 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDScheLLM: Enabling Dynamic Scheduling through a Fine-Tuned Dual-System Large language Model
Jan 15, 2026Production scheduling is highly susceptible to dynamic disruptions, such as variations in processing times, machine availability, and unexpected task insertions. Conventional approaches typically rely on event-specific models and explicit analytical formulations, which limits their adaptability and generalization across previously unseen disturbances. To overcome these limitations, this paper proposes DScheLLM, a dynamic scheduling approach that leverages fine-tuned large language models within a dual-system (fast-slow) reasoning architecture to address disturbances of different scales. A unified large language model-based framework is constructed to handle dynamic events, where training datasets for both fast and slow reasoning modes are generated using exact schedules obtained from an operations research solver. The Huawei OpenPangu Embedded-7B model is subsequently fine-tuned under the hybrid reasoning paradigms using LoRA. Experimental evaluations on standard job shop scheduling benchmarks demonstrate that the fast-thinking mode can efficiently generate high-quality schedules and the slow-thinking mode can produce solver-compatible and well-formatted decision inputs. To the best of our knowledge, this work represents one of the earliest studies applying large language models to job shop scheduling in dynamic environments, highlighting their considerable potential for intelligent and adaptive scheduling optimization.
Rule-Based Conflict-Free Decision Framework in Swarm Confrontation
Mar 10, 2025Traditional rule-based decision-making methods with interpretable advantage, such as finite state machine, suffer from the jitter or deadlock(JoD) problems in extremely dynamic scenarios. To realize agent swarm confrontation, decision conflicts causing many JoD problems are a key issue to be solved. Here, we propose a novel decision-making framework that integrates probabilistic finite state machine, deep convolutional networks, and reinforcement learning to implement interpretable intelligence into agents. Our framework overcomes state machine instability and JoD problems, ensuring reliable and adaptable decisions in swarm confrontation. The proposed approach demonstrates effective performance via enhanced human-like cooperation and competitive strategies in the rigorous evaluation of real experiments, outperforming other methods.
Hierarchical Reinforcement Learning for Swarm Confrontation with High Uncertainty
Jun 12, 2024



In swarm robotics, confrontation including the pursuit-evasion game is a key scenario. High uncertainty caused by unknown opponents' strategies and dynamic obstacles complicates the action space into a hybrid decision process. Although the deep reinforcement learning method is significant for swarm confrontation since it can handle various sizes, as an end-to-end implementation, it cannot deal with the hybrid process. Here, we propose a novel hierarchical reinforcement learning approach consisting of a target allocation layer, a path planning layer, and the underlying dynamic interaction mechanism between the two layers, which indicates the quantified uncertainty. It decouples the hybrid process into discrete allocation and continuous planning layers, with a probabilistic ensemble model to quantify the uncertainty and regulate the interaction frequency adaptively. Furthermore, to overcome the unstable training process introduced by the two layers, we design an integration training method including pre-training and cross-training, which enhances the training efficiency and stability. Experiment results in both comparison and ablation studies validate the effectiveness and generalization performance of our proposed approach.
