 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSMC-Pose: Frequency and Spatial Fusion with Multiscale Self-calibration for Cattle Mounting Pose Estimation
Mar 17, 2026Mounting posture is an important visual indicator of estrus in dairy cattle. However, achieving reliable mounting pose estimation in real-world environments remains challenging due to cluttered backgrounds and frequent inter-animal occlusion. We present FSMC-Pose, a top-down framework that integrates a lightweight frequency-spatial fusion backbone, CattleMountNet, and a multiscale self-calibration head, SC2Head. Specifically, we design two algorithmic components for CattleMountNet: the Spatial Frequency Enhancement Block (SFEBlock) and the Receptive Aggregation Block (RABlock). SFEBlock separates cattle from cluttered backgrounds, while RABlock captures multiscale contextual information. The Spatial-Channel Self-Calibration Head (SC2Head) attends to spatial and channel dependencies and introduces a self-calibration branch to mitigate structural misalignment under inter-animal overlap. We construct a mounting dataset, MOUNT-Cattle, covering 1176 mounting instances, which follows the COCO format and supports drop-in training across pose estimation models. Using a comprehensive dataset that combines MOUNT-Cattle with the public NWAFU-Cattle dataset, FSMC-Pose achieves higher accuracy than strong baselines, with markedly lower computational and parameter costs, while maintaining real-time inference on commodity GPUs. Extensive experiments and qualitative analyses show that FSMC-Pose effectively captures and estimates cattle mounting pose in complex and cluttered environments. Dataset and code are available at https://github.com/elianafang/FSMC-Pose.
HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Feb 17, 2026Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
Short Chains, Deep Thoughts: Balancing Reasoning Efficiency and Intra-Segment Capability via Split-Merge Optimization
Feb 03, 2026While Large Reasoning Models (LRMs) have demonstrated impressive capabilities in solving complex tasks through the generation of long reasoning chains, this reliance on verbose generation results in significant latency and computational overhead. To address these challenges, we propose \textbf{CoSMo} (\textbf{Co}nsistency-Guided \textbf{S}plit-\textbf{M}erge \textbf{O}ptimization), a framework designed to eliminate structural redundancy rather than indiscriminately restricting token volume. Specifically, CoSMo utilizes a split-merge algorithm that dynamically refines reasoning chains by merging redundant segments and splitting logical gaps to ensure coherence. We then employ structure-aligned reinforcement learning with a novel segment-level budget to supervise the model in maintaining efficient reasoning structures throughout training. Extensive experiments across multiple benchmarks and backbones demonstrate that CoSMo achieves superior performance, improving accuracy by \textbf{3.3} points while reducing segment usage by \textbf{28.7\%} on average compared to reasoning efficiency baselines.
HyperTree Planning: Enhancing LLM Reasoning via Hierarchical Thinking
May 05, 2025Recent advancements have significantly enhanced the performance of large language models (LLMs) in tackling complex reasoning tasks, achieving notable success in domains like mathematical and logical reasoning. However, these methods encounter challenges with complex planning tasks, primarily due to extended reasoning steps, diverse constraints, and the challenge of handling multiple distinct sub-tasks. To address these challenges, we propose HyperTree Planning (HTP), a novel reasoning paradigm that constructs hypertree-structured planning outlines for effective planning. The hypertree structure enables LLMs to engage in hierarchical thinking by flexibly employing the divide-and-conquer strategy, effectively breaking down intricate reasoning steps, accommodating diverse constraints, and managing multiple distinct sub-tasks in a well-organized manner. We further introduce an autonomous planning framework that completes the planning process by iteratively refining and expanding the hypertree-structured planning outlines. Experiments demonstrate the effectiveness of HTP, achieving state-of-the-art accuracy on the TravelPlanner benchmark with Gemini-1.5-Pro, resulting in a 3.6 times performance improvement over o1-preview.
Accelerating Large Language Model Reasoning via Speculative Search
May 03, 2025Tree-search-based reasoning methods have significantly enhanced the reasoning capability of large language models (LLMs) by facilitating the exploration of multiple intermediate reasoning steps, i.e., thoughts. However, these methods suffer from substantial inference latency, as they have to generate numerous reasoning thoughts, severely limiting LLM applicability. To address this challenge, we propose a novel Speculative Search (SpecSearch) framework that significantly accelerates LLM reasoning by optimizing thought generation. Specifically, SpecSearch utilizes a small model to strategically collaborate with a large model at both thought and token levels, efficiently generating high-quality reasoning thoughts. The major pillar of SpecSearch is a novel quality-preserving rejection mechanism, which effectively filters out thoughts whose quality falls below that of the large model's outputs. Moreover, we show that SpecSearch preserves comparable reasoning quality to the large model. Experiments on both the Qwen and Llama models demonstrate that SpecSearch significantly outperforms state-of-the-art approaches, achieving up to 2.12$\times$ speedup with comparable reasoning quality.
AttentionPredictor: Temporal Pattern Matters for Efficient LLM Inference
Feb 06, 2025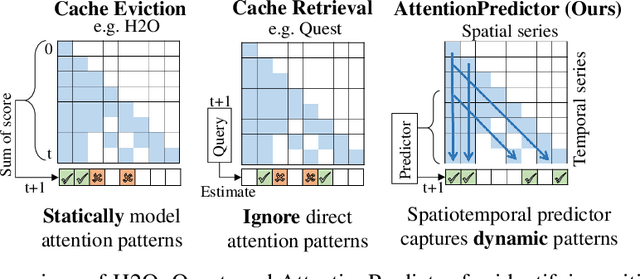

