 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning domain-invariant features through channel-level sparsification for Out-Of Distribution Generalization
Mar 26, 2026Out-of-Distribution (OOD) generalization has become a primary metric for evaluating image analysis systems. Since deep learning models tend to capture domain-specific context, they often develop shortcut dependencies on these non-causal features, leading to inconsistent performance across different data sources. Current techniques, such as invariance learning, attempt to mitigate this. However, they struggle to isolate highly mixed features within deep latent spaces. This limitation prevents them from fully resolving the shortcut learning problem.In this paper, we propose Hierarchical Causal Dropout (HCD), a method that uses channel-level causal masks to enforce feature sparsity. This approach allows the model to separate causal features from spurious ones, effectively performing a causal intervention at the representation level. The training is guided by a Matrix-based Mutual Information (MMI) objective to minimize the mutual information between latent features and domain labels, while simultaneously maximizing the information shared with class labels.To ensure stability, we incorporate a StyleMix-driven VICReg module, which prevents the masks from accidentally filtering out essential causal data. Experimental results on OOD benchmarks show that HCD performs better than existing top-tier methods.
Integrated cooperative localization of heterogeneous measurement swarm: A unified data-driven method
Mar 05, 2026The cooperative localization (CL) problem in heterogeneous robotic systems with different measurement capabilities is investigated in this work. In practice, heterogeneous sensors lead to directed and sparse measurement topologies, whereas most existing CL approaches rely on multilateral localization with restrictive multi-neighbor geometric requirements. To overcome this limitation, we enable pairwise relative localization (RL) between neighboring robots using only mutual measurement and odometry information. A unified data-driven adaptive RL estimator is first developed to handle heterogeneous and unidirectional measurements. Based on the convergent RL estimates, a distributed pose-coupling CL strategy is then designed, which guarantees CL under a weakly connected directed measurement topology, representing the least restrictive condition among existing results. The proposed method is independent of specific control tasks and is validated through a formation control application and real-world experiments.
