 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning based infrared small object segmentation: Challenges and future directions
Feb 20, 2025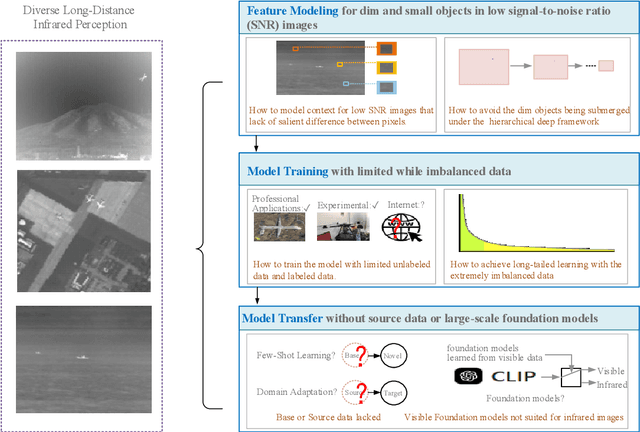

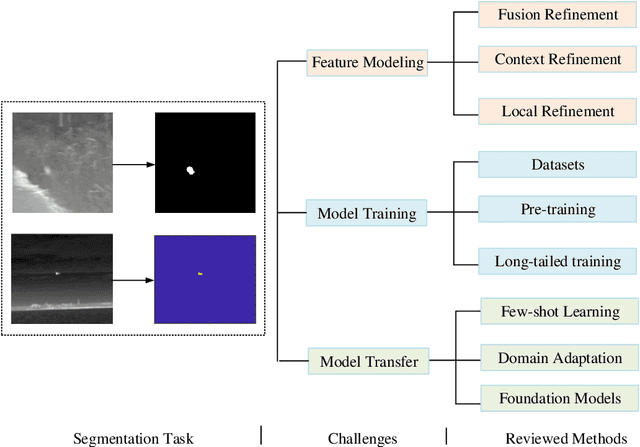

Infrared sensing is a core method for supporting unmanned systems, such as autonomous vehicles and drones. Recently, infrared sensors have been widely deployed on mobile and stationary platforms for detection and classification of objects from long distances and in wide field of views. Given its success in the vision image analysis domain, deep learning has also been applied for object recognition in infrared images. However, techniques that have proven successful in visible light perception face new challenges in the infrared domain. These challenges include extremely low signal-to-noise ratios in infrared images, very small and blurred objects of interest, and limited availability of labeled/unlabeled training data due to the specialized nature of infrared sensors. Numerous methods have been proposed in the literature for the detection and classification of small objects in infrared images achieving varied levels of success. There is a need for a survey paper that critically analyzes existing techniques in this domain, identifies unsolved challenges and provides future research directions. This paper fills the gap and offers a concise and insightful review of deep learning-based methods. It also identifies the challenges faced by existing infrared object segmentation methods and provides a structured review of existing infrared perception methods from the perspective of these challenges and highlights the motivations behind the various approaches. Finally, this review suggests promising future directions based on recent advancements within this domain.
OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition
Nov 30, 2023Due to the resource-intensive nature of training vision-language models on expansive video data, a majority of studies have centered on adapting pre-trained image-language models to the video domain. Dominant pipelines propose to tackle the visual discrepancies with additional temporal learners while overlooking the substantial discrepancy for web-scaled descriptive narratives and concise action category names, leading to less distinct semantic space and potential performance limitations. In this work, we prioritize the refinement of text knowledge to facilitate generalizable video recognition. To address the limitations of the less distinct semantic space of category names, we prompt a large language model (LLM) to augment action class names into Spatio-Temporal Descriptors thus bridging the textual discrepancy and serving as a knowledge base for general recognition. Moreover, to assign the best descriptors with different video instances, we propose Optimal Descriptor Solver, forming the video recognition problem as solving the optimal matching flow across frame-level representations and descriptors. Comprehensive evaluations in zero-shot, few-shot, and fully supervised video recognition highlight the effectiveness of our approach. Our best model achieves a state-of-the-art zero-shot accuracy of 75.1% on Kinetics-600.
