 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
Jun 10, 2026Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports (SR) reliably predict behavior. Recent work documented substantial SR-behavior dissociation in LLMs, but relied on broad personality traits (Big 5) that predict specific behaviors weakly, even in humans. Furthermore, the isolation of conversational sessions combined with weak context matching left open whether LLMs truly lack coherence or whether the conditions needed to detect such coherence were not met. We contrast Big 5 with the Theory of Planned Behavior (TPB), which measures intention targeted to a specific behavior and predicts human behavior substantially better than broad traits. We run experiments across four behavioral tasks and 11 frontier LLMs, while also varying session context and identity induction. We find that SR-behavior coherence exists but is selective. 1) Within a shared conversation, the Theory of Planned Behavior reaches human-level coherence; Big 5 does not. 2) Across separate conversations, coherence survives only for behaviors anchored outside the immediate prompt, such as implicit bias shaped by training, and collapses when behavior is strongly primed by context, as with sycophancy. 3) Persona prompting makes self-reports more consistent across conversations, but does not bring behavior into alignment. These findings suggest that coarse personality frameworks, such as Big 5 may not be the best tools for testing deployment behavior. More task- and behavior-specific instruments are needed, and even these must be evaluated across tasks and contexts.
A Multi-Agent LLM Framework for Rating the Quality of Surgical Feedback
May 25, 2026Verbal feedback delivered by attending surgeons in the operating room plays a critical formative role in resident trainee skill acquisition. Yet, assessing the quality of trainer feedback and its effectiveness in influencing trainee behavior during live surgery remains a challenge. Prior studies assessed feedback content relying on extensive manual annotation by expert human raters and focused on developing broad taxonomies that overlook the qualitative aspects of feedback delivery such as clarity or urgency. Limited existing automated methods, including keyword analysis and topic modeling, also fail to capture these nuanced aspects. We introduce a two-stage LLM-based framework that discovers interpretable feedback quality criteria grounded in the context of surgical training. Our method uses multi-agent prompting and surgical domain knowledge injection to discover a small set of human interpretable scoring criteria (e.g., Encouraging, Urgent, Clear). These criteria are then used to automatically score live surgical feedback via an LLM-as-a-judge approach. Evaluation on 4.2k trainer feedback instances demonstrates that our AI-discovered criteria outperform prior content-based frameworks in predicting feedback effectiveness, including observed trainee behavioral adjustments and trainer approval. This work advances scalable, human-aligned assessment of communication quality in the operating room and provides a foundation for improving surgical teaching practices.
AI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
Operator Learning Using Weak Supervision from Walk-on-Spheres
Mar 03, 2026Training neural PDE solvers is often bottlenecked by expensive data generation or unstable physics-informed neural network (PINN) involving challenging optimization landscapes due to higher-order derivatives. To tackle this issue, we propose an alternative approach using Monte Carlo approaches to estimate the solution to the PDE as a stochastic process for weak supervision during training. Leveraging the Walk-on-Spheres method, we introduce a learning scheme called \emph{Walk-on-Spheres Neural Operator (WoS-NO)} which uses weak supervision from WoS to train any given neural operator. We propose to amortize the cost of Monte Carlo walks across the distribution of PDE instances using stochastic representations from the WoS algorithm to generate cheap, noisy, estimates of the PDE solution during training. This is formulated into a data-free physics-informed objective where a neural operator is trained to regress against these weak supervisions, allowing the operator to learn a generalized solution map for an entire family of PDEs. This strategy does not require expensive pre-computed datasets, avoids computing higher-order derivatives for loss functions that are memory-intensive and unstable, and demonstrates zero-shot generalization to novel PDE parameters and domains. Experiments show that for the same number of training steps, our method exhibits up to 8.75$\times$ improvement in $L_2$-error compared to standard physics-informed training schemes, up to 6.31$\times$ improvement in training speed, and reductions of up to 2.97$\times$ in GPU memory consumption. We present the code at https://github.com/neuraloperator/WoS-NO
TorchLean: Formalizing Neural Networks in Lean
Feb 26, 2026Neural networks are increasingly deployed in safety- and mission-critical pipelines, yet many verification and analysis results are produced outside the programming environment that defines and runs the model. This separation creates a semantic gap between the executed network and the analyzed artifact, so guarantees can hinge on implicit conventions such as operator semantics, tensor layouts, preprocessing, and floating-point corner cases. We introduce TorchLean, a framework in the Lean 4 theorem prover that treats learned models as first-class mathematical objects with a single, precise semantics shared by execution and verification. TorchLean unifies (1) a PyTorch-style verified API with eager and compiled modes that lower to a shared op-tagged SSA/DAG computation-graph IR, (2) explicit Float32 semantics via an executable IEEE-754 binary32 kernel and proof-relevant rounding models, and (3) verification via IBP and CROWN/LiRPA-style bound propagation with certificate checking. We validate TorchLean end-to-end on certified robustness, physics-informed residual bounds for PINNs, and Lyapunov-style neural controller verification, alongside mechanized theoretical results including a universal approximation theorem. These results demonstrate a semantics-first infrastructure for fully formal, end-to-end verification of learning-enabled systems.
Function-Space Decoupled Diffusion for Forward and Inverse Modeling in Carbon Capture and Storage
Feb 12, 2026Accurate characterization of subsurface flow is critical for Carbon Capture and Storage (CCS) but remains challenged by the ill-posed nature of inverse problems with sparse observations. We present Fun-DDPS, a generative framework that combines function-space diffusion models with differentiable neural operator surrogates for both forward and inverse modeling. Our approach learns a prior distribution over geological parameters (geomodel) using a single-channel diffusion model, then leverages a Local Neural Operator (LNO) surrogate to provide physics-consistent guidance for cross-field conditioning on the dynamics field. This decoupling allows the diffusion prior to robustly recover missing information in parameter space, while the surrogate provides efficient gradient-based guidance for data assimilation. We demonstrate Fun-DDPS on synthetic CCS modeling datasets, achieving two key results: (1) For forward modeling with only 25% observations, Fun-DDPS achieves 7.7% relative error compared to 86.9% for standard surrogates (an 11x improvement), proving its capability to handle extreme data sparsity where deterministic methods fail. (2) We provide the first rigorous validation of diffusion-based inverse solvers against asymptotically exact Rejection Sampling (RS) posteriors. Both Fun-DDPS and the joint-state baseline (Fun-DPS) achieve Jensen-Shannon divergence less than 0.06 against the ground truth. Crucially, Fun-DDPS produces physically consistent realizations free from the high-frequency artifacts observed in joint-state baselines, achieving this with 4x improved sample efficiency compared to rejection sampling.
Decoupled Diffusion Sampling for Inverse Problems on Function Spaces
Jan 30, 2026We propose a data-efficient, physics-aware generative framework in function space for inverse PDE problems. Existing plug-and-play diffusion posterior samplers represent physics implicitly through joint coefficient-solution modeling, requiring substantial paired supervision. In contrast, our Decoupled Diffusion Inverse Solver (DDIS) employs a decoupled design: an unconditional diffusion learns the coefficient prior, while a neural operator explicitly models the forward PDE for guidance. This decoupling enables superior data efficiency and effective physics-informed learning, while naturally supporting Decoupled Annealing Posterior Sampling (DAPS) to avoid over-smoothing in Diffusion Posterior Sampling (DPS). Theoretically, we prove that DDIS avoids the guidance attenuation failure of joint models when training data is scarce. Empirically, DDIS achieves state-of-the-art performance under sparse observation, improving $l_2$ error by 11% and spectral error by 54% on average; when data is limited to 1%, DDIS maintains accuracy with 40% advantage in $l_2$ error compared to joint models.
Resolution-Independent Neural Operators for Multi-Rate Sparse-View CT
Dec 13, 2025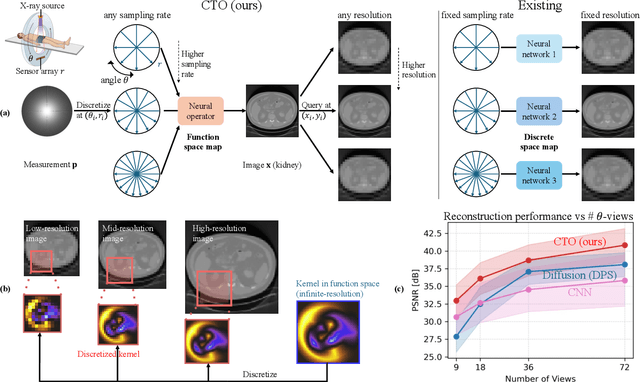
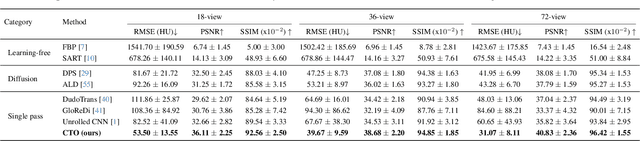
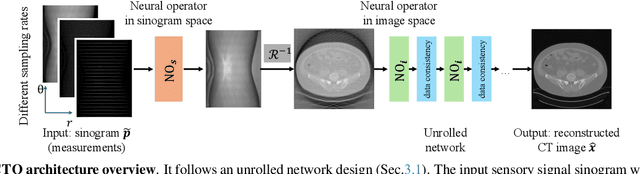
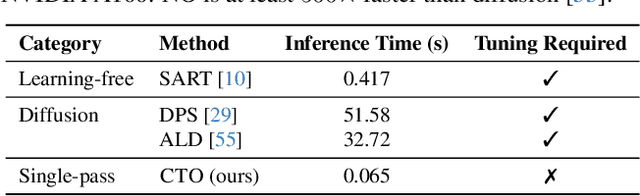
Sparse-view Computed Tomography (CT) reconstructs images from a limited number of X-ray projections to reduce radiation and scanning time, which makes reconstruction an ill-posed inverse problem. Deep learning methods achieve high-fidelity reconstructions but often overfit to a fixed acquisition setup, failing to generalize across sampling rates and image resolutions. For example, convolutional neural networks (CNNs) use the same learned kernels across resolutions, leading to artifacts when data resolution changes. We propose Computed Tomography neural Operator (CTO), a unified CT reconstruction framework that extends to continuous function space, enabling generalization (without retraining) across sampling rates and image resolutions. CTO operates jointly in the sinogram and image domains through rotation-equivariant Discrete-Continuous convolutions parametrized in the function