 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApollo-MILP: An Alternating Prediction-Correction Neural Solving Framework for Mixed-Integer Linear Programming
Mar 03, 2025Leveraging machine learning (ML) to predict an initial solution for mixed-integer linear programming (MILP) has gained considerable popularity in recent years. These methods predict a solution and fix a subset of variables to reduce the problem dimension. Then, they solve the reduced problem to obtain the final solutions. However, directly fixing variable values can lead to low-quality solutions or even infeasible reduced problems if the predicted solution is not accurate enough. To address this challenge, we propose an Alternating prediction-correction neural solving framework (Apollo-MILP) that can identify and select accurate and reliable predicted values to fix. In each iteration, Apollo-MILP conducts a prediction step for the unfixed variables, followed by a correction step to obtain an improved solution (called reference solution) through a trust-region search. By incorporating the predicted and reference solutions, we introduce a novel Uncertainty-based Error upper BOund (UEBO) to evaluate the uncertainty of the predicted values and fix those with high confidence. A notable feature of Apollo-MILP is the superior ability for problem reduction while preserving optimality, leading to high-quality final solutions. Experiments on commonly used benchmarks demonstrate that our proposed Apollo-MILP significantly outperforms other ML-based approaches in terms of solution quality, achieving over a 50% reduction in the solution gap.
BPP-Search: Enhancing Tree of Thought Reasoning for Mathematical Modeling Problem Solving
Nov 26, 2024



LLMs exhibit advanced reasoning capabilities, offering the potential to transform natural language questions into mathematical models. However, existing open-source operations research datasets lack detailed annotations of the modeling process, such as variable definitions, focusing solely on objective values, which hinders reinforcement learning applications. To address this, we release the StructuredOR dataset, annotated with comprehensive labels that capture the complete mathematical modeling process. We further propose BPP-Search, a algorithm that integrates reinforcement learning into a tree-of-thought structure using Beam search, a Process reward model, and a pairwise Preference algorithm. This approach enables efficient exploration of tree structures, avoiding exhaustive search while improving accuracy. Extensive experiments on StructuredOR, NL4OPT, and MAMO-ComplexLP datasets show that BPP-Search significantly outperforms state-of-the-art methods, including Chain-of-Thought, Self-Consistency, and Tree-of-Thought. In tree-based reasoning, BPP-Search also surpasses Process Reward Model combined with Greedy or Beam Search, demonstrating superior accuracy and efficiency, and enabling faster retrieval of correct solutions.
Learning to Cut via Hierarchical Sequence/Set Model for Efficient Mixed-Integer Programming
Apr 19, 2024



Cutting planes (cuts) play an important role in solving mixed-integer linear programs (MILPs), which formulate many important real-world applications. Cut selection heavily depends on (P1) which cuts to prefer and (P2) how many cuts to select. Although modern MILP solvers tackle (P1)-(P2) by human-designed heuristics, machine learning carries the potential to learn more effective heuristics. However, many existing learning-based methods learn which cuts to prefer, neglecting the importance of learning how many cuts to select. Moreover, we observe that (P3) what order of selected cuts to prefer significantly impacts the efficiency of MILP solvers as well. To address these challenges, we propose a novel hierarchical sequence/set model (HEM) to learn cut selection policies. Specifically, HEM is a bi-level model: (1) a higher-level module that learns how many cuts to select, (2) and a lower-level module -- that formulates the cut selection as a sequence/set to sequence learning problem -- to learn policies selecting an ordered subset with the cardinality determined by the higher-level module. To the best of our knowledge, HEM is the first data-driven methodology that well tackles (P1)-(P3) simultaneously. Experiments demonstrate that HEM significantly improves the efficiency of solving MILPs on eleven challenging MILP benchmarks, including two Huawei's real problems.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024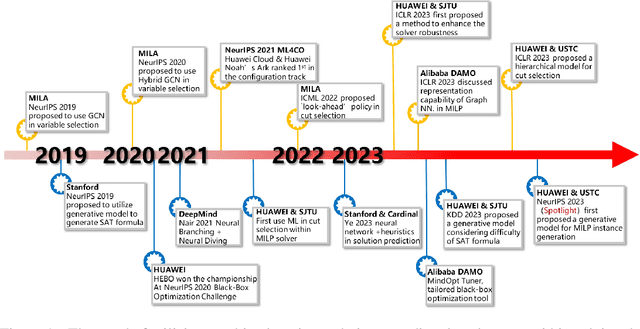