UAV Pathfinding in Dynamic Obstacle Avoidance with Multi-agent Reinforcement Learning
Oct 25, 2023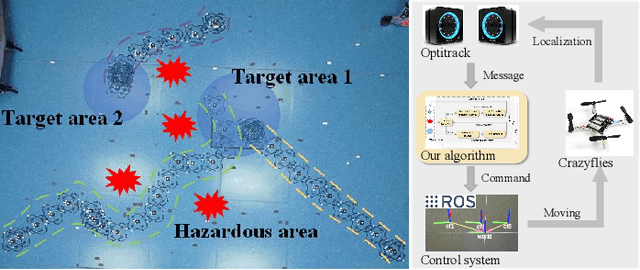
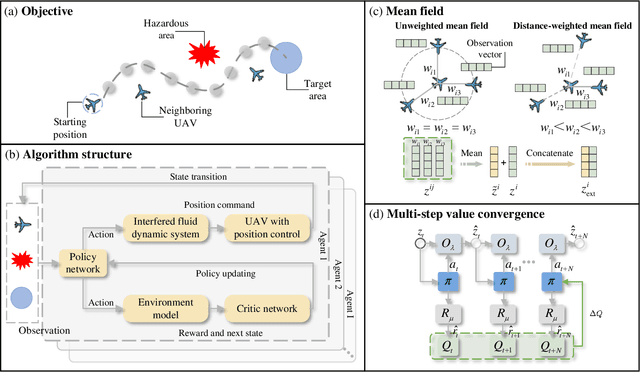
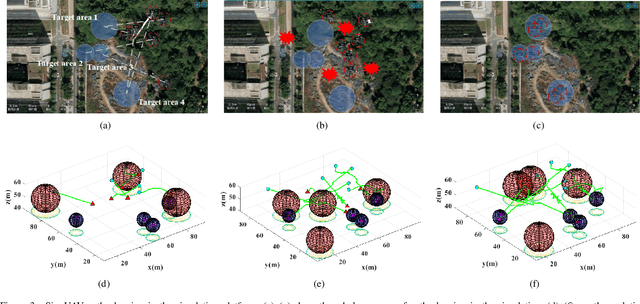
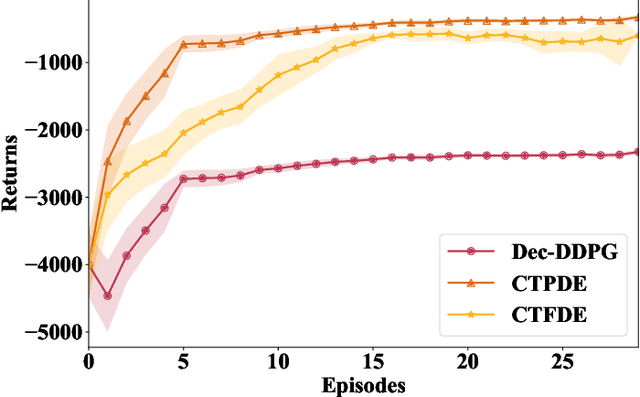
Multi-agent reinforcement learning based methods are significant for online planning of feasible and safe paths for agents in dynamic and uncertain scenarios. Although some methods like fully centralized and fully decentralized methods achieve a certain measure of success, they also encounter problems such as dimension explosion and poor convergence, respectively. In this paper, we propose a novel centralized training with decentralized execution method based on multi-agent reinforcement learning to solve the dynamic obstacle avoidance problem online. In this approach, each agent communicates only with the central planner or only with its neighbors, respectively, to plan feasible and safe paths online. We improve our methods based on the idea of model predictive control to increase the training efficiency and sample utilization of agents. The experimental results in both simulation, indoor, and outdoor environments validate the effectiveness of our method. The video is available at https://www.bilibili.com/video/BV1gw41197hV/?vd_source=9de61aecdd9fb684e546d032ef7fe7bf
AttriCLIP: A Non-Incremental Learner for Incremental Knowledge Learning
May 19, 2023



Continual learning aims to enable a model to incrementally learn knowledge from sequentially arrived data. Previous works adopt the conventional classification architecture, which consists of a feature extractor and a classifier. The feature extractor is shared across sequentially arrived tasks or classes, but one specific group of weights of the classifier corresponding to one new class should be incrementally expanded. Consequently, the parameters of a continual learner gradually increase. Moreover, as the classifier contains all historical arrived classes, a certain size of the memory is usually required to store rehearsal data to mitigate classifier bias and catastrophic forgetting. In this paper, we propose a non-incremental learner, named AttriCLIP, to incrementally extract knowledge of new classes or tasks. Specifically, AttriCLIP is built upon the pre-trained visual-language model CLIP. Its image encoder and text encoder are fixed to extract features from both images and text. Text consists of a category name and a fixed number of learnable parameters which are selected from our designed attribute word bank and serve as attributes. As we compute the visual and textual similarity for classification, AttriCLIP is a non-incremental learner. The attribute prompts, which encode the common knowledge useful for classification, can effectively mitigate the catastrophic forgetting and avoid constructing a replay memory. We evaluate our AttriCLIP and compare it with CLIP-based and previous state-of-the-art continual learning methods in realistic settings with domain-shift and long-sequence learning. The results show that our method performs favorably against previous state-of-the-arts. The implementation code can be available at https://github.com/bhrqw/AttriCLIP.