Whole-Body Control With Terrain Estimation of A 6-DoF Wheeled Bipedal Robot
Nov 09, 2025
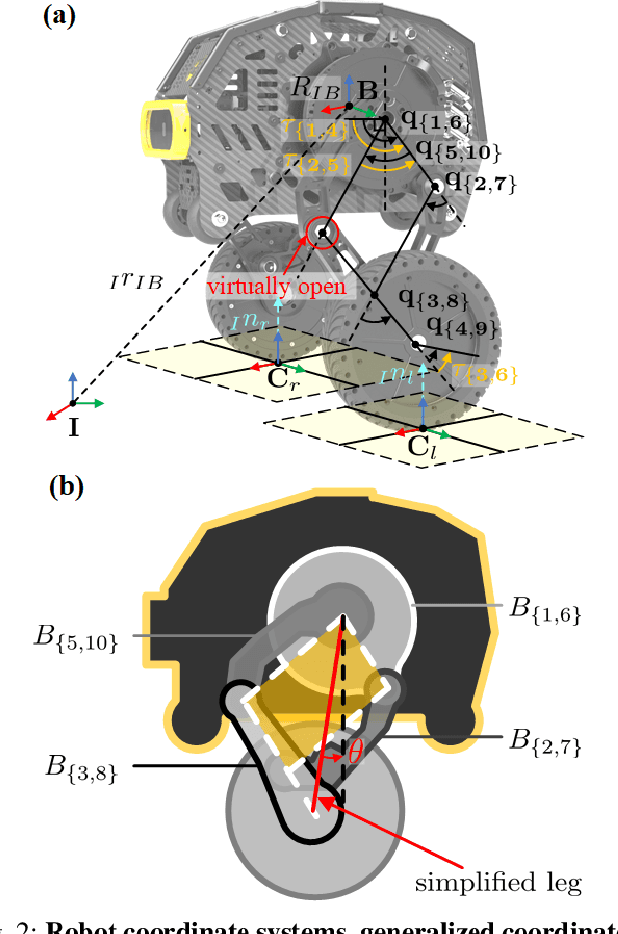
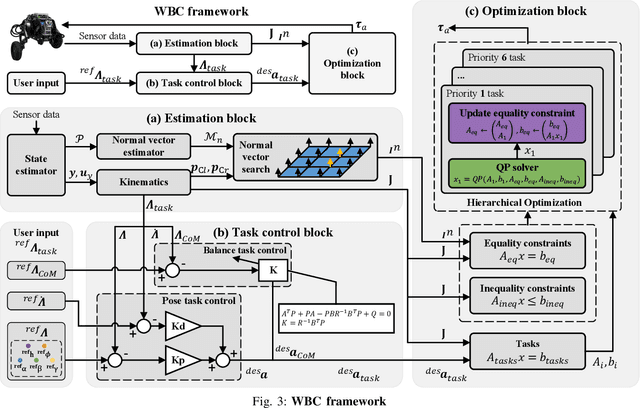
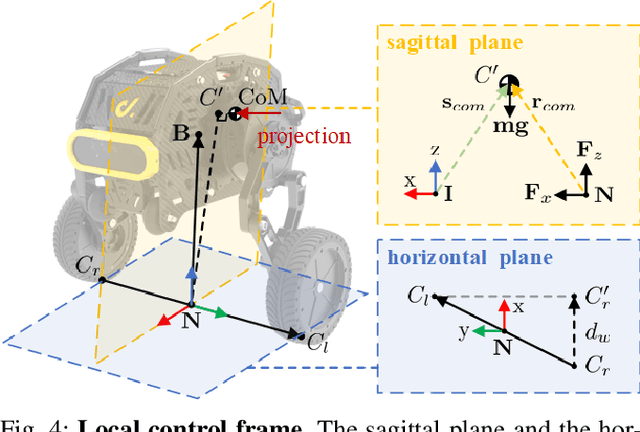
Wheeled bipedal robots have garnered increasing attention in exploration and inspection. However, most research simplifies calculations by ignoring leg dynamics, thereby restricting the robot's full motion potential. Additionally, robots face challenges when traversing uneven terrain. To address the aforementioned issue, we develop a complete dynamics model and design a whole-body control framework with terrain estimation for a novel 6 degrees of freedom wheeled bipedal robot. This model incorporates the closed-loop dynamics of the robot and a ground contact model based on the estimated ground normal vector. We use a LiDAR inertial odometry framework and improved Principal Component Analysis for terrain estimation. Task controllers, including PD control law and LQR, are employed for pose control and centroidal dynamics-based balance control, respectively. Furthermore, a hierarchical optimization approach is used to solve the whole-body control problem. We validate the performance of the terrain estimation algorithm and demonstrate the algorithm's robustness and ability to traverse uneven terrain through both simulation and real-world experiments.
Bidirectional Task-Motion Planning Based on Hierarchical Reinforcement Learning for Strategic Confrontation
Apr 22, 2025In swarm robotics, confrontation scenarios, including strategic confrontations, require efficient decision-making that integrates discrete commands and continuous actions. Traditional task and motion planning methods separate decision-making into two layers, but their unidirectional structure fails to capture the interdependence between these layers, limiting adaptability in dynamic environments. Here, we propose a novel bidirectional approach based on hierarchical reinforcement learning, enabling dynamic interaction between the layers. This method effectively maps commands to task allocation and actions to path planning, while leveraging cross-training techniques to enhance learning across the hierarchical framework. Furthermore, we introduce a trajectory prediction model that bridges abstract task representations with actionable planning goals. In our experiments, it achieves over 80\% in confrontation win rate and under 0.01 seconds in decision time, outperforming existing approaches. Demonstrations through large-scale tests and real-world robot experiments further emphasize the generalization capabilities and practical applicability of our method.