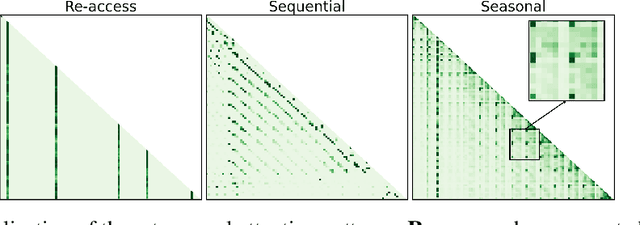

With the development of large language models (LLMs), efficient inference through Key-Value (KV) cache compression has attracted considerable attention, especially for long-context generation. To compress the KV cache, recent methods identify critical KV tokens through heuristic ranking with attention scores. However, these methods often struggle to accurately determine critical tokens as they neglect the \textit{temporal patterns} in attention scores, resulting in a noticeable degradation in LLM performance. To address this challenge, we propose AttentionPredictor, which is the first learning-based critical token identification approach. Specifically, AttentionPredictor learns a lightweight convolution model to capture spatiotemporal patterns and predict the next-token attention score. An appealing feature of AttentionPredictor is that it accurately predicts the attention score while consuming negligible memory. Moreover, we propose a cross-token critical cache prefetching framework that hides the token estimation time overhead to accelerate the decoding stage. By retaining most of the attention information, AttentionPredictor achieves 16$\times$ KV cache compression with comparable LLM performance, significantly outperforming the state-of-the-art.
Learning to Cut via Hierarchical Sequence/Set Model for Efficient Mixed-Integer Programming
Apr 19, 2024



Cutting planes (cuts) play an important role in solving mixed-integer linear programs (MILPs), which formulate many important real-world applications. Cut selection heavily depends on (P1) which cuts to prefer and (P2) how many cuts to select. Although modern MILP solvers tackle (P1)-(P2) by human-designed heuristics, machine learning carries the potential to learn more effective heuristics. However, many existing learning-based methods learn which cuts to prefer, neglecting the importance of learning how many cuts to select. Moreover, we observe that (P3) what order of selected cuts to prefer significantly impacts the efficiency of MILP solvers as well. To address these challenges, we propose a novel hierarchical sequence/set model (HEM) to learn cut selection policies. Specifically, HEM is a bi-level model: (1) a higher-level module that learns how many cuts to select, (2) and a lower-level module -- that formulates the cut selection as a sequence/set to sequence learning problem -- to learn policies selecting an ordered subset with the cardinality determined by the higher-level module. To the best of our knowledge, HEM is the first data-driven methodology that well tackles (P1)-(P3) simultaneously. Experiments demonstrate that HEM significantly improves the efficiency of solving MILPs on eleven challenging MILP benchmarks, including two Huawei's real problems.
Learning to Stop Cut Generation for Efficient Mixed-Integer Linear Programming
Feb 02, 2024