Resilient Binary Neural Network
Feb 05, 2023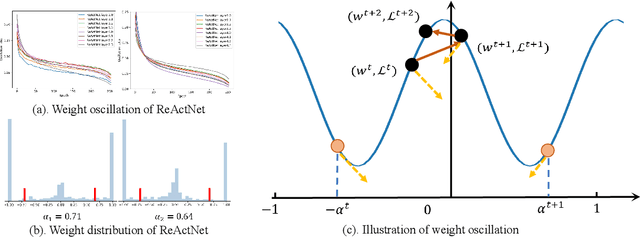



Binary neural networks (BNNs) have received ever-increasing popularity for their great capability of reducing storage burden as well as quickening inference time. However, there is a severe performance drop compared with real-valued networks, due to its intrinsic frequent weight oscillation during training. In this paper, we introduce a Resilient Binary Neural Network (ReBNN) to mitigate the frequent oscillation for better BNNs' training. We identify that the weight oscillation mainly stems from the non-parametric scaling factor. To address this issue, we propose to parameterize the scaling factor and introduce a weighted reconstruction loss to build an adaptive training objective. For the first time, we show that the weight oscillation is controlled by the balanced parameter attached to the reconstruction loss, which provides a theoretical foundation to parameterize it in back propagation. Based on this, we learn our ReBNN by calculating the balanced parameter based on its maximum magnitude, which can effectively mitigate the weight oscillation with a resilient training process. Extensive experiments are conducted upon various network models, such as ResNet and Faster-RCNN for computer vision, as well as BERT for natural language processing. The results demonstrate the overwhelming performance of our ReBNN over prior arts. For example, our ReBNN achieves 66.9% Top-1 accuracy with ResNet-18 backbone on the ImageNet dataset, surpassing existing state-of-the-arts by a significant margin. Our code is open-sourced at https://github.com/SteveTsui/ReBNN.
IDa-Det: An Information Discrepancy-aware Distillation for 1-bit Detectors
Oct 07, 2022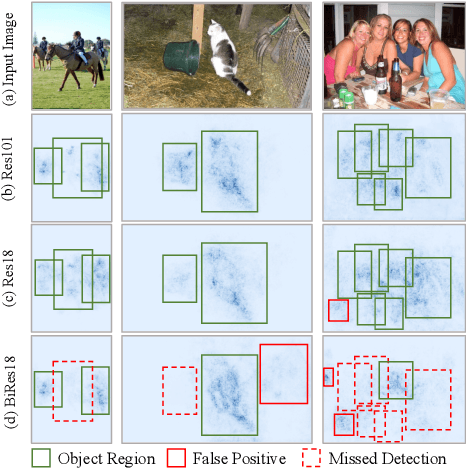


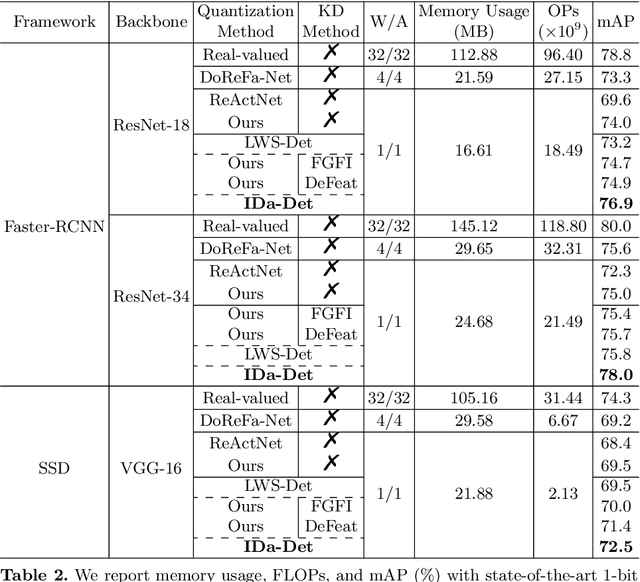
Knowledge distillation (KD) has been proven to be useful for training compact object detection models. However, we observe that KD is often effective when the teacher model and student counterpart share similar proposal information. This explains why existing KD methods are less effective for 1-bit detectors, caused by a significant information discrepancy between the real-valued teacher and the 1-bit student. This paper presents an Information Discrepancy-aware strategy (IDa-Det) to distill 1-bit detectors that can effectively eliminate information discrepancies and significantly reduce the performance gap between a 1-bit detector and its real-valued counterpart. We formulate the distillation process as a bi-level optimization formulation. At the inner level, we select the representative proposals with maximum information discrepancy. We then introduce a novel entropy distillation loss to reduce the disparity based on the selected proposals. Extensive experiments demonstrate IDa-Det's superiority over state-of-the-art 1-bit detectors and KD methods on both PASCAL VOC and COCO datasets. IDa-Det achieves a 76.9% mAP for a 1-bit Faster-RCNN with ResNet-18 backbone. Our code is open-sourced on https://github.com/SteveTsui/IDa-Det.
