 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling
Jun 10, 2026Reinforcement learning (RL) has become a key component in modern large language models, yet the rollout stage remains the key bottleneck in RL training pipelines. Although Multi-Token Prediction (MTP) offers a natural solution to accelerate rollouts through speculative decoding, many studies have observed that MTP acceptance rates degrade significantly during RL training, leading to limited speedup performance. To address this bottleneck, we present Bebop, a systematic study of MTP in LLM post-training, and offer practical recipes to integrate MTP into large-scale RL pipelines. First, we reveal that the MTP acceptance rate is fundamentally bounded by the fluctuation of model entropy, which demonstrates a clear negative linear relationship with the rise of entropy in the RL stage. Second, we show that probabilistic rejection sampling largely alleviates the disturbance introduced by entropy in RL compared to greedy draft sampling. We further identify that the conventional MTP training objectives (cross-entropy or KL) are suboptimal in such settings, and therefore we propose a novel end-to-end TV loss that directly optimizes multi-step rejection sampling acceptance rate, yielding ~10% acceptance rate improvements, achieving up to 95% acceptance rates and up to 25% extra inference throughput gains across mathematical reasoning, code generation, and agentic tasks. Third, we test various online MTP training strategies during RL and show that pre-RL MTP training with e2e TV loss and rejection sampling achieves a consistent acceptance rate and speedup throughout the entire RL, eliminating the need for costly online MTP updating. We provide extensive experiments and analysis that validate our findings. Experimental results show our method achieves up to 1.8x end-to-end acceleration in async RL training of Qwen3.5, Qwen3.6, and Qwen3.7 models.
BrainSegNet: A Novel Framework for Whole-Brain MRI Parcellation Enhanced by Large Models
Jan 14, 2026Whole-brain parcellation from MRI is a critical yet challenging task due to the complexity of subdividing the brain into numerous small, irregular shaped regions. Traditionally, template-registration methods were used, but recent advances have shifted to deep learning for faster workflows. While large models like the Segment Anything Model (SAM) offer transferable feature representations, they are not tailored for the high precision required in brain parcellation. To address this, we propose BrainSegNet, a novel framework that adapts SAM for accurate whole-brain parcellation into 95 regions. We enhance SAM by integrating U-Net skip connections and specialized modules into its encoder and decoder, enabling fine-grained anatomical precision. Key components include a hybrid encoder combining U-Net skip connections with SAM's transformer blocks, a multi-scale attention decoder with pyramid pooling for varying-sized structures, and a boundary refinement module to sharpen edges. Experimental results on the Human Connectome Project (HCP) dataset demonstrate that BrainSegNet outperforms several state-of-the-art methods, achieving higher accuracy and robustness in complex, multi-label parcellation.
RIGOURATE: Quantifying Scientific Exaggeration with Evidence-Aligned Claim Evaluation
Jan 07, 2026Scientific rigour tends to be sidelined in favour of bold statements, leading authors to overstate claims beyond what their results support. We present RIGOURATE, a two-stage multimodal framework that retrieves supporting evidence from a paper's body and assigns each claim an overstatement score. The framework consists of a dataset of over 10K claim-evidence sets from ICLR and NeurIPS papers, annotated using eight LLMs, with overstatement scores calibrated using peer-review comments and validated through human evaluation. It employes a fine-tuned reranker for evidence retrieval and a fine-tuned model to predict overstatement scores with justification. Compared to strong baselines, RIGOURATE enables improved evidence retrieval and overstatement detection. Overall, our work operationalises evidential proportionality and supports clearer, more transparent scientific communication.
MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
Oct 21, 2025The adoption of long context windows has become a standard feature in Large Language Models (LLMs), as extended contexts significantly enhance their capacity for complex reasoning and broaden their applicability across diverse scenarios. Dynamic sparse attention is a promising approach for reducing the computational cost of long-context. However, efficiently training LLMs with dynamic sparse attention on ultra-long contexts-especially in distributed settings-remains a significant challenge, due in large part to worker- and step-level imbalance. This paper introduces MTraining, a novel distributed methodology leveraging dynamic sparse attention to enable efficient training for LLMs with ultra-long contexts. Specifically, MTraining integrates three key components: a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention. These components are designed to synergistically address the computational imbalance and communication overheads inherent in dynamic sparse attention mechanisms during the training of models with extensive context lengths. We demonstrate the efficacy of MTraining by training Qwen2.5-3B, successfully expanding its context window from 32K to 512K tokens on a cluster of 32 A100 GPUs. Our evaluations on a comprehensive suite of downstream tasks, including RULER, PG-19, InfiniteBench, and Needle In A Haystack, reveal that MTraining achieves up to a 6x higher training throughput while preserving model accuracy. Our code is available at https://github.com/microsoft/MInference/tree/main/MTraining.
