality instances by preserving the block structures. Specifically, MILP-StuDio begins by identifying the blocks in CCMs and decomposing the instances into block units, which serve as the building blocks of MILP instances. We then design three operators to construct new instances by removing, substituting, and appending block units in the original instances, enabling us to generate instances with flexible sizes. An appealing feature of MILP-StuDio is its strong ability to preserve the feasibility and computational hardness of the generated instances. Experiments on the commonly-used benchmarks demonstrate that using instances generated by MILP-StuDio is able to significantly reduce over 10% of the solving time for learning-based solvers.
Deep Symbolic Optimization for Combinatorial Optimization: Accelerating Node Selection by Discovering Potential Heuristics
Jun 14, 2024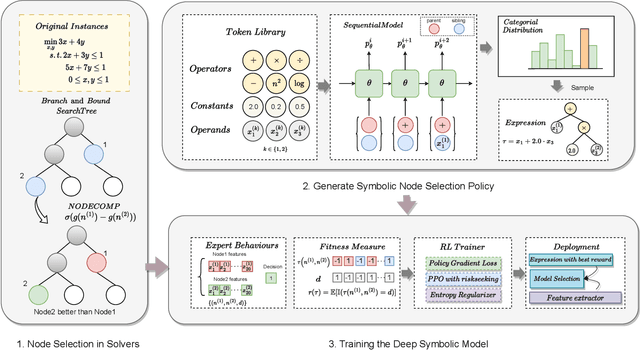
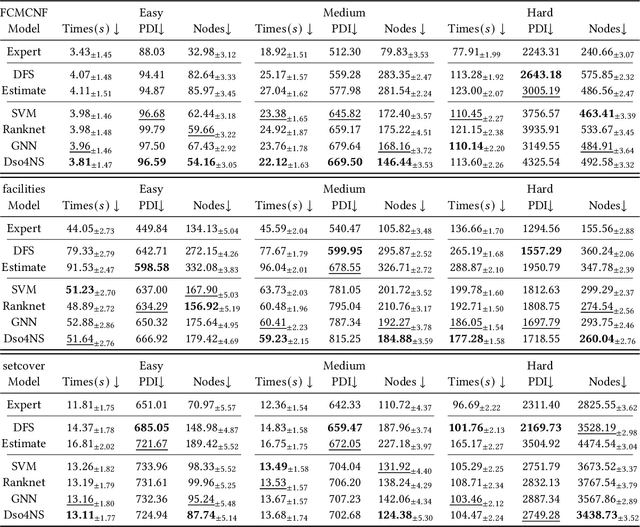
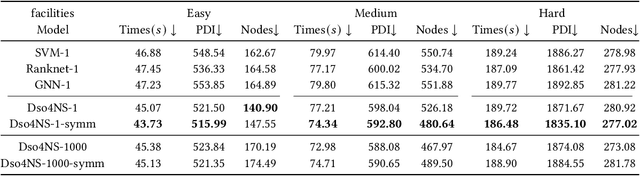
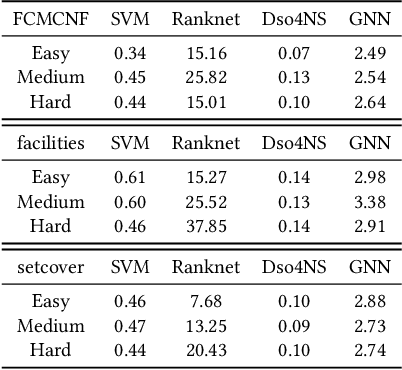
Combinatorial optimization (CO) is one of the most fundamental mathematical models in real-world applications. Traditional CO solvers, such as Branch-and-Bound (B&B) solvers, heavily rely on expert-designed heuristics, which are reliable but require substantial manual tuning. Recent studies have leveraged deep learning (DL) models as an alternative to capture rich feature patterns for improved performance on GPU machines. Nonetheless, the drawbacks of high training and inference costs, as well as limited interpretability, severely hinder the adoption of DL methods in real-world applications. To address these challenges, we propose a novel deep symbolic optimization learning framework that combines their advantages. Specifically, we focus on the node selection module within B&B solvers -- namely, deep symbolic optimization for node selection (Dso4NS). With data-driven approaches, Dso4NS guides the search for mathematical expressions within the high-dimensional discrete symbolic space and then incorporates the highest-performing mathematical expressions into a solver. The data-driven model captures the rich feature information in the input data and generates symbolic expressions, while the expressions deployed in solvers enable fast inference with high interpretability. Experiments demonstrate the effectiveness of Dso4NS in learning high-quality expressions, outperforming existing approaches on a CPU machine. Encouragingly, the learned CPU-based policies consistently achieve performance comparable to state-of-the-art GPU-based approaches.