Cutting planes (cuts) play an important role in solving mixed-integer linear programs (MILPs), as they significantly tighten the dual bounds and improve the solving performance. A key problem for cuts is when to stop cuts generation, which is important for the efficiency of solving MILPs. However, many modern MILP solvers employ hard-coded heuristics to tackle this problem, which tends to neglect underlying patterns among MILPs from certain applications. To address this challenge, we formulate the cuts generation stopping problem as a reinforcement learning problem and propose a novel hybrid graph representation model (HYGRO) to learn effective stopping strategies. An appealing feature of HYGRO is that it can effectively capture both the dynamic and static features of MILPs, enabling dynamic decision-making for the stopping strategies. To the best of our knowledge, HYGRO is the first data-driven method to tackle the cuts generation stopping problem. By integrating our approach with modern solvers, experiments demonstrate that HYGRO significantly improves the efficiency of solving MILPs compared to competitive baselines, achieving up to 31% improvement.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024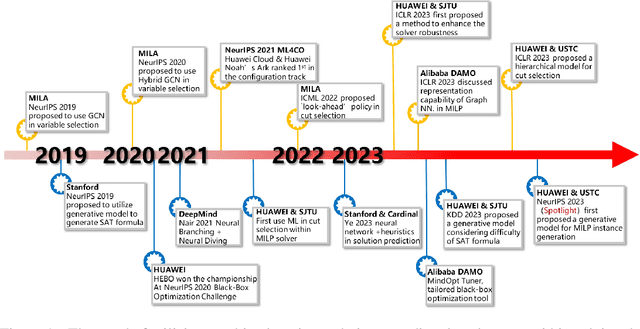

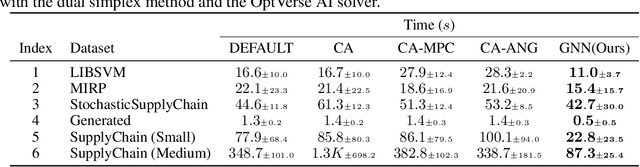
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Accelerate Presolve in Large-Scale Linear Programming via Reinforcement Learning
Oct 18, 2023



Large-scale LP problems from industry usually contain much redundancy that severely hurts the efficiency and reliability of solving LPs, making presolve (i.e., the problem simplification module) one of the most critical components in modern LP solvers. However, how to design high-quality presolve routines -- that is, the program determining (P1) which presolvers to select, (P2) in what order to execute, and (P3) when to stop -- remains a highly challenging task due to the extensive requirements on expert knowledge and the large search space. Due to the sequential decision property of the task and the lack of expert demonstrations, we propose a simple and efficient reinforcement learning (RL) framework -- namely, reinforcement learning for presolve (RL4Presolve) -- to tackle (P1)-(P3) simultaneously. Specifically, we formulate the routine design task as a Markov decision process and propose an RL framework with adaptive action sequences to generate high-quality presolve routines efficiently. Note that adaptive action sequences help learn complex behaviors efficiently and adapt to various benchmarks. Experiments on two solvers (open-source and commercial) and eight benchmarks (real-world and synthetic) demonstrate that RL4Presolve significantly and consistently improves the efficiency of solving large-scale LPs, especially on benchmarks from industry. Furthermore, we optimize the hard-coded presolve routines in LP solvers by extracting rules from learned policies for simple and efficient deployment to Huawei's supply chain. The results show encouraging economic and academic potential for incorporating machine learning to modern solvers.