Relative Pose Estimation for Nonholonomic Robot Formation with UWB-IO Measurements
Nov 08, 2024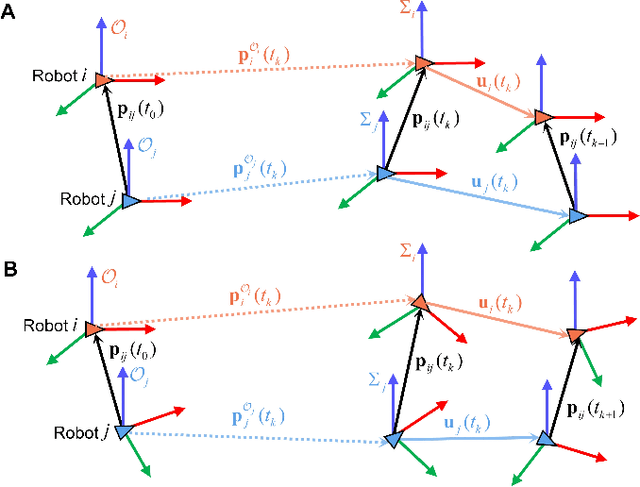
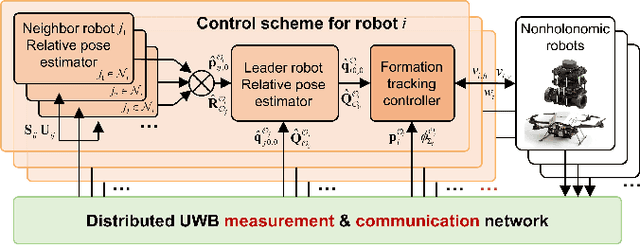
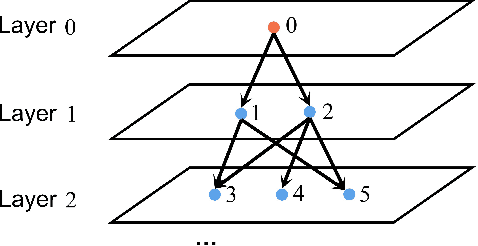
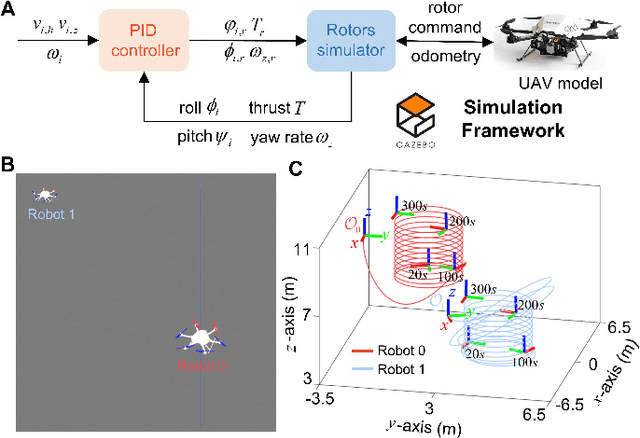
This article studies the problem of distributed formation control for multiple robots by using onboard ultra wide band (UWB) ranging and inertial odometer (IO) measurements. Although this problem has been widely studied, a fundamental limitation of most works is that they require each robot's pose and sensor measurements are expressed in a common reference frame. However, it is inapplicable for nonholonomic robot formations due to the practical difficulty of aligning IO measurements of individual robot in a common frame. To address this problem, firstly, a concurrent-learning based estimator is firstly proposed to achieve relative localization between neighboring robots in a local frame. Different from most relative localization methods in a global frame, both relative position and orientation in a local frame are estimated with only UWB ranging and IO measurements. Secondly, to deal with information loss caused by directed communication topology, a cooperative localization algorithm is introduced to estimate the relative pose to the leader robot. Thirdly, based on the theoretical results on relative pose estimation, a distributed formation tracking controller is proposed for nonholonomic robots. Both gazebo physical simulation and real-world experiments conducted on networked TurtleBot3 nonholonomic robots are provided to demonstrate the effectiveness of the proposed method.