Recurrent Bilinear Optimization for Binary Neural Networks
Sep 04, 2022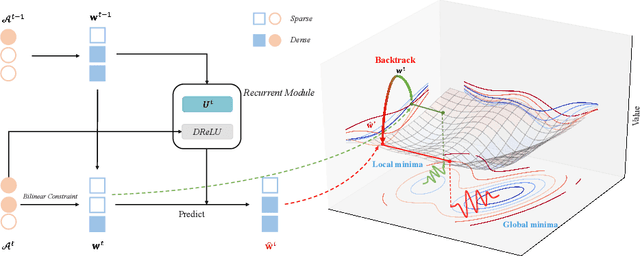
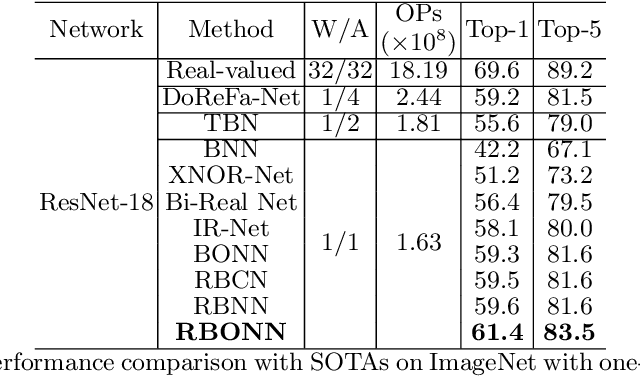
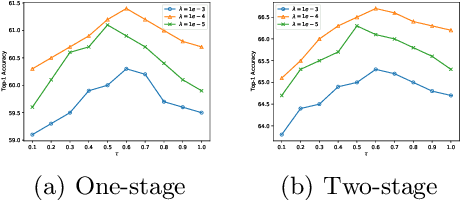
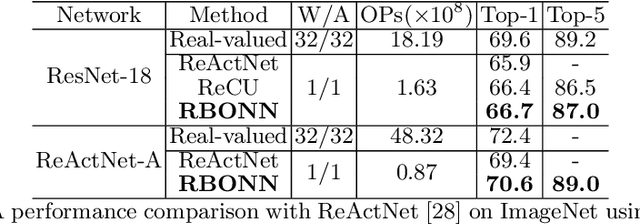
Binary Neural Networks (BNNs) show great promise for real-world embedded devices. As one of the critical steps to achieve a powerful BNN, the scale factor calculation plays an essential role in reducing the performance gap to their real-valued counterparts. However, existing BNNs neglect the intrinsic bilinear relationship of real-valued weights and scale factors, resulting in a sub-optimal model caused by an insufficient training process. To address this issue, Recurrent Bilinear Optimization is proposed to improve the learning process of BNNs (RBONNs) by associating the intrinsic bilinear variables in the back propagation process. Our work is the first attempt to optimize BNNs from the bilinear perspective. Specifically, we employ a recurrent optimization and Density-ReLU to sequentially backtrack the sparse real-valued weight filters, which will be sufficiently trained and reach their performance limits based on a controllable learning process. We obtain robust RBONNs, which show impressive performance over state-of-the-art BNNs on various models and datasets. Particularly, on the task of object detection, RBONNs have great generalization performance. Our code is open-sourced on https://github.com/SteveTsui/RBONN .