SecurityLingua: Efficient Defense of LLM Jailbreak Attacks via Security-Aware Prompt Compression
Jun 15, 2025Large language models (LLMs) have achieved widespread adoption across numerous applications. However, many LLMs are vulnerable to malicious attacks even after safety alignment. These attacks typically bypass LLMs' safety guardrails by wrapping the original malicious instructions inside adversarial jailbreaks prompts. Previous research has proposed methods such as adversarial training and prompt rephrasing to mitigate these safety vulnerabilities, but these methods often reduce the utility of LLMs or lead to significant computational overhead and online latency. In this paper, we propose SecurityLingua, an effective and efficient approach to defend LLMs against jailbreak attacks via security-oriented prompt compression. Specifically, we train a prompt compressor designed to discern the "true intention" of the input prompt, with a particular focus on detecting the malicious intentions of adversarial prompts. Then, in addition to the original prompt, the intention is passed via the system prompt to the target LLM to help it identify the true intention of the request. SecurityLingua ensures a consistent user experience by leaving the original input prompt intact while revealing the user's potentially malicious intention and stimulating the built-in safety guardrails of the LLM. Moreover, thanks to prompt compression, SecurityLingua incurs only a negligible overhead and extra token cost compared to all existing defense methods, making it an especially practical solution for LLM defense. Experimental results demonstrate that SecurityLingua can effectively defend against malicious attacks and maintain utility of the LLM with negligible compute and latency overhead. Our code is available at https://aka.ms/SecurityLingua.
R-KV: Redundancy-aware KV Cache Compression for Training-Free Reasoning Models Acceleration
May 30, 2025Reasoning models have demonstrated impressive performance in self-reflection and chain-of-thought reasoning. However, they often produce excessively long outputs, leading to prohibitively large key-value (KV) caches during inference. While chain-of-thought inference significantly improves performance on complex reasoning tasks, it can also lead to reasoning failures when deployed with existing KV cache compression approaches. To address this, we propose Redundancy-aware KV Cache Compression for Reasoning models (R-KV), a novel method specifically targeting redundant tokens in reasoning models. Our method preserves nearly 100% of the full KV cache performance using only 10% of the KV cache, substantially outperforming existing KV cache baselines, which reach only 60% of the performance. Remarkably, R-KV even achieves 105% of full KV cache performance with 16% of the KV cache. This KV-cache reduction also leads to a 90% memory saving and a 6.6X throughput over standard chain-of-thought reasoning inference. Experimental results show that R-KV consistently outperforms existing KV cache compression baselines across two mathematical reasoning datasets.
Compressive Fourier-Domain Intensity Coupling (C-FOCUS) enables near-millimeter deep imaging in the intact mouse brain in vivo
May 27, 2025Two-photon microscopy is a powerful tool for in vivo imaging, but its imaging depth is typically limited to a few hundred microns due to tissue scattering, even with existing scattering correction techniques. Moreover, most active scattering correction methods are restricted to small regions by the optical memory effect. Here, we introduce compressive Fourier-domain intensity coupling for scattering correction (C-FOCUS), an active scattering correction approach that integrates Fourier-domain intensity modulation with compressive sensing for two-photon microscopy. Using