 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Correct Decisions Hide Internal Stress: Decision-State Probing in Multimodal Language Models
Jun 07, 2026Multimodal language models are typically evaluated through external behavior: selecting the correct image--text match, rejecting unsupported captions, or answering visual queries correctly. However, correct behavior alone does not show that the model's internal decision state remains stable under controlled semantic stress. We study this gap through S$^3$E (Structured Semantic Stress Evaluation), a framework for analyzing behavior-internal decoupling in multimodal language models. S$^3$E uses a positive-anchored A/B forced-choice setup in which an image-supported caption is contrasted against semantic stress candidates under both original and swapped option orders, while hidden states are extracted at the pre-answer decision state. We focus on strict-correct trials, where the model consistently selects the correct caption across both orders. Rather than treating arbitrary hidden-state variation as evidence of instability, we measure whether semantic-conflict candidates induce excess decision-state displacement relative to meaning-preserving controls. Across Qwen3VL, Gemma3, and InternVL3, semantic stress consistently produces positive selected-layer excess displacement over lexical controls despite correct forced-choice behavior, while comparisons against random negatives are model-dependent. We interpret this as a scoped decision-state stress-sensitivity signal rather than evidence of downstream failure or hallucination. Our results suggest that forced-choice correctness alone is not a sufficient certificate of invariant internal decision geometry.
ToolTree: Efficient LLM Agent Tool Planning via Dual-Feedback Monte Carlo Tree Search and Bidirectional Pruning
Mar 13, 2026Large Language Model (LLM) agents are increasingly applied to complex, multi-step tasks that require interaction with diverse external tools across various domains. However, current LLM agent tool planning methods typically rely on greedy, reactive tool selection strategies that lack foresight and fail to account for inter-tool dependencies. In this paper, we present ToolTree, a novel Monte Carlo tree search-inspired planning paradigm for tool planning. ToolTree explores possible tool usage trajectories using a dual-stage LLM evaluation and bidirectional pruning mechanism that enables the agent to make informed, adaptive decisions over extended tool-use sequences while pruning less promising branches before and after the tool execution. Empirical evaluations across both open-set and closed-set tool planning tasks on 4 benchmarks demonstrate that ToolTree consistently improves performance while keeping the highest efficiency, achieving an average gain of around 10\% compared to the state-of-the-art planning paradigm.
BRIDGE: Benchmark for multi-hop Reasoning In long multimodal Documents with Grounded Evidence
Mar 09, 2026Multi-hop question answering (QA) is widely used to evaluate the reasoning capabilities of large language models, yet most benchmarks focus on final answer correctness and overlook intermediate reasoning, especially in long multimodal documents. We introduce BRIDGE, a benchmark for multi-hop reasoning over long scientific papers that require integrating evidence across text, tables, and figures. The dataset supports both chain-like and fan-out structures and provides explicit multi-hop reasoning annotations for step-level evaluation beyond answer accuracy. Experiments with state-of-the-art LLMs and multimodal retrieval-augmented generation (RAG) systems reveal systematic deficiencies in evidence aggregation and grounding that remain hidden under conventional answer-only evaluation. BRIDGE provides a targeted testbed for diagnosing reasoning failures in long multimodal documents.
EvoTool: Self-Evolving Tool-Use Policy Optimization in LLM Agents via Blame-Aware Mutation and Diversity-Aware Selection
Mar 05, 2026LLM-based agents depend on effective tool-use policies to solve complex tasks, yet optimizing these policies remains challenging due to delayed supervision and the difficulty of credit assignment in long-horizon trajectories. Existing optimization approaches tend to be either monolithic, which are prone to entangling behaviors, or single-aspect, which ignore cross-module error propagation. To address these limitations, we propose EvoTool, a self-evolving framework that optimizes a modular tool-use policy via a gradient-free evolutionary paradigm. EvoTool decomposes agent's tool-use policy into four modules, including Planner, Selector, Caller, and Synthesizer, and iteratively improves them in a self-improving loop through three novel mechanisms. Trajectory-Grounded Blame Attribution uses diagnostic traces to localize failures to a specific module. Feedback-Guided Targeted Mutation then edits only that module via natural-language critique. Diversity-Aware Population Selection preserves complementary candidates to ensure solution diversity. Across four benchmarks, EvoTool outperforms strong baselines by over 5 points on both GPT-4.1 and Qwen3-8B, while achieving superior efficiency and transferability. The code will be released once paper is accepted.
