 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Reasoning Vision-Language Models Robust to Semantic Visual Distractions?
Jun 08, 2026Reasoning Vision-Language Models (VLMs) achieve strong performance on complex multimodal tasks, but reliable real-world application requires handling visual inputs that are messier than clean, curated benchmarks. Existing works mainly evaluate such reliability of VLMs through input corruptions, such as noise, blur and weather effects, which make visual evidence harder to perceive. This leaves a critical reliability failure mode underexplored: a model may perceive the evidence correctly, yet reason from plausible but irrelevant and distracting evidence and propagate this mistake to its final answer. To address this gap, we introduce \textbf{Distract-Bench}, a benchmark for evaluating VLM robustness to \textbf{semantic visual distractions}, defined as meaningful but task-irrelevant visual cues added to inputs while preserving the ground-truth answer. We comprehensively evaluate eight leading open-source and two closed-source VLMs across conventional vision corruptions and Distract-Bench. Our results show that Distract-Bench exposes a robustness failure distinct from vision corruptions: reasoning VLMs largely track their non-reasoning base models under perceptual degradation, but show consistently lower robustness to semantic distractions. Further analysis shows that these distractions often enter the reasoning process of VLMs, are treated as evidence, and lead to incorrect answers. Together, these findings reframe robustness evaluation for reasoning VLMs, shifting the focus from degraded perception to distractions for reliable real-world visual reasoning. Our data and code are available at https://github.com/Yizheng-Sun/Distract-Bench.
A Self-Evolving Framework for Efficient Terminal Agents via Observational Context Compression
Apr 21, 2026As model capabilities advance, research has increasingly shifted toward long-horizon, multi-turn terminal-centric agentic tasks, where raw environment feedback is often preserved in the interaction history to support future decisions. However, repeatedly retaining such feedback introduces substantial redundancy and causes cumulative token cost to grow quadratically with the number of steps, hindering long-horizon reasoning. Although observation compression can mitigate this issue, the heterogeneity of terminal environments makes heuristic-based or fixed-prompt methods difficult to generalize. We propose TACO, a plug-and-play, self-evolving Terminal Agent Compression framework that automatically discovers and refines compression rules from interaction trajectories for existing terminal agents. Experiments on TerminalBench (TB 1.0 and TB 2.0) and four additional terminal-related benchmarks (i.e., SWE-Bench Lite, CompileBench, DevEval, and CRUST-Bench) show that TACO consistently improves performance across mainstream agent frameworks and strong backbone models. With MiniMax-2.5, it improves performance on most benchmarks while reducing token overhead by around 10%. On TerminalBench, it brings consistent gains of 1%-4% across strong agentic models, and further improves accuracy by around 2%-3% under the same token budget. These results demonstrate the effectiveness and generalization of self-evolving, task-aware compression for terminal agents.
Large-Scale Terminal Agentic Trajectory Generation from Dockerized Environments
Feb 03, 2026Training agentic models for terminal-based tasks critically depends on high-quality terminal trajectories that capture realistic long-horizon interactions across diverse domains. However, constructing such data at scale remains challenging due to two key requirements: \textbf{\emph{Executability}}, since each instance requires a suitable and often distinct Docker environment; and \textbf{\emph{Verifiability}}, because heterogeneous task outputs preclude unified, standardized verification. To address these challenges, we propose \textbf{TerminalTraj}, a scalable pipeline that (i) filters high-quality repositories to construct Dockerized execution environments, (ii) generates Docker-aligned task instances, and (iii) synthesizes agent trajectories with executable validation code. Using TerminalTraj, we curate 32K Docker images and generate 50,733 verified terminal trajectories across eight domains. Models trained on this data with the Qwen2.5-Coder backbone achieve consistent performance improvements on TerminalBench (TB), with gains of up to 20\% on TB~1.0 and 10\% on TB~2.0 over their respective backbones. Notably, \textbf{TerminalTraj-32B} achieves strong performance among models with fewer than 100B parameters, reaching 35.30\% on TB~1.0 and 22.00\% on TB~2.0, and demonstrates improved test-time scaling behavior. All code and data are available at https://github.com/Wusiwei0410/TerminalTraj.
Natural Language Satisfiability: Exploring the Problem Distribution and Evaluating Transformer-based Language Models
Aug 23, 2025Efforts to apply transformer-based language models (TLMs) to the problem of reasoning in natural language have enjoyed ever-increasing success in recent years. The most fundamental task in this area to which nearly all others can be reduced is that of determining satisfiability. However, from a logical point of view, satisfiability problems vary along various dimensions, which may affect TLMs' ability to learn how to solve them. The problem instances of satisfiability in natural language can belong to different computational complexity classes depending on the language fragment in which they are expressed. Although prior research has explored the problem of natural language satisfiability, the above-mentioned point has not been discussed adequately. Hence, we investigate how problem instances from varying computational complexity classes and having different grammatical constructs impact TLMs' ability to learn rules of inference. Furthermore, to faithfully evaluate TLMs, we conduct an empirical study to explore the distribution of satisfiability problems.