TerViT: An Efficient Ternary Vision Transformer
Jan 21, 2022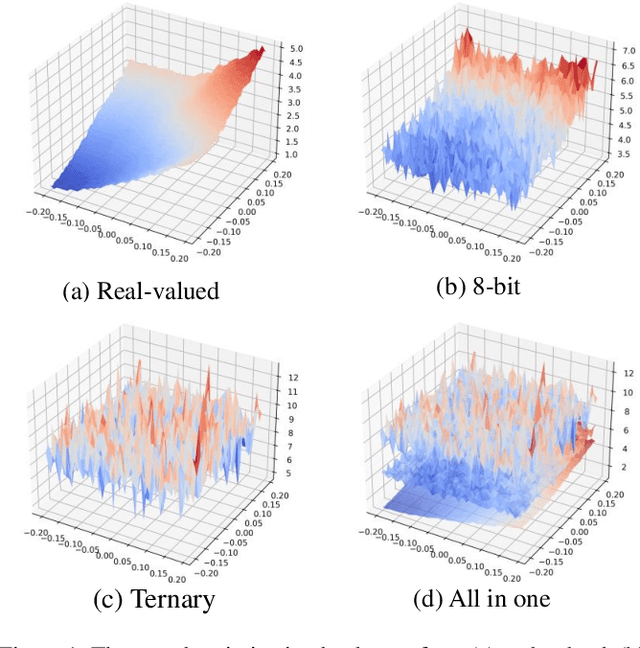
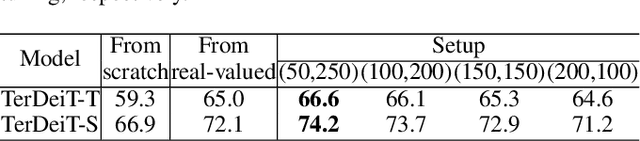
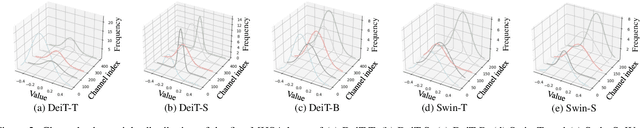

Vision transformers (ViTs) have demonstrated great potential in various visual tasks, but suffer from expensive computational and memory cost problems when deployed on resource-constrained devices. In this paper, we introduce a ternary vision transformer (TerViT) to ternarize the weights in ViTs, which are challenged by the large loss surface gap between real-valued and ternary parameters. To address the issue, we introduce a progressive training scheme by first training 8-bit transformers and then TerViT, and achieve a better optimization than conventional methods. Furthermore, we introduce channel-wise ternarization, by partitioning each matrix to different channels, each of which is with an unique distribution and ternarization interval. We apply our methods to popular DeiT and Swin backbones, and extensive results show that we can achieve competitive performance. For example, TerViT can quantize Swin-S to 13.1MB model size while achieving above 79% Top-1 accuracy on ImageNet dataset.
An Improved Reinforcement Learning Algorithm for Learning to Branch
Jan 17, 2022Most combinatorial optimization problems can be formulated as mixed integer linear programming (MILP), in which branch-and-bound (B\&B) is a general and widely used method. Recently, learning to branch has become a hot research topic in the intersection of machine learning and combinatorial optimization. In this paper, we propose a novel reinforcement learning-based B\&B algorithm. Similar to offline reinforcement learning, we initially train on the demonstration data to accelerate learning massively. With the improvement of the training effect, the agent starts to interact with the environment with its learned policy gradually. It is critical to improve the performance of the algorithm by determining the mixing ratio between demonstration and self-generated data. Thus, we propose a prioritized storage mechanism to control this ratio automatically. In order to improve the robustness of the training process, a superior network is additionally introduced based on Double DQN, which always serves as a Q-network with competitive performance. We evaluate the performance of the proposed algorithm over three public research benchmarks and compare it against strong baselines, including three classical heuristics and one state-of-the-art imitation learning-based branching algorithm. The results show that the proposed algorithm achieves the best performance among compared algorithms and possesses the potential to improve B\&B algorithm performance continuously.