When More Is Less: A Systematic Analysis of Spatial and Commonsense Information for Visual Spatial Reasoning
Feb 25, 2026Visual spatial reasoning (VSR) remains challenging for modern vision-language models (VLMs), despite advances in multimodal architectures. A common strategy is to inject additional information at inference time, such as explicit spatial cues, external commonsense knowledge, or chain-of-thought (CoT) reasoning instructions. However, it remains unclear when such information genuinely improves reasoning and when it introduces noise. In this paper, we conduct a hypothesis-driven analysis of information injection for VSR across three representative VLMs and two public benchmarks. We examine (i) the type and number of spatial contexts, (ii) the amount and relevance of injected commonsense knowledge, and (iii) the interaction between spatial grounding and CoT prompting. Our results reveal a consistent pattern: more information does not necessarily yield better reasoning. Targeted single spatial cues outperform multi-context aggregation, excessive or weakly relevant commonsense knowledge degrades performance, and CoT prompting improves accuracy only when spatial grounding is sufficiently precise. These findings highlight the importance of selective, task-aligned information injection and provide practical guidance for designing reliable multimodal reasoning pipelines.
Physics-based phenomenological characterization of cross-modal bias in multimodal models
Feb 24, 2026The term 'algorithmic fairness' is used to evaluate whether AI models operate fairly in both comparative (where fairness is understood as formal equality, such as "treat like cases as like") and non-comparative (where unfairness arises from the model's inaccuracy, arbitrariness, or inscrutability) contexts. Recent advances in multimodal large language models (MLLMs) are breaking new ground in multimodal understanding, reasoning, and generation; however, we argue that inconspicuous distortions arising from complex multimodal interaction dynamics can lead to systematic bias. The purpose of this position paper is twofold: first, it is intended to acquaint AI researchers with phenomenological explainable approaches that rely on the physical entities that the machine experiences during training/inference, as opposed to the traditional cognitivist symbolic account or metaphysical approaches; second, it is to state that this phenomenological doctrine will be practically useful for tackling algorithmic fairness issues in MLLMs. We develop a surrogate physics-based model that describes transformer dynamics (i.e., semantic network structure and self-/cross-attention) to analyze the dynamics of cross-modal bias in MLLM, which are not fully captured by conventional embedding- or representation-level analyses. We support this position through multi-input diagnostic experiments: 1) perturbation-based analyses of emotion classification using Qwen2.5-Omni and Gemma 3n, and 2) dynamical analysis of Lorenz chaotic time-series prediction through the physical surrogate. Across two architecturally distinct MLLMs, we show that multimodal inputs can reinforce modality dominance rather than mitigate it, as revealed by structured error-attractor patterns under systematic label perturbation, complemented by dynamical analysis.
Diagnosing Causal Reasoning in Vision-Language Models via Structured Relevance Graphs
Feb 24, 2026Large Vision-Language Models (LVLMs) achieve strong performance on visual question answering benchmarks, yet often rely on spurious correlations rather than genuine causal reasoning. Existing evaluations primarily assess the correctness of the answers, making it unclear whether failures arise from limited reasoning capability or from misidentifying causally relevant information. We introduce Vision-Language Causal Graphs (VLCGs), a structured, query-conditioned representation that explicitly encodes causally relevant objects, attributes, relations, and scene-grounded assumptions. Building on this representation, we present ViLCaR, a diagnostic benchmark comprising tasks for Causal Attribution, Causal Inference, and Question Answering, along with graph-aligned evaluation metrics that assess relevance identification beyond final answer accuracy. Experiments in state-of-the-art LVLMs show that injecting structured relevance information significantly improves attribution and inference consistency compared to zero-shot and standard in-context learning. These findings suggest that current limitations in LVLM causal reasoning stem primarily from insufficient structural guidance rather than a lack of reasoning capacity.
When Is Rank-1 Enough? Geometry-Guided Initialization for Parameter-Efficient Fine-Tuning
Feb 02, 2026Parameter-efficient fine-tuning (PEFT) is a standard way to adapt multimodal large language models, yet extremely low-rank settings -- especially rank-1 LoRA -- are often unstable. We show that this instability is not solely due to limited capacity: in the rank-1 regime, optimization is highly sensitive to the update direction. Concretely, pretrained vision and text features form mismatched anisotropic regions, yielding a dominant "gap" direction that acts like a translation component and disproportionately steers early gradients under rank-1 constraints. Analyzing pretrained representations, we identify a modality-gap axis that dominates early gradient flow, while a random rank-1 initialization is unlikely to align with it, leading to weak gradients and training collapse. We propose Gap-Init, a geometry-aware initialization that aligns the rank-1 LoRA direction with an estimated modality-gap vector from a small calibration set, while keeping the initial LoRA update zero. Across multiple vision-language tasks and backbones, Gap-Init consistently stabilizes rank-1 training and can match or outperform strong rank-8 baselines. Our results suggest that at the extreme low-rank limit, initial alignment can matter as much as rank itself.