* The paper was accepted to the 62nd Association for Computational Linguistics (ACL 2024), where it won the Best Paper Award
Silent Hazards of Token Reduction in Vision-Language Models: The Hidden Impact on Consistency
Mar 11, 2025


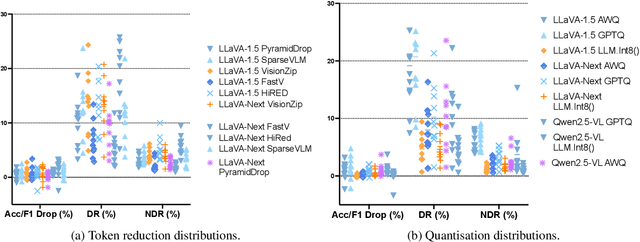
Vision language models (VLMs) have excelled in visual reasoning but often incur high computational costs. One key reason is the redundancy of visual tokens. Although recent token reduction methods claim to achieve minimal performance loss, our extensive experiments reveal that token reduction can substantially alter a model's output distribution, leading to changes in prediction patterns that standard metrics such as accuracy loss do not fully capture. Such inconsistencies are especially concerning for practical applications where system stability is critical. To investigate this phenomenon, we analyze how token reduction influences the energy distribution of a VLM's internal representations using a lower-rank approximation via Singular Value Decomposition (SVD). Our results show that changes in the Inverse Participation Ratio of the singular value spectrum are strongly correlated with the model's consistency after token reduction. Based on these insights, we propose LoFi--a training-free visual token reduction method that utilizes the leverage score from SVD for token pruning. Experimental evaluations demonstrate that LoFi not only reduces computational costs with minimal performance degradation but also significantly outperforms state-of-the-art methods in terms of output consistency.
BRIDGE: Bootstrapping Text to Control Time-Series Generation via Multi-Agent Iterative Optimization and Diffusion Modelling
Mar 05, 2025



Time-series Generation (TSG) is a prominent research area with broad applications in simulations, data augmentation, and counterfactual analysis. While existing methods have shown promise in unconditional single-domain TSG, real-world applications demand for cross-domain approaches capable of controlled generation tailored to domain-specific constraints and instance-level requirements. In this paper, we argue that text can provide semantic insights, domain information and instance-specific temporal patterns, to guide and improve TSG. We introduce ``Text-Controlled TSG'', a task focused on generating realistic time series by incorporating textual descriptions. To address data scarcity in this setting, we propose a novel LLM-based Multi-Agent framework that synthesizes diverse, realistic text-to-TS datasets. Furthermore, we introduce BRIDGE, a hybrid text-controlled TSG framework that integrates semantic prototypes with text description for supporting domain-level guidance. This approach achieves state-of-the-art generation fidelity on 11 of 12 datasets, and improves controllability by 12.52% on MSE and 6.34% MAE compared to no text input generation, highlighting its potential for generating tailored time-series data.
LongEval: A Comprehensive Analysis of Long-Text Generation Through a Plan-based Paradigm
Feb 26, 2025Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks, yet their ability to generate long-form content remains poorly understood and evaluated. Our analysis reveals that current LLMs struggle with length requirements and information density in long-text generation, with performance deteriorating as text length increases. To quantitively locate such a performance degradation and provide further insights on model development, we present LongEval, a benchmark that evaluates long-text generation through both direct and plan-based generation paradigms, inspired by cognitive and linguistic writing models. The comprehensive experiments in this work reveal interesting findings such as that while model size correlates with generation ability, the small-scale model (e.g., LongWriter), well-trained on long texts, has comparable performance. All code and datasets are released in https://github.com/Wusiwei0410/LongEval.
