 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Object-Level Reconstruction via Probabilistic Gaussian Splatting
Mar 15, 2026Object-level 3D reconstruction play important roles across domains such as cultural heritage digitization, industrial manufacturing, and virtual reality. However, existing Gaussian Splatting-based approaches generally rely on full-scene reconstruction, in which substantial redundant background information is introduced, leading to increased computational and storage overhead. To address this limitation, we propose an efficient single-object 3D reconstruction method based on 2D Gaussian Splatting. By directly integrating foreground-background probability cues into Gaussian primitives and dynamically pruning low-probability Gaussians during training, the proposed method fundamentally focuses on an object of interest and improves the memory and computational efficiency. Our pipeline leverages probability masks generated by YOLO and SAM to supervise probabilistic Gaussian attributes, replacing binary masks with continuous probability values to mitigate boundary ambiguity. Additionally, we propose a dual-stage filtering strategy for training's startup to suppress background Gaussians. And, during training, rendered probability masks are conversely employed to refine supervision and enhance boundary consistency across views. Experiments conducted on the MIP-360, T&T, and NVOS datasets demonstrate that our method exhibits strong self-correction capability in the presence of mask errors and achieves reconstruction quality comparable to standard 3DGS approaches, while requiring only approximately 1/10 of their Gaussian amount. These results validate the efficiency and robustness of our method for single-object reconstruction and highlight its potential for applications requiring both high fidelity and computational efficiency.
GO-N3RDet: Geometry Optimized NeRF-enhanced 3D Object Detector
Mar 19, 2025We propose GO-N3RDet, a scene-geometry optimized multi-view 3D object detector enhanced by neural radiance fields. The key to accurate 3D object detection is in effective voxel representation. However, due to occlusion and lack of 3D information, constructing 3D features from multi-view 2D images is challenging. Addressing that, we introduce a unique 3D positional information embedded voxel optimization mechanism to fuse multi-view features. To prioritize neural field reconstruction in object regions, we also devise a double importance sampling scheme for the NeRF branch of our detector. We additionally propose an opacity optimization module for precise voxel opacity prediction by enforcing multi-view consistency constraints. Moreover, to further improve voxel density consistency across multiple perspectives, we incorporate ray distance as a weighting factor to minimize cumulative ray errors. Our unique modules synergetically form an end-to-end neural model that establishes new state-of-the-art in NeRF-based multi-view 3D detection, verified with extensive experiments on ScanNet and ARKITScenes. Code will be available at https://github.com/ZechuanLi/GO-N3RDet.
PointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Mar 11, 2025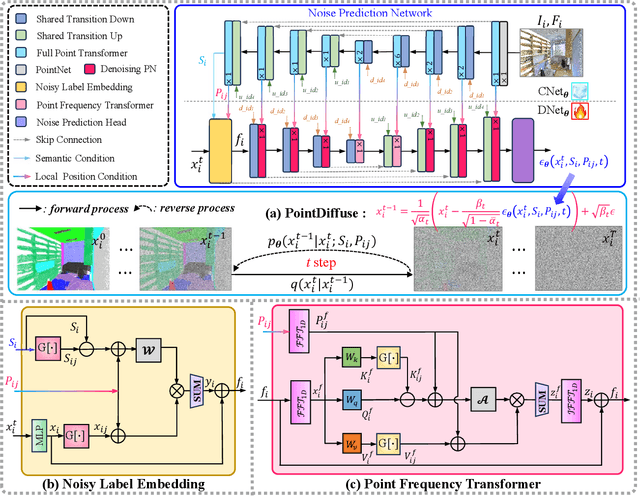



Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2\% on S3DIS Area 5, 81.2\% on S3DIS 6-fold and 64.8\% on SWAN dataset.
A Training-Free Length Extrapolation Approach for LLMs: Greedy Attention Logit Interpolation (GALI)
Feb 04, 2025Transformer-based Large Language Models (LLMs) struggle to process inputs exceeding their training context window, with performance degrading due to positional out-of-distribution (O.O.D.) that disrupt attention computations. Existing solutions, fine-tuning and training-free methods, are limited by computational inefficiency, attention logit outliers or loss of local positional information. To address this, we propose Greedy Attention Logit Interpolation (GALI), a training-free length extrapolation method that maximizes the utilization of pretrained positional intervals while avoiding attention logit outliers through attention logit interpolation. The result demonstrates that GALI consistently outperforms state-of-the-art training-free methods. Our findings reveal that LLMs interpret positional intervals unevenly within their training context window, suggesting that extrapolating within a smaller positional interval range yields superior results-even for short-context tasks. GALI represents a significant step toward resolving the positional O.O.D. challenge, enabling more reliable long-text understanding in LLMs. Our implementation of GALI, along with the experiments from our paper, is open-sourced at https://github.com/AcademyCityL/GALI.
DAViD: Domain Adaptive Visually-Rich Document Understanding with Synthetic Insights
Oct 02, 2024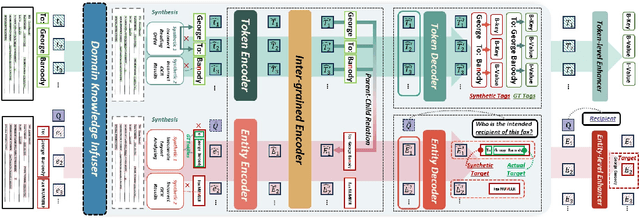
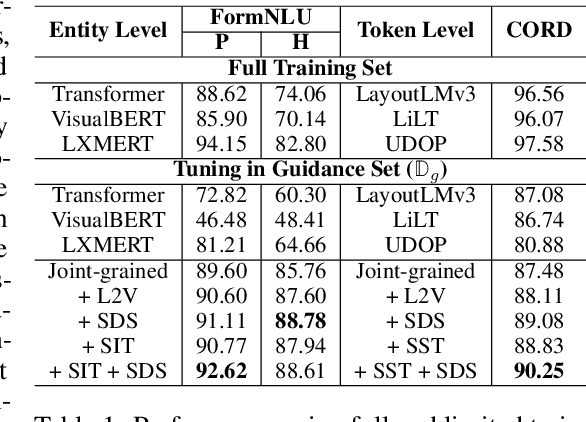
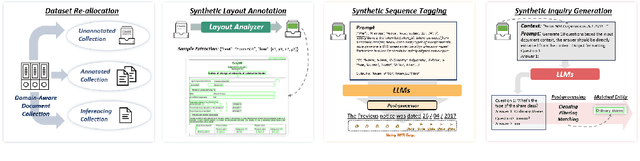
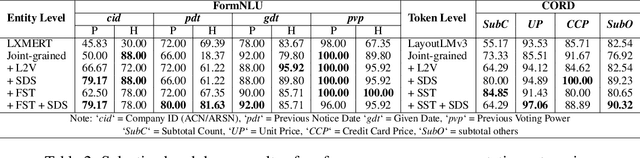
Visually-Rich Documents (VRDs), encompassing elements like charts, tables, and references, convey complex information across various fields. However, extracting information from these rich documents is labor-intensive, especially given their inconsistent formats and domain-specific requirements. While pretrained models for VRD Understanding have progressed, their reliance on large, annotated datasets limits scalability. This paper introduces the Domain Adaptive Visually-rich Document Understanding (DAViD) framework, which utilises machine-generated synthetic data for domain adaptation. DAViD integrates fine-grained and coarse-grained document representation learning and employs synthetic annotations to reduce the need for costly manual labelling. By leveraging pretrained models and synthetic data, DAViD achieves competitive performance with minimal annotated datasets. Extensive experiments validate DAViD's effectiveness, demonstrating its ability to efficiently adapt to domain-specific VRDU tasks.
Beyond Full Label: Single-Point Prompt for Infrared Small Target Label Generation
Aug 15, 2024



In this work, we make the first attempt to construct a learning-based single-point annotation paradigm for infrared small target label generation (IRSTLG). Our intuition is that label generation requires just one more point prompt than target detection: IRSTLG can be regarded as an infrared small target detection (IRSTD) task with the target location hint. Based on this insight, we introduce an energy double guided single-point prompt (EDGSP) framework, which adeptly transforms the target detection network into a refined label generation method. Specifically, the proposed EDGSP includes: 1) target energy initialization (TEI) to create a foundational outline for sufficient shape evolution of pseudo label, 2) double prompt embedding (DPE) for rapid localization of interested regions and reinforcement of individual differences to avoid label adhesion, and 3) bounding box-based matching (BBM) to eliminate false alarms. Experimental results show that pseudo labels generated by three baselines equipped with EDGSP achieve 100% object-level probability of detection (Pd) and 0% false-alarm rate (Fa) on SIRST, NUDT-SIRST, and IRSTD-1k datasets, with a pixel-level intersection over union (IoU) improvement of 13.28% over state-of-the-art label generation methods. Additionally, the downstream detection task reveals that our centroid-annotated pseudo labels surpass full labels, even with coarse single-point annotations, it still achieves 99.5% performance of full labeling.
OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition
Nov 30, 2023Due to the resource-intensive nature of training vision-language models on expansive video data, a majority of studies have centered on adapting pre-trained image-language models to the video domain. Dominant pipelines propose to tackle the visual discrepancies with additional temporal learners while overlooking the substantial discrepancy for web-scaled descriptive narratives and concise action category names, leading to less distinct semantic space and potential performance limitations. In this work, we prioritize the refinement of text knowledge to facilitate generalizable video recognition. To address the limitations of the less distinct semantic space of category names, we prompt a large language model (LLM) to augment action class names into Spatio-Temporal Descriptors thus bridging the textual discrepancy and serving as a knowledge base for general recognition. Moreover, to assign the best descriptors with different video instances, we propose Optimal Descriptor Solver, forming the video recognition problem as solving the optimal matching flow across frame-level representations and descriptors. Comprehensive evaluations in zero-shot, few-shot, and fully supervised video recognition highlight the effectiveness of our approach. Our best model achieves a state-of-the-art zero-shot accuracy of 75.1% on Kinetics-600.
First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment
Jun 23, 2023



Affordance-Centric Question-driven Task Completion (AQTC) has been proposed to acquire knowledge from videos to furnish users with comprehensive and systematic instructions. However, existing methods have hitherto neglected the necessity of aligning spatiotemporal visual and linguistic signals, as well as the crucial interactional information between humans and objects. To tackle these limitations, we propose to combine large-scale pre-trained vision-language and video-language models, which serve to contribute stable and reliable multimodal data and facilitate effective spatiotemporal visual-textual alignment. Additionally, a novel hand-object-interaction (HOI) aggregation module is proposed which aids in capturing human-object interaction information, thereby further augmenting the capacity to understand the presented scenario. Our method achieved first place in the CVPR'2023 AQTC Challenge, with a Recall@1 score of 78.7\%. The code is available at https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC.