 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenOpticalFlow: A Generative Approach to Unsupervised Optical Flow Learning
Mar 23, 2026Optical flow estimation is a fundamental problem in computer vision, yet the reliance on expensive ground-truth annotations limits the scalability of supervised approaches. Although unsupervised and semi-supervised methods alleviate this issue, they often suffer from unreliable supervision signals based on brightness constancy and smoothness assumptions, leading to inaccurate motion estimation in complex real-world scenarios. To overcome these limitations, we introduce \textbf{\modelname}, a novel framework that synthesizes large-scale, perfectly aligned frame--flow data pairs for supervised optical flow training without human annotations. Specifically, our method leverages a pre-trained depth estimation network to generate pseudo optical flows, which serve as conditioning inputs for a next-frame generation model trained to produce high-fidelity, pixel-aligned subsequent frames. This process enables the creation of abundant, high-quality synthetic data with precise motion correspondence. Furthermore, we propose an \textit{inconsistent pixel filtering} strategy that identifies and removes unreliable pixels in generated frames, effectively enhancing fine-tuning performance on real-world datasets. Extensive experiments on KITTI2012, KITTI2015, and Sintel demonstrate that \textbf{\modelname} achieves competitive or superior results compared to existing unsupervised and semi-supervised approaches, highlighting its potential as a scalable and annotation-free solution for optical flow learning. We will release our code upon acceptance.
Unbiased Dynamic Pruning for Efficient Group-Based Policy Optimization
Mar 04, 2026Group Relative Policy Optimization (GRPO) effectively scales LLM reasoning but incurs prohibitive computational costs due to its extensive group-based sampling requirement. While recent selective data utilization methods can mitigate this overhead, they could induce estimation bias by altering the underlying sampling distribution, compromising theoretical rigor and convergence behavior. To address this limitation, we propose Dynamic Pruning Policy Optimization (DPPO), a framework that enables dynamic pruning while preserving unbiased gradient estimation through importance sampling-based correction. By incorporating mathematically derived rescaling factors, DPPO significantly accelerates GRPO training without altering the optimization objective of the full-batch baseline. Furthermore, to mitigate the data sparsity induced by pruning, we introduce Dense Prompt Packing, a window-based greedy strategy that maximizes valid token density and hardware utilization. Extensive experiments demonstrate that DPPO consistently accelerates training across diverse models and benchmarks. For instance, on Qwen3-4B trained on MATH, DPPO achieves 2.37$\times$ training speedup and outperforms GRPO by 3.36% in average accuracy across six mathematical reasoning benchmarks.
Rigidity-Aware Geometric Pretraining for Protein Design and Conformational Ensembles
Mar 02, 2026Generative models have recently advanced $\textit{de novo}$ protein design by learning the statistical regularities of natural structures. However, current approaches face three key limitations: (1) Existing methods cannot jointly learn protein geometry and design tasks, where pretraining can be a solution; (2) Current pretraining methods mostly rely on local, non-rigid atomic representations for property prediction downstream tasks, limiting global geometric understanding for protein generation tasks; and (3) Existing approaches have yet to effectively model the rich dynamic and conformational information of protein structures. To overcome these issues, we introduce $\textbf{RigidSSL}$ ($\textit{Rigidity-Aware Self-Supervised Learning}$), a geometric pretraining framework that front-loads geometry learning prior to generative finetuning. Phase I (RigidSSL-Perturb) learns geometric priors from 432K structures from the AlphaFold Protein Structure Database with simulated perturbations. Phase II (RigidSSL-MD) refines these representations on 1.3K molecular dynamics trajectories to capture physically realistic transitions. Underpinning both phases is a bi-directional, rigidity-aware flow matching objective that jointly optimizes translational and rotational dynamics to maximize mutual information between conformations. Empirically, RigidSSL variants improve designability by up to 43\% while enhancing novelty and diversity in unconditional generation. Furthermore, RigidSSL-Perturb improves the success rate by 5.8\% in zero-shot motif scaffolding and RigidSSL-MD captures more biophysically realistic conformational ensembles in G protein-coupled receptor modeling. The code is available at: https://github.com/ZhanghanNi/RigidSSL.git.