Pay Attention to Real World Perturbations! Natural Robustness Evaluation in Machine Reading Comprehension
Feb 23, 2025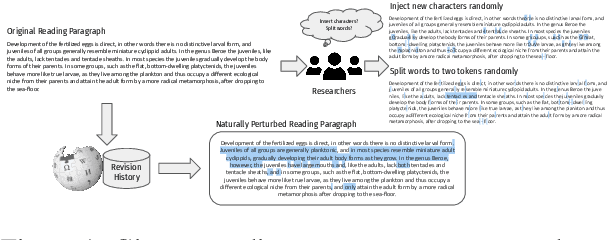
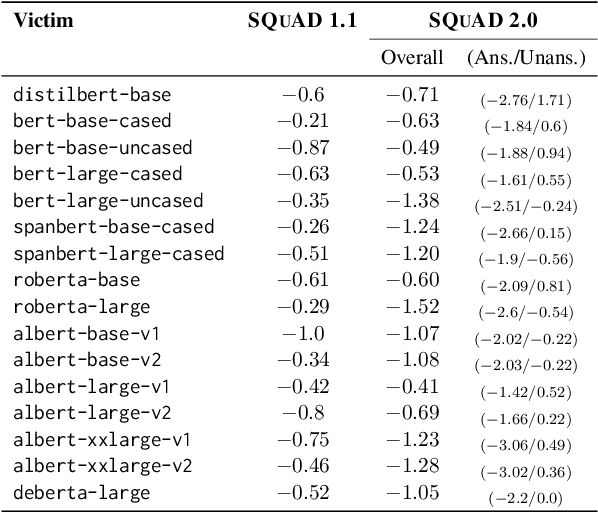
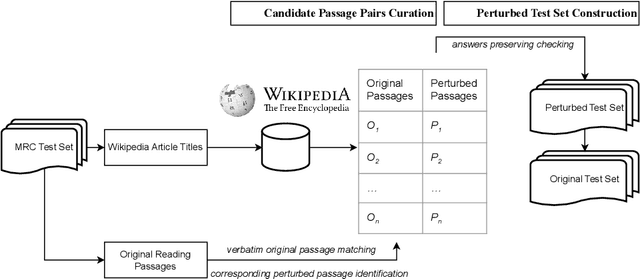
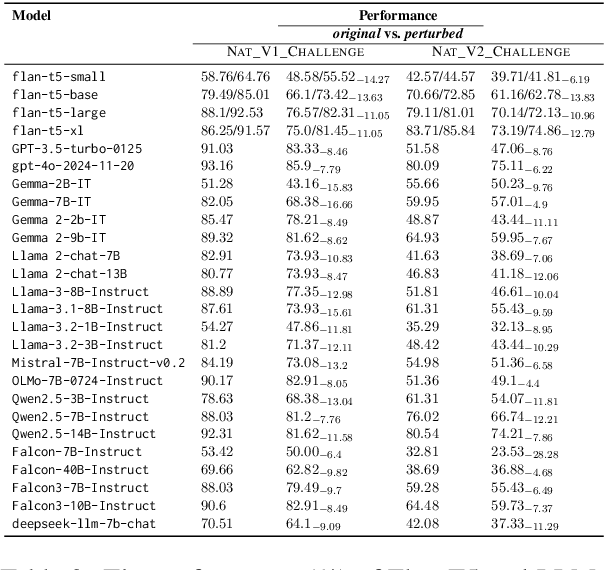
As neural language models achieve human-comparable performance on Machine Reading Comprehension (MRC) and see widespread adoption, ensuring their robustness in real-world scenarios has become increasingly important. Current robustness evaluation research, though, primarily develops synthetic perturbation methods, leaving unclear how well they reflect real life scenarios. Considering this, we present a framework to automatically examine MRC models on naturally occurring textual perturbations, by replacing paragraph in MRC benchmarks with their counterparts based on available Wikipedia edit history. Such perturbation type is natural as its design does not stem from an arteficial generative process, inherently distinct from the previously investigated synthetic approaches. In a large-scale study encompassing SQUAD datasets and various model architectures we observe that natural perturbations result in performance degradation in pre-trained encoder language models. More worryingly, these state-of-the-art Flan-T5 and Large Language Models (LLMs) inherit these errors. Further experiments demonstrate that our findings generalise to natural perturbations found in other more challenging MRC benchmarks. In an effort to mitigate these errors, we show that it is possible to improve the robustness to natural perturbations by training on naturally or synthetically perturbed examples, though a noticeable gap still remains compared to performance on unperturbed data.
LVPruning: An Effective yet Simple Language-Guided Vision Token Pruning Approach for Multi-modal Large Language Models
Jan 23, 2025



Multi-modal Large Language Models (MLLMs) have achieved remarkable success by integrating visual and textual modalities. However, they incur significant computational overhead due to the large number of vision tokens processed, limiting their practicality in resource-constrained environments. We introduce Language-Guided Vision Token Pruning (LVPruning) for MLLMs, an effective yet simple method that significantly reduces the computational burden while preserving model performance. LVPruning employs cross-attention modules to compute the importance of vision tokens based on their interaction with language tokens, determining which to prune. Importantly, LVPruning can be integrated without modifying the original MLLM parameters, which makes LVPruning simple to apply or remove. Our experiments show that LVPruning can effectively reduce up to 90% of vision tokens by the middle layer of LLaVA-1.5, resulting in a 62.1% decrease in inference Tera Floating-Point Operations Per Second (TFLOPs), with an average performance loss of just 0.45% across nine multi-modal benchmarks.