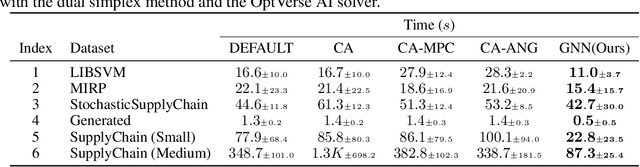
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
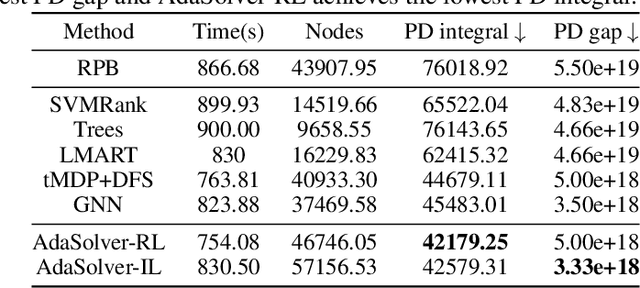
Accelerate Presolve in Large-Scale Linear Programming via Reinforcement Learning
Oct 18, 2023



Large-scale LP problems from industry usually contain much redundancy that severely hurts the efficiency and reliability of solving LPs, making presolve (i.e., the problem simplification module) one of the most critical components in modern LP solvers. However, how to design high-quality presolve routines -- that is, the program determining (P1) which presolvers to select, (P2) in what order to execute, and (P3) when to stop -- remains a highly challenging task due to the extensive requirements on expert knowledge and the large search space. Due to the sequential decision property of the task and the lack of expert demonstrations, we propose a simple and efficient reinforcement learning (RL) framework -- namely, reinforcement learning for presolve (RL4Presolve) -- to tackle (P1)-(P3) simultaneously. Specifically, we formulate the routine design task as a Markov decision process and propose an RL framework with adaptive action sequences to generate high-quality presolve routines efficiently. Note that adaptive action sequences help learn complex behaviors efficiently and adapt to various benchmarks. Experiments on two solvers (open-source and commercial) and eight benchmarks (real-world and synthetic) demonstrate that RL4Presolve significantly and consistently improves the efficiency of solving large-scale LPs, especially on benchmarks from industry. Furthermore, we optimize the hard-coded presolve routines in LP solvers by extracting rules from learned policies for simple and efficient deployment to Huawei's supply chain. The results show encouraging economic and academic potential for incorporating machine learning to modern solvers.
Efficient Gaussian Process Classification-based Physical-Layer Authentication with Configurable Fingerprints for 6G-Enabled IoT
Jul 23, 2023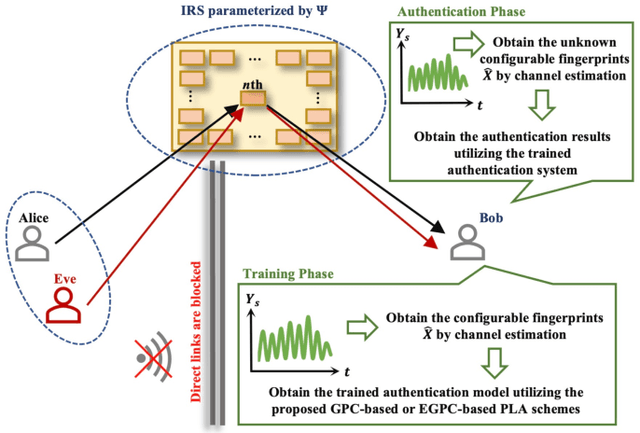
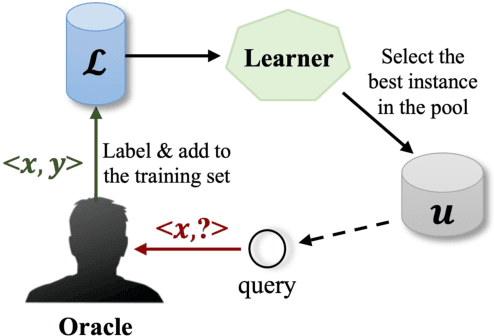
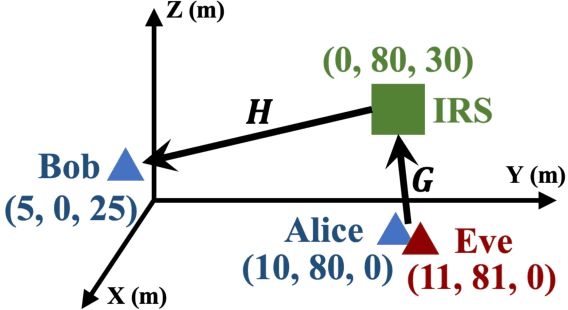
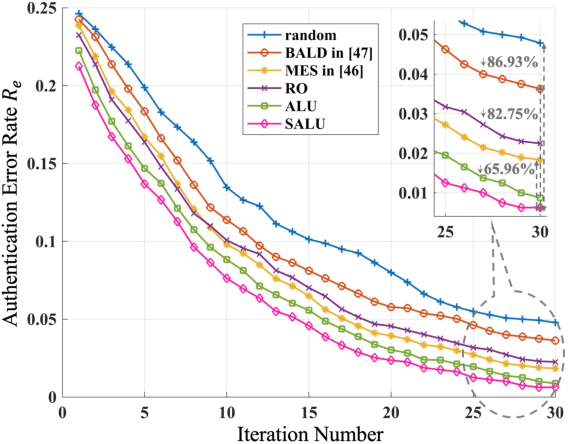
Physical-Layer Authentication (PLA) has been recently believed as an endogenous-secure and energy-efficient technique to recognize IoT terminals. However, the major challenge of applying the state-of-the-art PLA schemes directly to 6G-enabled IoT is the inaccurate channel fingerprint estimation in low Signal-Noise Ratio (SNR) environments, which will greatly influence the reliability and robustness of PLA. To tackle this issue, we propose a configurable-fingerprint-based PLA architecture through Intelligent Reflecting Surface (IRS) that helps create an alternative wireless transmission path to provide more accurate fingerprints. According to Baye's theorem, we propose a Gaussian Process Classification (GPC)-based PLA scheme, which utilizes the Expectation Propagation (EP) method to obtain the identities of unknown fingerprints. Considering that obtaining sufficient labeled fingerprint samples to train the GPC-based authentication model is challenging for future 6G systems, we further extend the GPC-based PLA to the Efficient-GPC (EGPC)-based PLA through active learning, which requires fewer labeled fingerprints and is more feasible. We also propose three fingerprint selecting algorithms to choose fingerprints, whose identities are queried to the upper-layers authentication mechanisms. For this reason, the proposed EGPC-based scheme is also a lightweight cross-layer authentication method to offer a superior security level. The simulations conducted on synthetic datasets demonstrate that the IRS-assisted scheme reduces the authentication error rate by 98.69% compared to the non-IRS-based scheme. Additionally, the proposed fingerprint selection algorithms reduce the authentication error rate by 65.96% to 86.93% and 45.45% to 70.00% under perfect and imperfect channel estimation conditions, respectively, when compared with baseline algorithms.
Learning to Reformulate for Linear Programming
Jan 17, 2022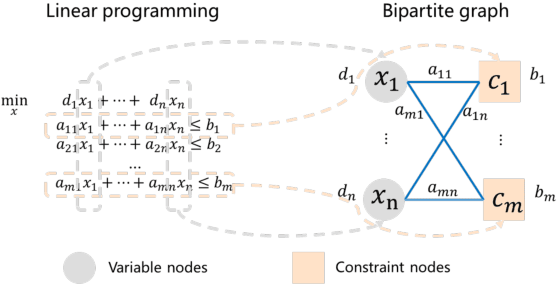

