 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning with Adaptive Behavior Regularization
Nov 15, 2022



Offline reinforcement learning (RL) defines a sample-efficient learning paradigm, where a policy is learned from static and previously collected datasets without additional interaction with the environment. The major obstacle to offline RL is the estimation error arising from evaluating the value of out-of-distribution actions. To tackle this problem, most existing offline RL methods attempt to acquire a policy both ``close" to the behaviors contained in the dataset and sufficiently improved over them, which requires a trade-off between two possibly conflicting targets. In this paper, we propose a novel approach, which we refer to as adaptive behavior regularization (ABR), to balance this critical trade-off. By simply utilizing a sample-based regularization, ABR enables the policy to adaptively adjust its optimization objective between cloning and improving over the policy used to generate the dataset. In the evaluation on D4RL datasets, a widely adopted benchmark for offline reinforcement learning, ABR can achieve improved or competitive performance compared to existing state-of-the-art algorithms.
Yordle: An Efficient Imitation Learning for Branch and Bound
Feb 02, 2022



Combinatorial optimization problems have aroused extensive research interests due to its huge application potential. In practice, there are highly redundant patterns and characteristics during solving the combinatorial optimization problem, which can be captured by machine learning models. Thus, the 2021 NeurIPS Machine Learning for Combinatorial Optimization (ML4CO) competition is proposed with the goal of improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components with machine learning techniques. This work presents our solution and insights gained by team qqy in the dual task of the competition. Our solution is a highly efficient imitation learning framework for performance improvement of Branch and Bound (B&B), named Yordle. It employs a hybrid sampling method and an efficient data selection method, which not only accelerates the model training but also improves the decision quality during branching variable selection. In our experiments, Yordle greatly outperforms the baseline algorithm adopted by the competition while requiring significantly less time and amounts of data to train the decision model. Specifically, we use only 1/4 of the amount of data compared to that required for the baseline algorithm, to achieve around 50% higher score than baseline algorithm. The proposed framework Yordle won the championship of the student leaderboard.
Learning to Reformulate for Linear Programming
Jan 17, 2022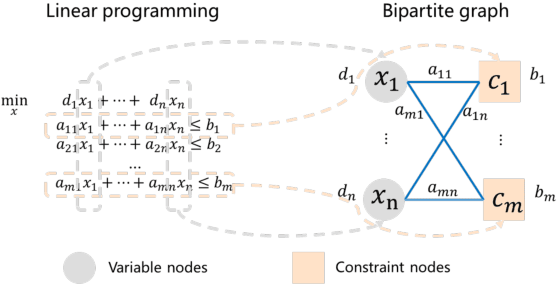

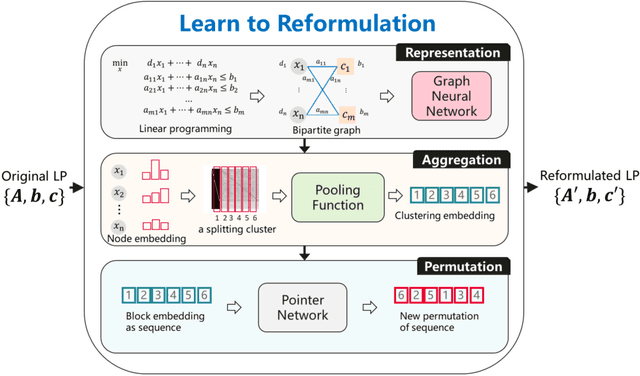
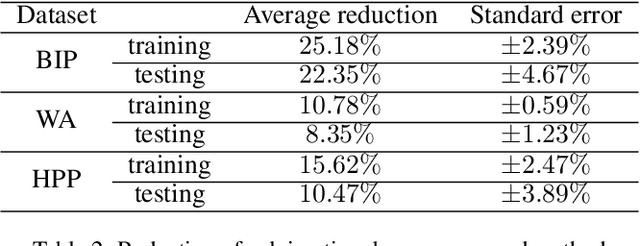
It has been verified that the linear programming (LP) is able to formulate many real-life optimization problems, which can obtain the optimum by resorting to corresponding solvers such as OptVerse, Gurobi and CPLEX. In the past decades, a serial of traditional operation research algorithms have been proposed to obtain the optimum of a given LP in a fewer solving time. Recently, there is a trend of using machine learning (ML) techniques to improve the performance of above solvers. However, almost no previous work takes advantage of ML techniques to improve the performance of solver from the front end, i.e., the modeling (or formulation). In this paper, we are the first to propose a reinforcement learning-based reformulation method for LP to improve the performance of solving process. Using an open-source solver COIN-OR LP (CLP) as an environment, we implement the proposed method over two public research LP datasets and one large-scale LP dataset collected from practical production planning scenario. The evaluation results suggest that the proposed method can effectively reduce both the solving iteration number ($25\%\downarrow$) and the solving time ($15\%\downarrow$) over above datasets in average, compared to directly solving the original LP instances.
An Improved Reinforcement Learning Algorithm for Learning to Branch
Jan 17, 2022Most combinatorial optimization problems can be formulated as mixed integer linear programming (MILP), in which branch-and-bound (B\&B) is a general and widely used method. Recently, learning to branch has become a hot research topic in the intersection of machine learning and combinatorial optimization. In this paper, we propose a novel reinforcement learning-based B\&B algorithm. Similar to offline reinforcement learning, we initially train on the demonstration data to accelerate learning massively. With the improvement of the training effect, the agent starts to interact with the environment with its learned policy gradually. It is critical to improve the performance of the algorithm by determining the mixing ratio between demonstration and self-generated data. Thus, we propose a prioritized storage mechanism to control this ratio automatically. In order to improve the robustness of the training process, a superior network is additionally introduced based on Double DQN, which always serves as a Q-network with competitive performance. We evaluate the performance of the proposed algorithm over three public research benchmarks and compare it against strong baselines, including three classical heuristics and one state-of-the-art imitation learning-based branching algorithm. The results show that the proposed algorithm achieves the best performance among compared algorithms and possesses the potential to improve B\&B algorithm performance continuously.