TriG-NER: Triplet-Grid Framework for Discontinuous Named Entity Recognition
Nov 04, 2024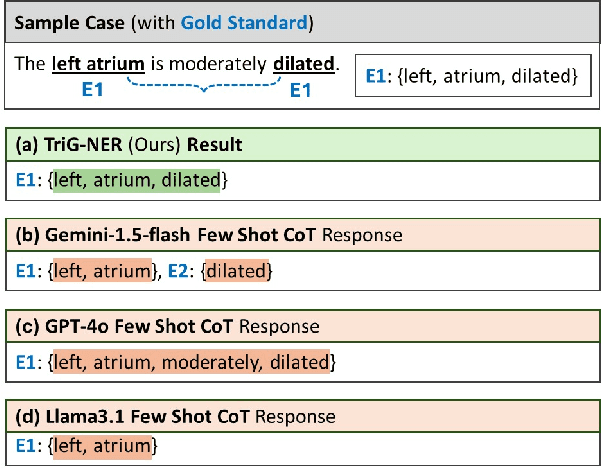
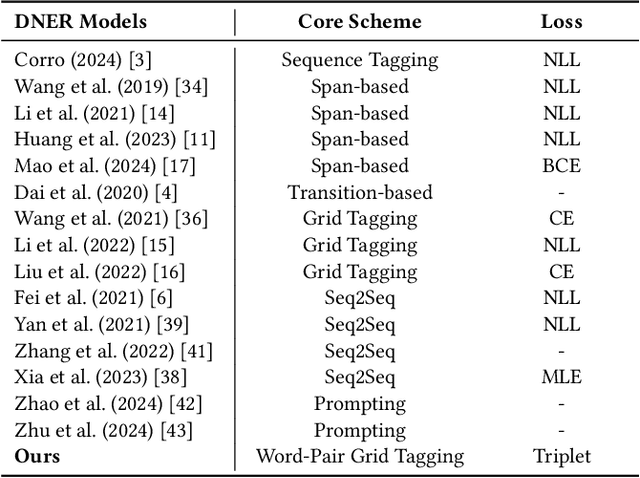
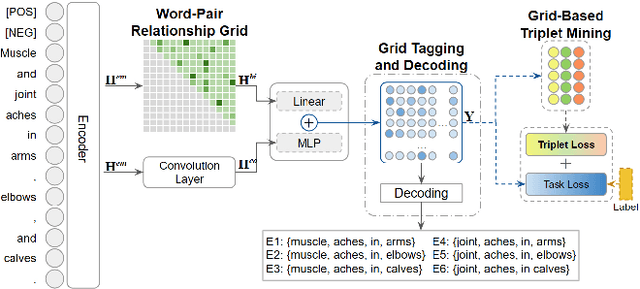
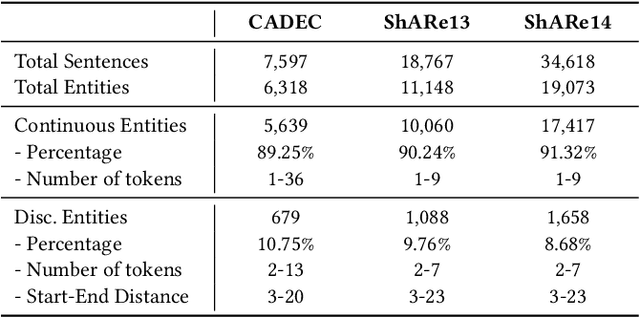
Discontinuous Named Entity Recognition (DNER) presents a challenging problem where entities may be scattered across multiple non-adjacent tokens, making traditional sequence labelling approaches inadequate. Existing methods predominantly rely on custom tagging schemes to handle these discontinuous entities, resulting in models tightly coupled to specific tagging strategies and lacking generalisability across diverse datasets. To address these challenges, we propose TriG-NER, a novel Triplet-Grid Framework that introduces a generalisable approach to learning robust token-level representations for discontinuous entity extraction. Our framework applies triplet loss at the token level, where similarity is defined by word pairs existing within the same entity, effectively pulling together similar and pushing apart dissimilar ones. This approach enhances entity boundary detection and reduces the dependency on specific tagging schemes by focusing on word-pair relationships within a flexible grid structure. We evaluate TriG-NER on three benchmark DNER datasets and demonstrate significant improvements over existing grid-based architectures. These results underscore our framework's effectiveness in capturing complex entity structures and its adaptability to various tagging schemes, setting a new benchmark for discontinuous entity extraction.