Squeeze10-LLM: Squeezing LLMs' Weights by 10 Times via a Staged Mixed-Precision Quantization Method
Jul 24, 2025Deploying large language models (LLMs) is challenging due to their massive parameters and high computational costs. Ultra low-bit quantization can significantly reduce storage and accelerate inference, but extreme compression (i.e., mean bit-width <= 2) often leads to severe performance degradation. To address this, we propose Squeeze10-LLM, effectively "squeezing" 16-bit LLMs' weights by 10 times. Specifically, Squeeze10-LLM is a staged mixed-precision post-training quantization (PTQ) framework and achieves an average of 1.6 bits per weight by quantizing 80% of the weights to 1 bit and 20% to 4 bits. We introduce Squeeze10LLM with two key innovations: Post-Binarization Activation Robustness (PBAR) and Full Information Activation Supervision (FIAS). PBAR is a refined weight significance metric that accounts for the impact of quantization on activations, improving accuracy in low-bit settings. FIAS is a strategy that preserves full activation information during quantization to mitigate cumulative error propagation across layers. Experiments on LLaMA and LLaMA2 show that Squeeze10-LLM achieves state-of-the-art performance for sub-2bit weight-only quantization, improving average accuracy from 43% to 56% on six zero-shot classification tasks--a significant boost over existing PTQ methods. Our code will be released upon publication.
CCExpert: Advancing MLLM Capability in Remote Sensing Change Captioning with Difference-Aware Integration and a Foundational Dataset
Nov 18, 2024



Remote Sensing Image Change Captioning (RSICC) aims to generate natural language descriptions of surface changes between multi-temporal remote sensing images, detailing the categories, locations, and dynamics of changed objects (e.g., additions or disappearances). Many current methods attempt to leverage the long-sequence understanding and reasoning capabilities of multimodal large language models (MLLMs) for this task. However, without comprehensive data support, these approaches often alter the essential feature transmission pathways of MLLMs, disrupting the intrinsic knowledge within the models and limiting their potential in RSICC. In this paper, we propose a novel model, CCExpert, based on a new, advanced multimodal large model framework. Firstly, we design a difference-aware integration module to capture multi-scale differences between bi-temporal images and incorporate them into the original image context, thereby enhancing the signal-to-noise ratio of differential features. Secondly, we constructed a high-quality, diversified dataset called CC-Foundation, containing 200,000 image pairs and 1.2 million captions, to provide substantial data support for continue pretraining in this domain. Lastly, we employed a three-stage progressive training process to ensure the deep integration of the difference-aware integration module with the pretrained MLLM. CCExpert achieved a notable performance of $S^*_m=81.80$ on the LEVIR-CC benchmark, significantly surpassing previous state-of-the-art methods. The code and part of the dataset will soon be open-sourced at https://github.com/Meize0729/CCExpert.
P4Q: Learning to Prompt for Quantization in Visual-language Models
Sep 26, 2024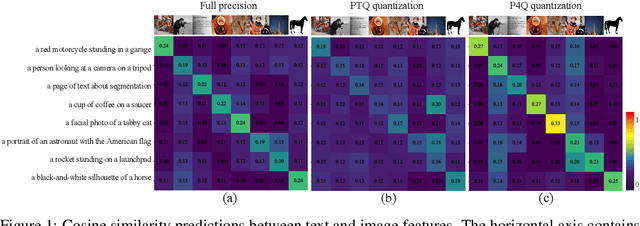
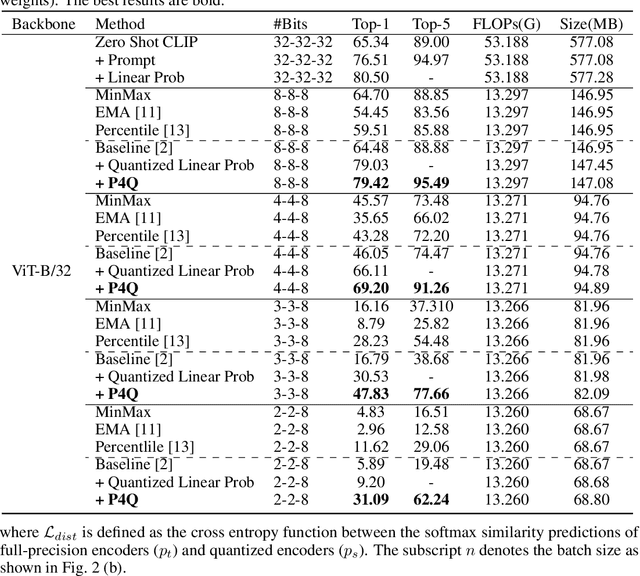
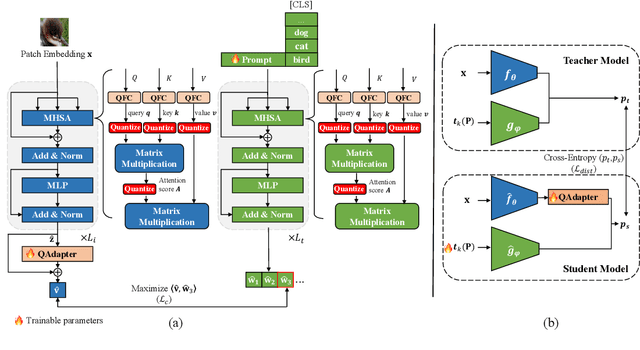
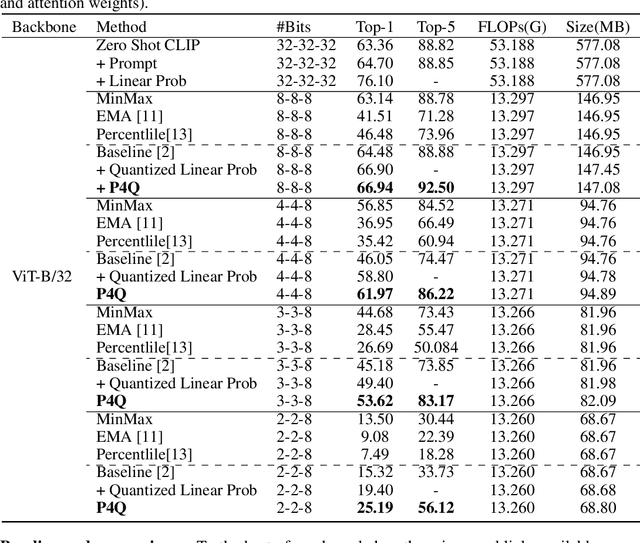
Large-scale pre-trained Vision-Language Models (VLMs) have gained prominence in various visual and multimodal tasks, yet the deployment of VLMs on downstream application platforms remains challenging due to their prohibitive requirements of training samples and computing resources. Fine-tuning and quantization of VLMs can substantially reduce the sample and computation costs, which are in urgent need. There are two prevailing paradigms in quantization, Quantization-Aware Training (QAT) can effectively quantize large-scale VLMs but incur a huge training cost, while low-bit Post-Training Quantization (PTQ) suffers from a notable performance drop. We propose a method that balances fine-tuning and quantization named ``Prompt for Quantization'' (P4Q), in which we design a lightweight architecture to leverage contrastive loss supervision to enhance the recognition performance of a PTQ model. Our method can effectively reduce the gap between image features and text features caused by low-bit quantization, based on learnable prompts to reorganize textual representations and a low-bit adapter to realign the distributions of image and text features. We also introduce a distillation loss based on cosine similarity predictions to distill the quantized model using a full-precision teacher. Extensive experimental results demonstrate that our P4Q method outperforms prior arts, even achieving comparable results to its full-precision counterparts. For instance, our 8-bit P4Q can theoretically compress the CLIP-ViT/B-32 by 4 $\times$ while achieving 66.94\% Top-1 accuracy, outperforming the learnable prompt fine-tuned full-precision model by 2.24\% with negligible additional parameters on the ImageNet dataset.
A Multi-Grained Symmetric Differential Equation Model for Learning Protein-Ligand Binding Dynamics
Feb 01, 2024In drug discovery, molecular dynamics (MD) simulation for protein-ligand binding provides a powerful tool for predicting binding affinities, estimating transport properties, and exploring pocket sites. There has been a long history of improving the efficiency of MD simulations through better numerical methods and, more recently, by utilizing machine learning (ML) methods. Yet, challenges remain, such as accurate modeling of extended-timescale simulations. To address this issue, we propose NeuralMD, the first ML surrogate that can facilitate numerical MD and provide accurate simulations in protein-ligand binding. We propose a principled approach that incorporates a novel physics-informed multi-grained group symmetric framework. Specifically, we propose (1) a BindingNet model that satisfies group symmetry using vector frames and captures the multi-level protein-ligand interactions, and (2) an augmented neural differential equation solver that learns the trajectory under Newtonian mechanics. For the experiment, we design ten single-trajectory and three multi-trajectory binding simulation tasks. We show the efficiency and effectiveness of NeuralMD, with a 2000$\times$ speedup over standard numerical MD simulation and outperforming all other ML approaches by up to 80% under the stability metric. We further qualitatively show that NeuralMD reaches more stable binding predictions compared to other machine learning methods.
SySMOL: A Hardware-software Co-design Framework for Ultra-Low and Fine-Grained Mixed-Precision Neural Networks
Nov 23, 2023Recent advancements in quantization and mixed-precision techniques offer significant promise for improving the run-time and energy efficiency of neural networks. In this work, we further showed that neural networks, wherein individual parameters or activations can take on different precisions ranging between 1 and 4 bits, can achieve accuracies comparable to or exceeding the full-precision counterparts. However, the deployment of such networks poses numerous challenges, stemming from the necessity to manage and control the compute/communication/storage requirements associated with these extremely fine-grained mixed precisions for each piece of data. There is a lack of existing efficient hardware and system-level support tailored to these unique and challenging requirements. Our research introduces the first novel holistic hardware-software co-design approach for these networks, which enables a continuous feedback loop between hardware design, training, and inference to facilitate systematic design exploration. As a proof-of-concept, we illustrate this co-design approach by designing new, configurable CPU SIMD architectures tailored for these networks, tightly integrating the architecture with new system-aware training and inference techniques. We perform systematic design space exploration using this framework to analyze various tradeoffs. The design for mixed-precision networks that achieves optimized tradeoffs corresponds to an architecture that supports 1, 2, and 4-bit fixed-point operations with four configurable precision patterns, when coupled with system-aware training and inference optimization -- networks trained for this design achieve accuracies that closely match full-precision accuracies, while compressing and improving run-time efficiency of the neural networks drastically by 10-20x, compared to full-precision networks.
SIMD Dataflow Co-optimization for Efficient Neural Networks Inferences on CPUs
Oct 03, 2023We address the challenges associated with deploying neural networks on CPUs, with a particular focus on minimizing inference time while maintaining accuracy. Our novel approach is to use the dataflow (i.e., computation order) of a neural network to explore data reuse opportunities using heuristic-guided analysis and a code generation framework, which enables exploration of various Single Instruction, Multiple Data (SIMD) implementations to achieve optimized neural network execution. Our results demonstrate that the dataflow that keeps outputs in SIMD registers while also maximizing both input and weight reuse consistently yields the best performance for a wide variety of inference workloads, achieving up to 3x speedup for 8-bit neural networks, and up to 4.8x speedup for binary neural networks, respectively, over the optimized implementations of neural networks today.
Representation Disparity-aware Distillation for 3D Object Detection
Aug 20, 2023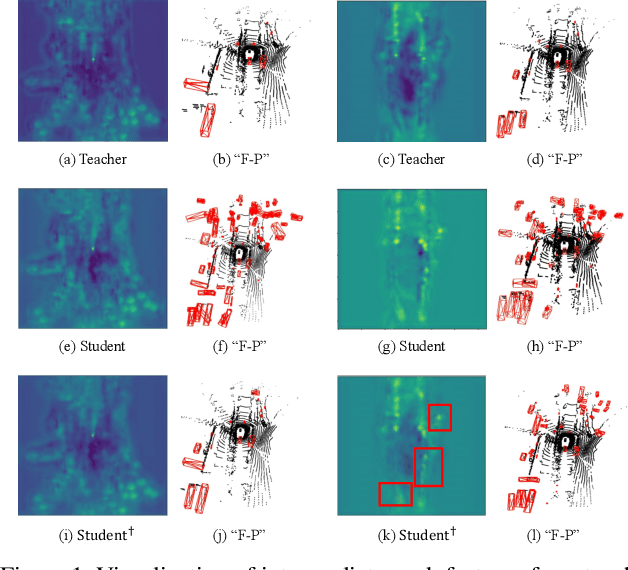
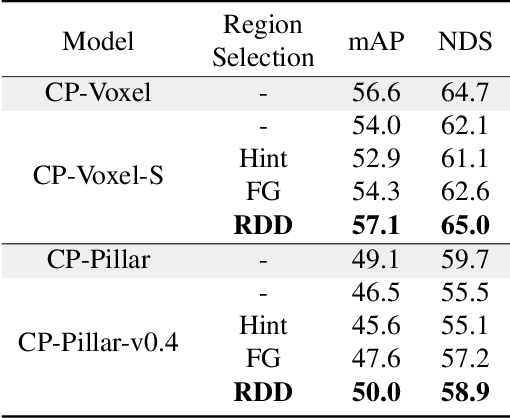
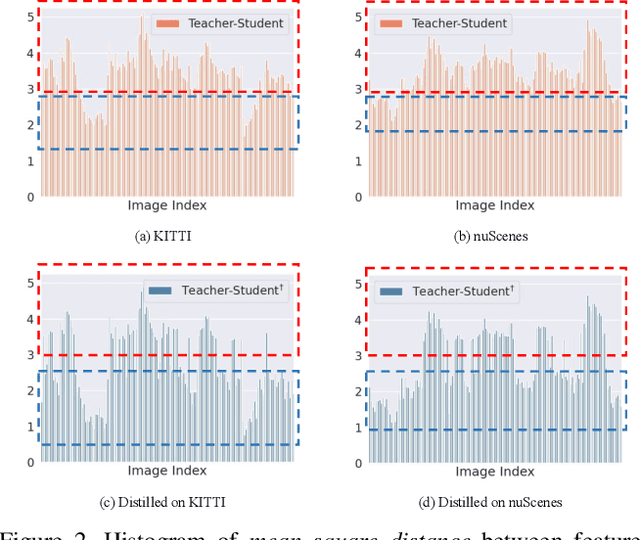
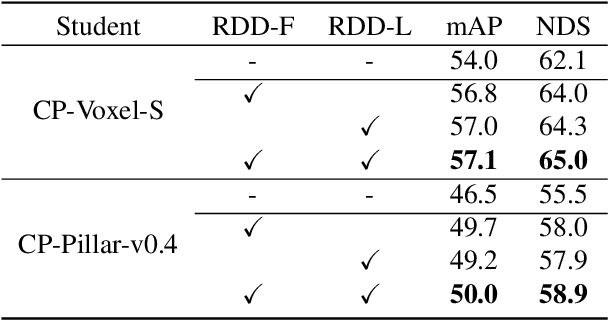
In this paper, we focus on developing knowledge distillation (KD) for compact 3D detectors. We observe that off-the-shelf KD methods manifest their efficacy only when the teacher model and student counterpart share similar intermediate feature representations. This might explain why they are less effective in building extreme-compact 3D detectors where significant representation disparity arises due primarily to the intrinsic sparsity and irregularity in 3D point clouds. This paper presents a novel representation disparity-aware distillation (RDD) method to address the representation disparity issue and reduce performance gap between compact students and over-parameterized teachers. This is accomplished by building our RDD from an innovative perspective of information bottleneck (IB), which can effectively minimize the disparity of proposal region pairs from student and teacher in features and logits. Extensive experiments are performed to demonstrate the superiority of our RDD over existing KD methods. For example, our RDD increases mAP of CP-Voxel-S to 57.1% on nuScenes dataset, which even surpasses teacher performance while taking up only 42% FLOPs.