HierCon: Hierarchical Contrastive Attention for Audio Deepfake Detection
Feb 01, 2026Audio deepfakes generated by modern TTS and voice conversion systems are increasingly difficult to distinguish from real speech, raising serious risks for security and online trust. While state-of-the-art self-supervised models provide rich multi-layer representations, existing detectors treat layers independently and overlook temporal and hierarchical dependencies critical for identifying synthetic artefacts. We propose HierCon, a hierarchical layer attention framework combined with margin-based contrastive learning that models dependencies across temporal frames, neighbouring layers, and layer groups, while encouraging domain-invariant embeddings. Evaluated on ASVspoof 2021 DF and In-the-Wild datasets, our method achieves state-of-the-art performance (1.93% and 6.87% EER), improving over independent layer weighting by 36.6% and 22.5% respectively. The results and attention visualisations confirm that hierarchical modelling enhances generalisation to cross-domain generation techniques and recording conditions.
MAP4TS: A Multi-Aspect Prompting Framework for Time-Series Forecasting with Large Language Models
Oct 27, 2025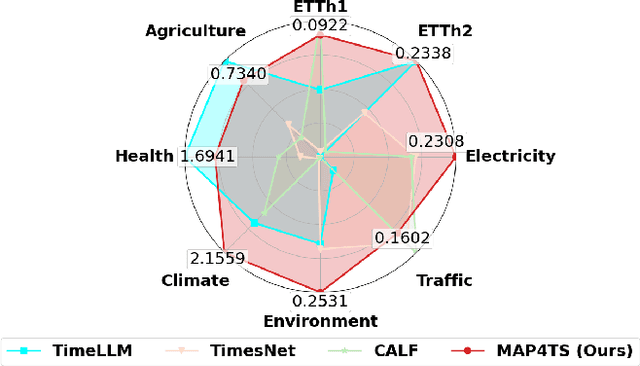
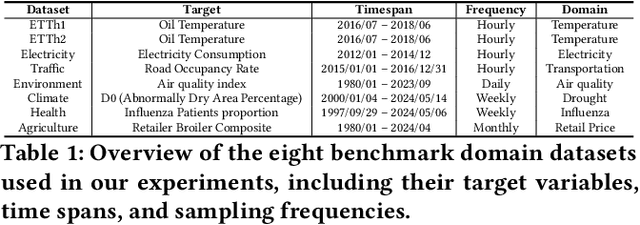
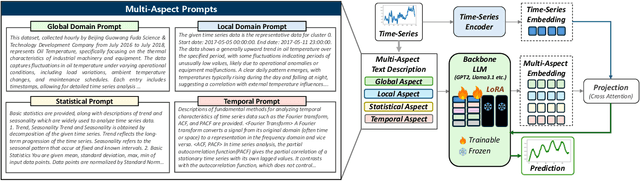
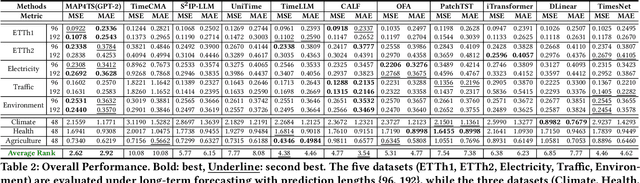
Recent advances have investigated the use of pretrained large language models (LLMs) for time-series forecasting by aligning numerical inputs with LLM embedding spaces. However, existing multimodal approaches often overlook the distinct statistical properties and temporal dependencies that are fundamental to time-series data. To bridge this gap, we propose MAP4TS, a novel Multi-Aspect Prompting Framework that explicitly incorporates classical time-series analysis into the prompt design. Our framework introduces four specialized prompt components: a Global Domain Prompt that conveys dataset-level context, a Local Domain Prompt that encodes recent trends and series-specific behaviors, and a pair of Statistical and Temporal Prompts that embed handcrafted insights derived from autocorrelation (ACF), partial autocorrelation (PACF), and Fourier analysis. Multi-Aspect Prompts are combined with raw time-series embeddings and passed through a cross-modality alignment module to produce unified representations, which are then processed by an LLM and projected for final forecasting. Extensive experiments across eight diverse datasets show that MAP4TS consistently outperforms state-of-the-art LLM-based methods. Our ablation studies further reveal that prompt-aware designs significantly enhance performance stability and that GPT-2 backbones, when paired with structured prompts, outperform larger models like LLaMA in long-term forecasting tasks.