First Place Solution to the CVPR'2023 AQTC Challenge: A Function-Interaction Centric Approach with Spatiotemporal Visual-Language Alignment
Jun 23, 2023



Affordance-Centric Question-driven Task Completion (AQTC) has been proposed to acquire knowledge from videos to furnish users with comprehensive and systematic instructions. However, existing methods have hitherto neglected the necessity of aligning spatiotemporal visual and linguistic signals, as well as the crucial interactional information between humans and objects. To tackle these limitations, we propose to combine large-scale pre-trained vision-language and video-language models, which serve to contribute stable and reliable multimodal data and facilitate effective spatiotemporal visual-textual alignment. Additionally, a novel hand-object-interaction (HOI) aggregation module is proposed which aids in capturing human-object interaction information, thereby further augmenting the capacity to understand the presented scenario. Our method achieved first place in the CVPR'2023 AQTC Challenge, with a Recall@1 score of 78.7\%. The code is available at https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC.
Full Point Encoding for Local Feature Aggregation in 3D Point Clouds
Mar 08, 2023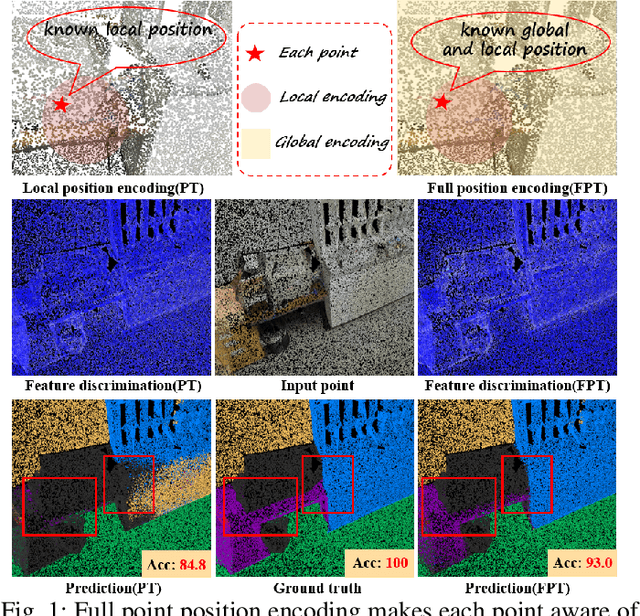
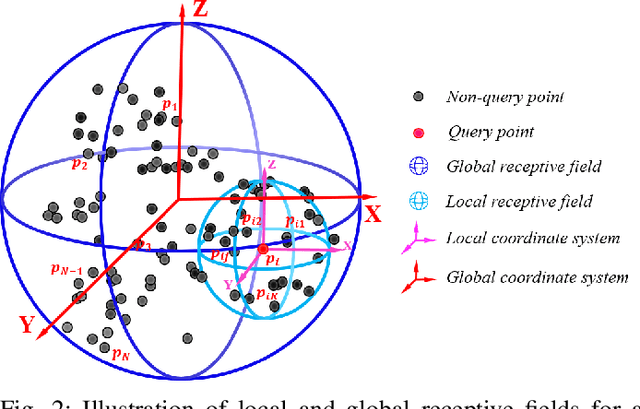
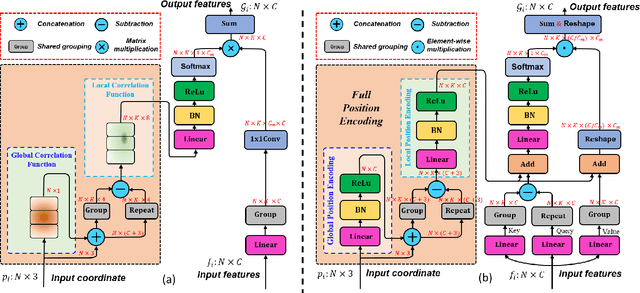
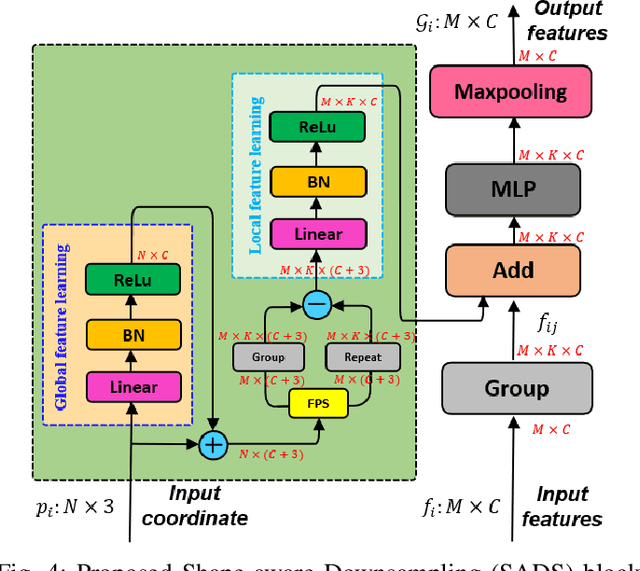
