 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning for Swarm Confrontation with High Uncertainty
Jun 12, 2024In swarm robotics, confrontation including the pursuit-evasion game is a key scenario. High uncertainty caused by unknown opponents' strategies and dynamic obstacles complicates the action space into a hybrid decision process. Although the deep reinforcement learning method is significant for swarm confrontation since it can handle various sizes, as an end-to-end implementation, it cannot deal with the hybrid process. Here, we propose a novel hierarchical reinforcement learning approach consisting of a target allocation layer, a path planning layer, and the underlying dynamic interaction mechanism between the two layers, which indicates the quantified uncertainty. It decouples the hybrid process into discrete allocation and continuous planning layers, with a probabilistic ensemble model to quantify the uncertainty and regulate the interaction frequency adaptively. Furthermore, to overcome the unstable training process introduced by the two layers, we design an integration training method including pre-training and cross-training, which enhances the training efficiency and stability. Experiment results in both comparison and ablation studies validate the effectiveness and generalization performance of our proposed approach.
UAV Pathfinding in Dynamic Obstacle Avoidance with Multi-agent Reinforcement Learning
Oct 25, 2023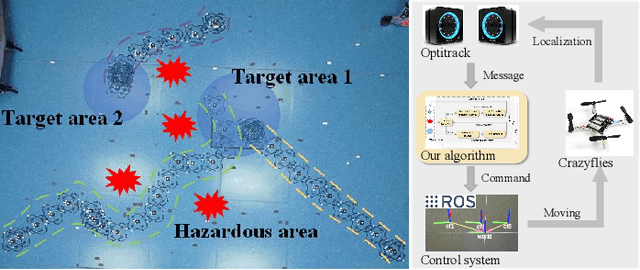
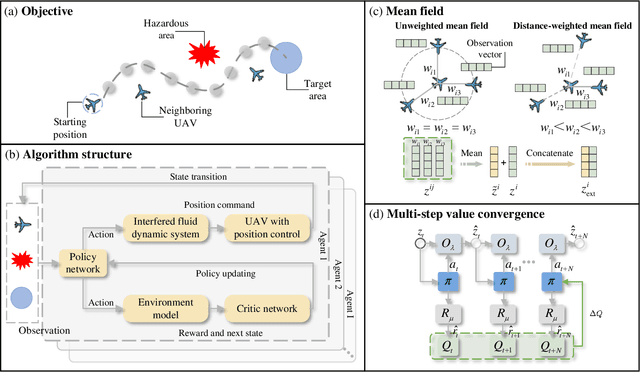
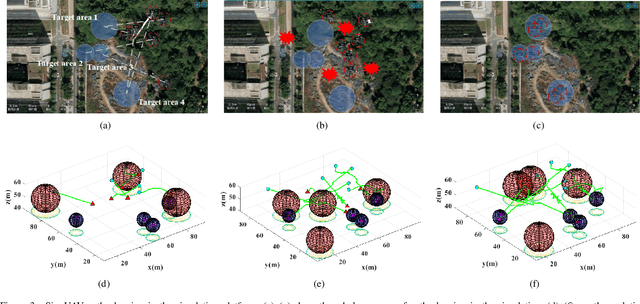
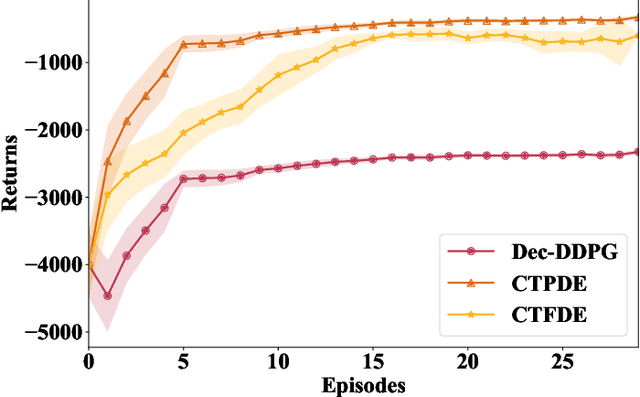
Multi-agent reinforcement learning based methods are significant for online planning of feasible and safe paths for agents in dynamic and uncertain scenarios. Although some methods like fully centralized and fully decentralized methods achieve a certain measure of success, they also encounter problems such as dimension explosion and poor convergence, respectively. In this paper, we propose a novel centralized training with decentralized execution method based on multi-agent reinforcement learning to solve the dynamic obstacle avoidance problem online. In this approach, each agent communicates only with the central planner or only with its neighbors, respectively, to plan feasible and safe paths online. We improve our methods based on the idea of model predictive control to increase the training efficiency and sample utilization of agents. The experimental results in both simulation, indoor, and outdoor environments validate the effectiveness of our method. The video is available at https://www.bilibili.com/video/BV1gw41197hV/?vd_source=9de61aecdd9fb684e546d032ef7fe7bf
Model predictive control-based value estimation for efficient reinforcement learning
Oct 25, 2023Reinforcement learning suffers from limitations in real practices primarily due to the numbers of required interactions with virtual environments. It results in a challenging problem that we are implausible to obtain an optimal strategy only with a few attempts for many learning method. Hereby, we design an improved reinforcement learning method based on model predictive control that models the environment through a data-driven approach. Based on learned environmental model, it performs multi-step prediction to estimate the value function and optimize the policy. The method demonstrates higher learning efficiency, faster convergent speed of strategies tending to the optimal value, and fewer sample capacity space required by experience replay buffers. Experimental results, both in classic databases and in a dynamic obstacle avoidance scenario for unmanned aerial vehicle, validate the proposed approaches.