space, making it inherently resolution- and sampling-agnostic. Empirically, CTO enables consistent multi-sampling-rate and cross-resolution performance, with on average >4dB PSNR gain over CNNs. Compared to state-of-the-art diffusion methods, CTO is 500$\times$ faster in inference time with on average 3dB gain. Empirical results also validate our design choices behind CTO's sinogram-space operator learning and rotation-equivariant convolution. Overall, CTO outperforms state-of-the-art baselines across sampling rates and resolutions, offering a scalable and generalizable solution that makes automated CT reconstruction more practical for deployment.
Self Distillation Fine-Tuning of Protein Language Models Improves Versatility in Protein Design
Dec 10, 2025Supervised fine-tuning (SFT) is a standard approach for adapting large language models to specialized domains, yet its application to protein sequence modeling and protein language models (PLMs) remains ad hoc. This is in part because high-quality annotated data are far more difficult to obtain for proteins than for natural language. We present a simple and general recipe for fast SFT of PLMs, designed to improve the fidelity, reliability, and novelty of generated protein sequences. Unlike existing approaches that require costly precompiled experimental datasets for SFT, our method leverages the PLM itself, integrating a lightweight curation pipeline with domain-specific filters to construct high-quality training data. These filters can independently refine a PLM's output and identify candidates for in vitro evaluation; when combined with SFT, they enable PLMs to generate more stable and functional enzymes, while expanding exploration into protein sequence space beyond natural variants. Although our approach is agnostic to both the choice of protein language model (PLM) and the protein system, we demonstrate its effectiveness with a genome-scale PLM (GenSLM) applied to the tryptophan synthase enzyme family. The supervised fine-tuned model generates sequences that are not only more novel but also display improved characteristics across both targeted design constraints and emergent protein property measures.
Generating Natural-Language Surgical Feedback: From Structured Representation to Domain-Grounded Evaluation
Nov 19, 2025High-quality intraoperative feedback from a surgical trainer is pivotal for improving trainee performance and long-term skill acquisition. Automating natural, trainer-style feedback promises timely, accessible, and consistent guidance at scale but requires models that understand clinically relevant representations. We present a structure-aware pipeline that learns a surgical action ontology from real trainer-to-trainee transcripts (33 surgeries) and uses it to condition feedback generation. We contribute by (1) mining Instrument-Action-Target (IAT) triplets from real-world feedback text and clustering surface forms into normalized categories, (2) fine-tuning a video-to-IAT model that leverages the surgical procedure and task contexts as well as fine-grained temporal instrument motion, and (3) demonstrating how to effectively use IAT triplet representations to guide GPT-4o in generating clinically grounded, trainer-style feedback. We show that, on Task 1: Video-to-IAT recognition, our context injection and temporal tracking deliver consistent AUC gains (Instrument: 0.67 to 0.74; Action: 0.60 to 0.63; Tissue: 0.74 to 0.79). For Task 2: feedback text generation (rated on a 1-5 fidelity rubric where 1 = opposite/unsafe, 3 = admissible, and 5 = perfect match to a human trainer), GPT-4o from video alone scores 2.17, while IAT conditioning reaches 2.44 (+12.4%), doubling the share of admissible generations with score >= 3 from 21% to 42%. Traditional text-similarity metrics also improve: word error rate decreases by 15-31% and ROUGE (phrase/substring overlap) increases by 9-64%. Grounding generation in explicit IAT structure improves fidelity and yields clinician-verifiable rationales, supporting auditable use in surgical training.