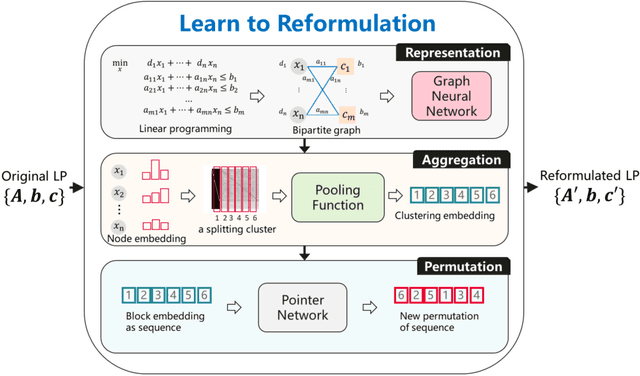
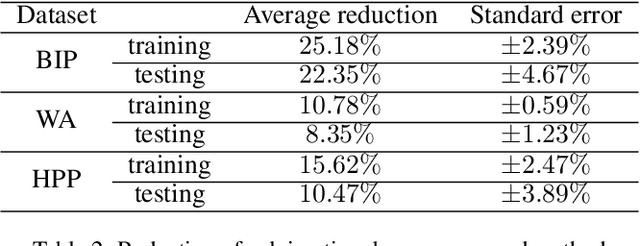
It has been verified that the linear programming (LP) is able to formulate many real-life optimization problems, which can obtain the optimum by resorting to corresponding solvers such as OptVerse, Gurobi and CPLEX. In the past decades, a serial of traditional operation research algorithms have been proposed to obtain the optimum of a given LP in a fewer solving time. Recently, there is a trend of using machine learning (ML) techniques to improve the performance of above solvers. However, almost no previous work takes advantage of ML techniques to improve the performance of solver from the front end, i.e., the modeling (or formulation). In this paper, we are the first to propose a reinforcement learning-based reformulation method for LP to improve the performance of solving process. Using an open-source solver COIN-OR LP (CLP) as an environment, we implement the proposed method over two public research LP datasets and one large-scale LP dataset collected from practical production planning scenario. The evaluation results suggest that the proposed method can effectively reduce both the solving iteration number ($25\%\downarrow$) and the solving time ($15\%\downarrow$) over above datasets in average, compared to directly solving the original LP instances.