Learning to Cut via Hierarchical Sequence/Set Model for Efficient Mixed-Integer Programming
Apr 19, 2024



Cutting planes (cuts) play an important role in solving mixed-integer linear programs (MILPs), which formulate many important real-world applications. Cut selection heavily depends on (P1) which cuts to prefer and (P2) how many cuts to select. Although modern MILP solvers tackle (P1)-(P2) by human-designed heuristics, machine learning carries the potential to learn more effective heuristics. However, many existing learning-based methods learn which cuts to prefer, neglecting the importance of learning how many cuts to select. Moreover, we observe that (P3) what order of selected cuts to prefer significantly impacts the efficiency of MILP solvers as well. To address these challenges, we propose a novel hierarchical sequence/set model (HEM) to learn cut selection policies. Specifically, HEM is a bi-level model: (1) a higher-level module that learns how many cuts to select, (2) and a lower-level module -- that formulates the cut selection as a sequence/set to sequence learning problem -- to learn policies selecting an ordered subset with the cardinality determined by the higher-level module. To the best of our knowledge, HEM is the first data-driven methodology that well tackles (P1)-(P3) simultaneously. Experiments demonstrate that HEM significantly improves the efficiency of solving MILPs on eleven challenging MILP benchmarks, including two Huawei's real problems.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024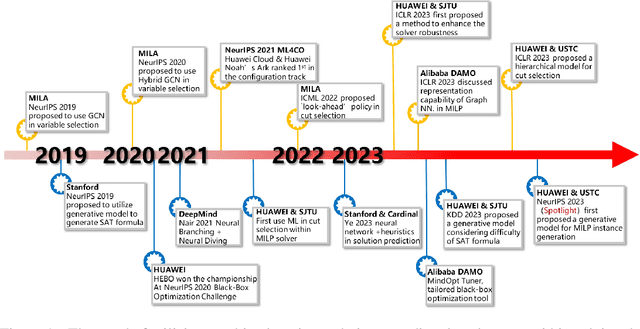

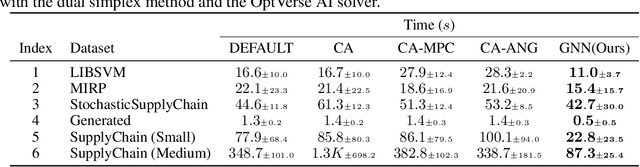
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
State Sequences Prediction via Fourier Transform for Representation Learning
Oct 24, 2023While deep reinforcement learning (RL) has been demonstrated effective in solving complex control tasks, sample efficiency remains a key challenge due to the large amounts of data required for remarkable performance. Existing research explores the application of representation learning for data-efficient RL, e.g., learning predictive representations by predicting long-term future states. However, many existing methods do not fully exploit the structural information inherent in sequential state signals, which can potentially improve the quality of long-term decision-making but is difficult to discern in the time domain. To tackle this problem, we propose State Sequences Prediction via Fourier Transform (SPF), a novel method that exploits the frequency domain of state sequences to extract the underlying patterns in time series data for learning expressive representations efficiently. Specifically, we theoretically analyze the existence of structural information in state sequences, which is closely related to policy performance and signal regularity, and then propose to predict the Fourier transform of infinite-step future state sequences to extract such information. One of the appealing features of SPF is that it is simple to implement while not requiring storage of infinite-step future states as prediction targets. Experiments demonstrate that the proposed method outperforms several state-of-the-art algorithms in terms of both sample efficiency and performance.