Distributed Formation Shape Control of Identity-less Robot Swarms
Oct 31, 2024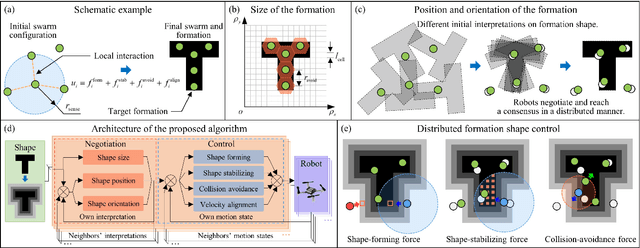
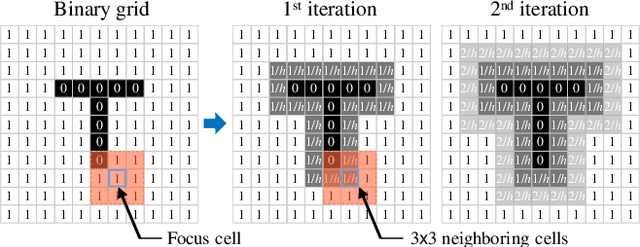
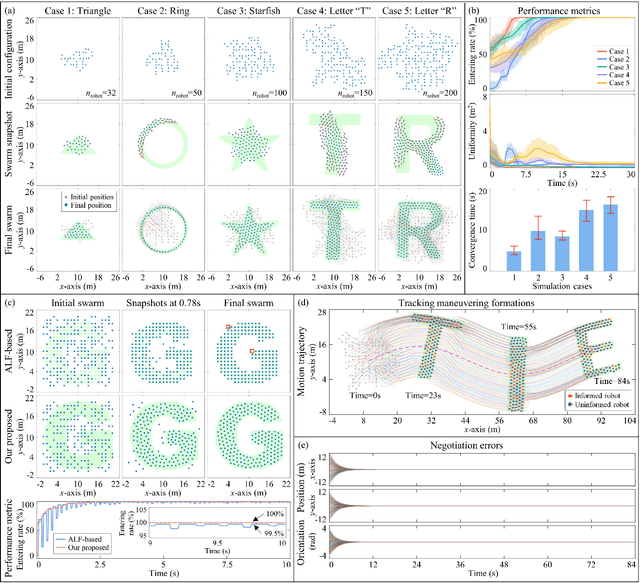
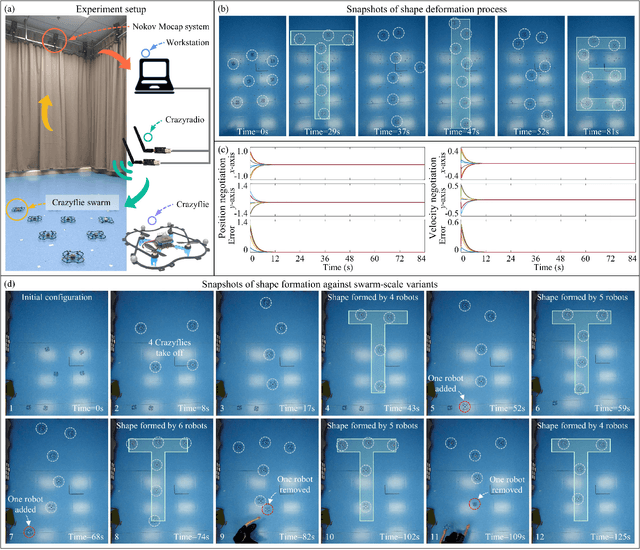
Different from most of the formation strategies where robots require unique labels to identify topological neighbors to satisfy the predefined shape constraints, we here study the problem of identity-less distributed shape formation in homogeneous swarms, which is rarely studied in the literature. The absence of identities creates a unique challenge: how to design appropriate target formations and local behaviors that are suitable for identity-less formation shape control. To address this challenge, we propose the following novel results. First, to avoid using unique identities, we propose a dynamic formation description method and solve the formation consensus of robots in a locally distributed manner. Second, to handle identity-less distributed formations, we propose a fully distributed control law for homogeneous swarms based on locally sensed information. While the existing methods are applicable to simple cases where the target formation is stationary, ours can tackle more general maneuvering formations such as translation, rotation, or even shape deformation. Both numerical simulation and flight experiment are presented to verify the effectiveness and robustness of our proposed formation strategy.