C-FOCUS, we demonstrate high-resolution imaging of YFP-labeled neurons and FITC-labeled blood vessels at depths exceeding 900 um in the intact mouse brain in vivo. Furthermore, we achieve transcranial imaging of YFP-labeled dendritic structures through the intact adult mouse skull. C-FOCUS enables high-contrast fluorescence imaging at depths previously inaccessible using two-photon microscopy with 1035 nm excitation, enhancing fluorescence intensity by over 20-fold compared to uncorrected imaging. C-FOCUS provides a broadly applicable strategy for rapid, deep-tissue optical imaging in vivo.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025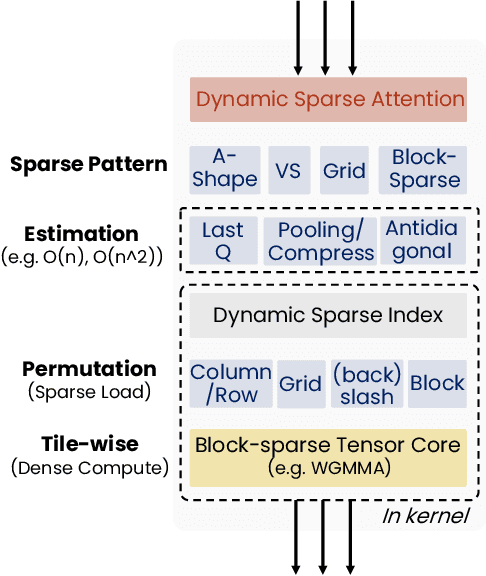
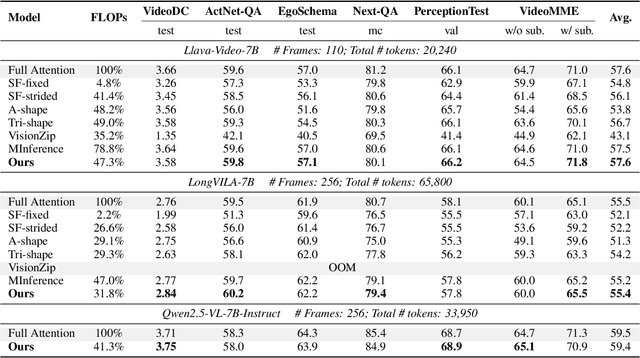
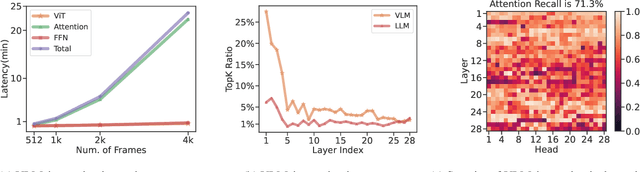

The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.
LongEval: A Comprehensive Analysis of Long-Text Generation Through a Plan-based Paradigm
Feb 26, 2025Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks, yet their ability to generate long-form content remains poorly understood and evaluated. Our analysis reveals that current LLMs struggle with length requirements and information density in long-text generation, with performance deteriorating as text length increases. To quantitively locate such a performance degradation and provide further insights on model development, we present LongEval, a benchmark that evaluates long-text generation through both direct and plan-based generation paradigms, inspired by cognitive and linguistic writing models. The comprehensive experiments in this work reveal interesting findings such as that while model size correlates with generation ability, the small-scale model (e.g., LongWriter), well-trained on long texts, has comparable performance. All code and datasets are released in https://github.com/Wusiwei0410/LongEval.
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
Dec 13, 2024



Long-context LLMs have enabled numerous downstream applications but also introduced significant challenges related to computational and memory efficiency. To address these challenges, optimizations for long-context inference have been developed, centered around the KV cache. However, existing benchmarks often evaluate in single-request, neglecting the full lifecycle of the KV cache in real-world use. This oversight is particularly critical, as KV cache reuse has become widely adopted in LLMs inference frameworks, such as vLLM and SGLang, as well as by LLM providers, including OpenAI, Microsoft, Google, and Anthropic. To address this gap, we introduce SCBench(SharedContextBench), a comprehensive benchmark for evaluating long-context methods from a KV cachecentric perspective: 1) KV cache generation, 2) KV cache compression, 3) KV cache retrieval, 4) KV cache loading. Specifically, SCBench uses test examples with shared context, ranging 12 tasks with two shared context modes, covering four categories of long-context capabilities: string retrieval, semantic retrieval, global information, and multi-task. With it, we provide an extensive KV cache-centric analysis of eight categories long-context solutions, including Gated Linear RNNs, Mamba-Attention hybrids, and efficient methods such as sparse attention, KV cache dropping, quantization, retrieval, loading, and prompt compression. The evaluation is conducted on 8 long-context LLMs. Our findings show that sub-O(n) memory methods suffer in multi-turn scenarios, while sparse encoding with O(n) memory and sub-O(n^2) pre-filling computation perform robustly. Dynamic sparsity yields more expressive KV caches than static patterns, and layer-level sparsity in hybrid architectures reduces memory usage with strong performance. Additionally, we identify attention distribution shift issues in long-generation scenarios. https://aka.ms/SCBench.