Promoting Generalization for Exact Solvers via Adversarial Instance Augmentation
Oct 22, 2023



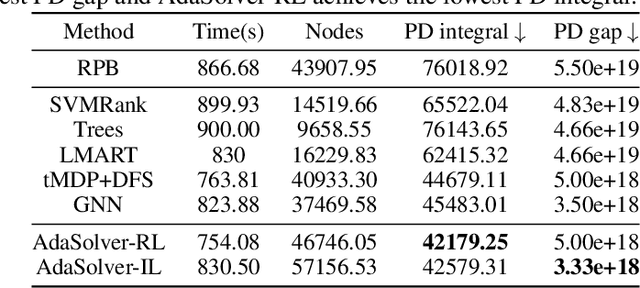
Machine learning has been successfully applied to improve the efficiency of Mixed-Integer Linear Programming (MILP) solvers. However, the learning-based solvers often suffer from severe performance degradation on unseen MILP instances -- especially on large-scale instances from a perturbed environment -- due to the limited diversity of training distributions. To tackle this problem, we propose a novel approach, which is called Adversarial Instance Augmentation and does not require to know the problem type for new instance generation, to promote data diversity for learning-based branching modules in the branch-and-bound (B&B) Solvers (AdaSolver). We use the bipartite graph representations for MILP instances and obtain various perturbed instances to regularize the solver by augmenting the graph structures with a learned augmentation policy. The major technical contribution of AdaSolver is that we formulate the non-differentiable instance augmentation as a contextual bandit problem and adversarially train the learning-based solver and augmentation policy, enabling efficient gradient-based training of the augmentation policy. To the best of our knowledge, AdaSolver is the first general and effective framework for understanding and improving the generalization of both imitation-learning-based (IL-based) and reinforcement-learning-based (RL-based) B&B solvers. Extensive experiments demonstrate that by producing various augmented instances, AdaSolver leads to a remarkable efficiency improvement across various distributions.
Accelerate Presolve in Large-Scale Linear Programming via Reinforcement Learning
Oct 18, 2023



Large-scale LP problems from industry usually contain much redundancy that severely hurts the efficiency and reliability of solving LPs, making presolve (i.e., the problem simplification module) one of the most critical components in modern LP solvers. However, how to design high-quality presolve routines -- that is, the program determining (P1) which presolvers to select, (P2) in what order to execute, and (P3) when to stop -- remains a highly challenging task due to the extensive requirements on expert knowledge and the large search space. Due to the sequential decision property of the task and the lack of expert demonstrations, we propose a simple and efficient reinforcement learning (RL) framework -- namely, reinforcement learning for presolve (RL4Presolve) -- to tackle (P1)-(P3) simultaneously. Specifically, we formulate the routine design task as a Markov decision process and propose an RL framework with adaptive action sequences to generate high-quality presolve routines efficiently. Note that adaptive action sequences help learn complex behaviors efficiently and adapt to various benchmarks. Experiments on two solvers (open-source and commercial) and eight benchmarks (real-world and synthetic) demonstrate that RL4Presolve significantly and consistently improves the efficiency of solving large-scale LPs, especially on benchmarks from industry. Furthermore, we optimize the hard-coded presolve routines in LP solvers by extracting rules from learned policies for simple and efficient deployment to Huawei's supply chain. The results show encouraging economic and academic potential for incorporating machine learning to modern solvers.