Concurrent-Learning Based Relative Localization in Shape Formation of Robot Swarms
Oct 08, 2024
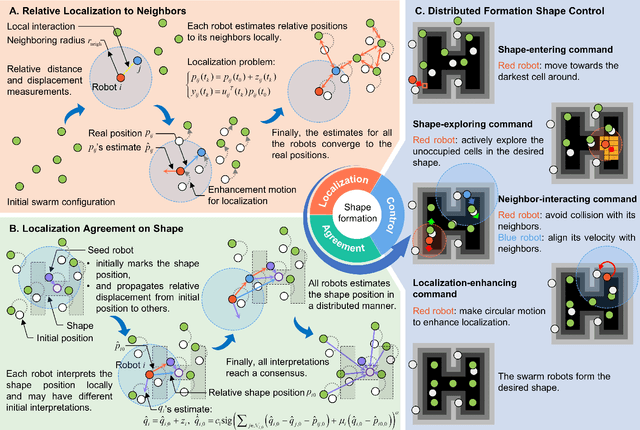
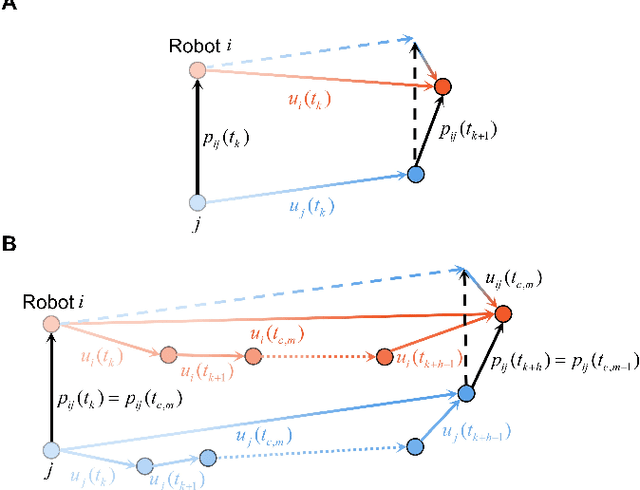
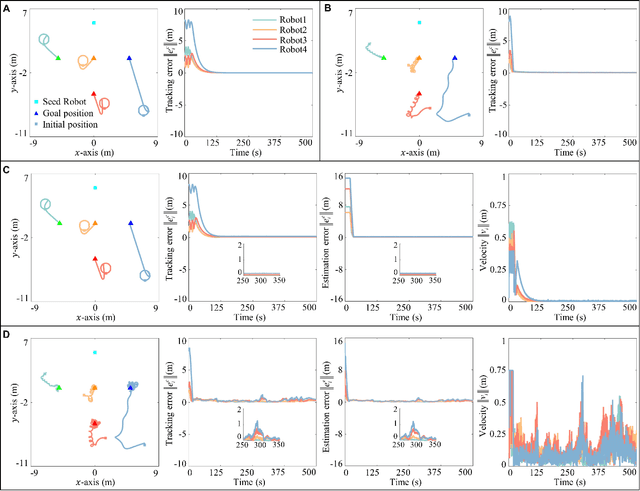
In this paper, we address the shape formation problem for massive robot swarms in environments where external localization systems are unavailable. Achieving this task effectively with solely onboard measurements is still scarcely explored and faces some practical challenges. To solve this challenging problem, we propose the following novel results. Firstly, to estimate the relative positions among neighboring robots, a concurrent-learning based estimator is proposed. It relaxes the persistent excitation condition required in the classical ones such as least-square estimator. Secondly, we introduce a finite-time agreement protocol to determine the shape location. This is achieved by estimating the relative position between each robot and a randomly assigned seed robot. The initial position of the seed one marks the shape location. Thirdly, based on the theoretical results of the relative localization, a novel behavior-based control strategy is devised. This strategy not only enables adaptive shape formation of large group of robots but also enhances the observability of inter-robot relative localization. Numerical simulation results are provided to verify the performance of our proposed strategy compared to the state-of-the-art ones. Additionally, outdoor experiments on real robots further demonstrate the practical effectiveness and robustness of our methods.
Hierarchical Reinforcement Learning for Swarm Confrontation with High Uncertainty
Jun 12, 2024



In swarm robotics, confrontation including the pursuit-evasion game is a key scenario. High uncertainty caused by unknown opponents' strategies and dynamic obstacles complicates the action space into a hybrid decision process. Although the deep reinforcement learning method is significant for swarm confrontation since it can handle various sizes, as an end-to-end implementation, it cannot deal with the hybrid process. Here, we propose a novel hierarchical reinforcement learning approach consisting of a target allocation layer, a path planning layer, and the underlying dynamic interaction mechanism between the two layers, which indicates the quantified uncertainty. It decouples the hybrid process into discrete allocation and continuous planning layers, with a probabilistic ensemble model to quantify the uncertainty and regulate the interaction frequency adaptively. Furthermore, to overcome the unstable training process introduced by the two layers, we design an integration training method including pre-training and cross-training, which enhances the training efficiency and stability. Experiment results in both comparison and ablation studies validate the effectiveness and generalization performance of our proposed approach.