Learning Cut Selection for Mixed-Integer Linear Programming via Hierarchical Sequence Model
Feb 01, 2023



Cutting planes (cuts) are important for solving mixed-integer linear programs (MILPs), which formulate a wide range of important real-world applications. Cut selection -- which aims to select a proper subset of the candidate cuts to improve the efficiency of solving MILPs -- heavily depends on (P1) which cuts should be preferred, and (P2) how many cuts should be selected. Although many modern MILP solvers tackle (P1)-(P2) by manually designed heuristics, machine learning offers a promising approach to learn more effective heuristics from MILPs collected from specific applications. However, many existing learning-based methods focus on learning which cuts should be preferred, neglecting the importance of learning the number of cuts that should be selected. Moreover, we observe from extensive empirical results that (P3) what order of selected cuts should be preferred has a significant impact on the efficiency of solving MILPs as well. To address this challenge, we propose a novel hierarchical sequence model (HEM) to learn cut selection policies via reinforcement learning. Specifically, HEM consists of a two-level model: (1) a higher-level model to learn the number of cuts that should be selected, (2) and a lower-level model -- that formulates the cut selection task as a sequence to sequence learning problem -- to learn policies selecting an ordered subset with the size determined by the higher-level model. To the best of our knowledge, HEM is the first method that can tackle (P1)-(P3) in cut selection simultaneously from a data-driven perspective. Experiments show that HEM significantly improves the efficiency of solving MILPs compared to human-designed and learning-based baselines on both synthetic and large-scale real-world MILPs, including MIPLIB 2017. Moreover, experiments demonstrate that HEM well generalizes to MILPs that are significantly larger than those seen during training.
Learning Robust Policy against Disturbance in Transition Dynamics via State-Conservative Policy Optimization
Dec 20, 2021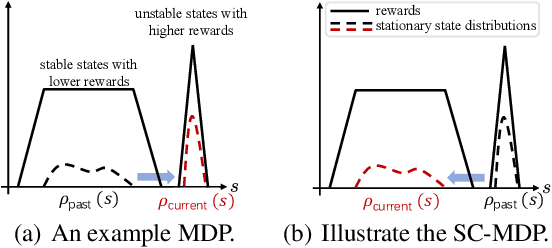
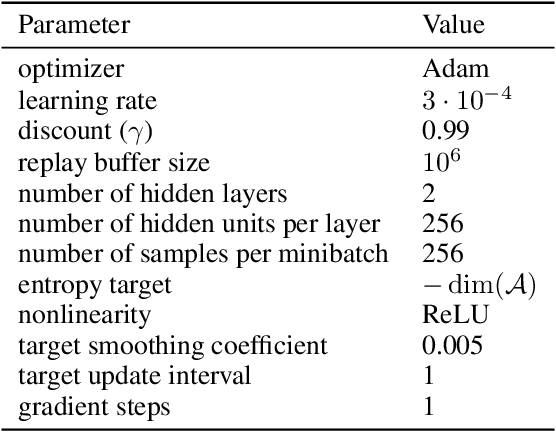


Deep reinforcement learning algorithms can perform poorly in real-world tasks due to the discrepancy between source and target environments. This discrepancy is commonly viewed as the disturbance in transition dynamics. Many existing algorithms learn robust policies by modeling the disturbance and applying it to source environments during training, which usually requires prior knowledge about the disturbance and control of simulators. However, these algorithms can fail in scenarios where the disturbance from target environments is unknown or is intractable to model in simulators. To tackle this problem, we propose a novel model-free actor-critic algorithm -- namely, state-conservative policy optimization (SCPO) -- to learn robust policies without modeling the disturbance in advance. Specifically, SCPO reduces the disturbance in transition dynamics to that in state space and then approximates it by a simple gradient-based regularizer. The appealing features of SCPO include that it is simple to implement and does not require additional knowledge about the disturbance or specially designed simulators. Experiments in several robot control tasks demonstrate that SCPO learns robust policies against the disturbance in transition dynamics.