UAV Pathfinding in Dynamic Obstacle Avoidance with Multi-agent Reinforcement Learning
Oct 25, 2023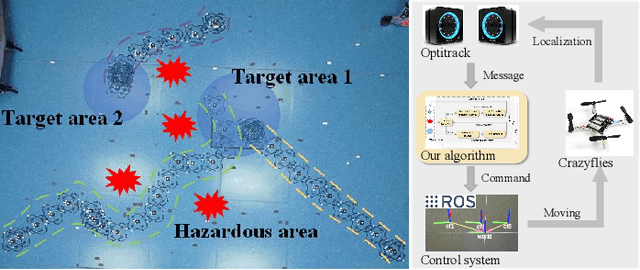
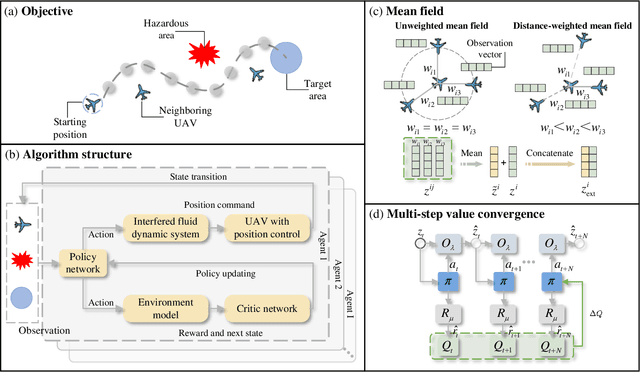
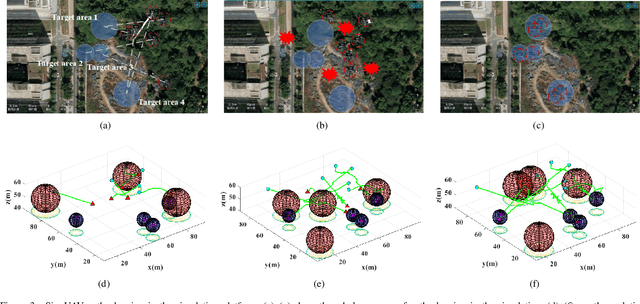
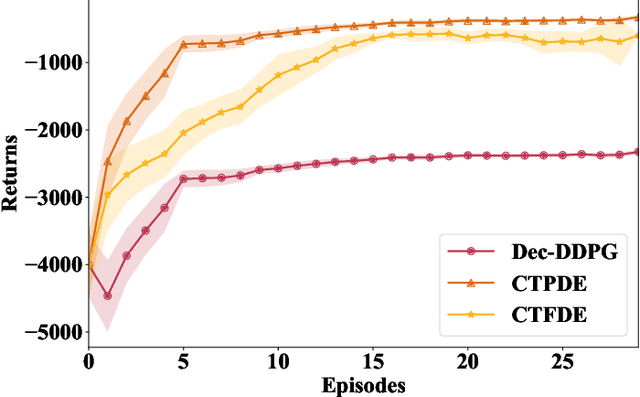
Multi-agent reinforcement learning based methods are significant for online planning of feasible and safe paths for agents in dynamic and uncertain scenarios. Although some methods like fully centralized and fully decentralized methods achieve a certain measure of success, they also encounter problems such as dimension explosion and poor convergence, respectively. In this paper, we propose a novel centralized training with decentralized execution method based on multi-agent reinforcement learning to solve the dynamic obstacle avoidance problem online. In this approach, each agent communicates only with the central planner or only with its neighbors, respectively, to plan feasible and safe paths online. We improve our methods based on the idea of model predictive control to increase the training efficiency and sample utilization of agents. The experimental results in both simulation, indoor, and outdoor environments validate the effectiveness of our method. The video is available at https://www.bilibili.com/video/BV1gw41197hV/?vd_source=9de61aecdd9fb684e546d032ef7fe7bf
Model predictive control-based value estimation for efficient reinforcement learning
Oct 25, 2023



Reinforcement learning suffers from limitations in real practices primarily due to the numbers of required interactions with virtual environments. It results in a challenging problem that we are implausible to obtain an optimal strategy only with a few attempts for many learning method. Hereby, we design an improved reinforcement learning method based on model predictive control that models the environment through a data-driven approach. Based on learned environmental model, it performs multi-step prediction to estimate the value function and optimize the policy. The method demonstrates higher learning efficiency, faster convergent speed of strategies tending to the optimal value, and fewer sample capacity space required by experience replay buffers. Experimental results, both in classic databases and in a dynamic obstacle avoidance scenario for unmanned aerial vehicle, validate the proposed approaches.