Point cloud processing methods exploit local point features and global context through aggregation which does not explicity model the internal correlations between local and global features. To address this problem, we propose full point encoding which is applicable to convolution and transformer architectures. Specifically, we propose Full Point Convolution (FPConv) and Full Point Transformer (FPTransformer) architectures. The key idea is to adaptively learn the weights from local and global geometric connections, where the connections are established through local and global correlation functions respectively. FPConv and FPTransformer simultaneously model the local and global geometric relationships as well as their internal correlations, demonstrating strong generalization ability and high performance. FPConv is incorporated in classical hierarchical network architectures to achieve local and global shape-aware learning. In FPTransformer, we introduce full point position encoding in self-attention, that hierarchically encodes each point position in the global and local receptive field. We also propose a shape aware downsampling block which takes into account the local shape and the global context. Experimental comparison to existing methods on benchmark datasets show the efficacy of FPConv and FPTransformer for semantic segmentation, object detection, classification, and normal estimation tasks. In particular, we achieve state-of-the-art semantic segmentation results of 76% mIoU on S3DIS 6-fold and 72.2% on S3DIS Area5.
DANet: Density Adaptive Convolutional Network with Interactive Attention for 3D Point Clouds
Mar 08, 2023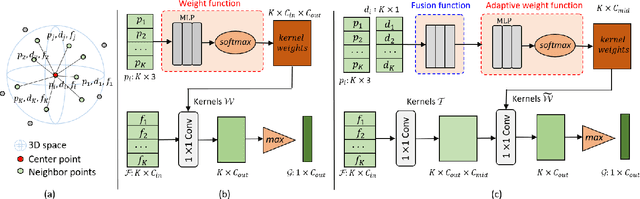
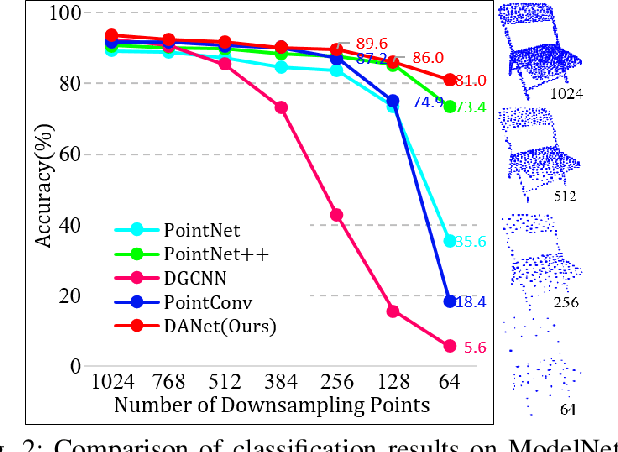
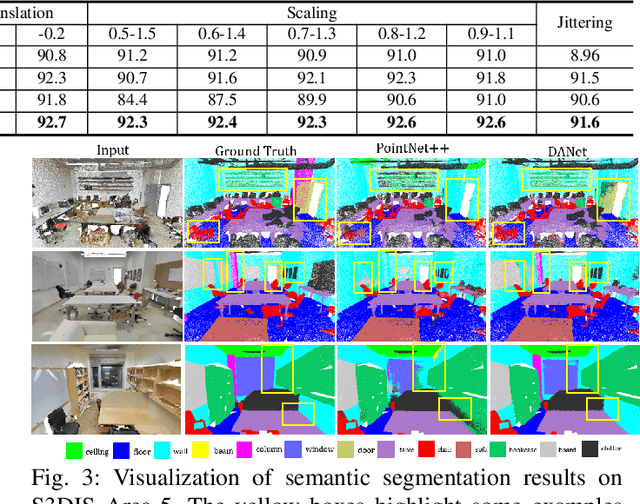
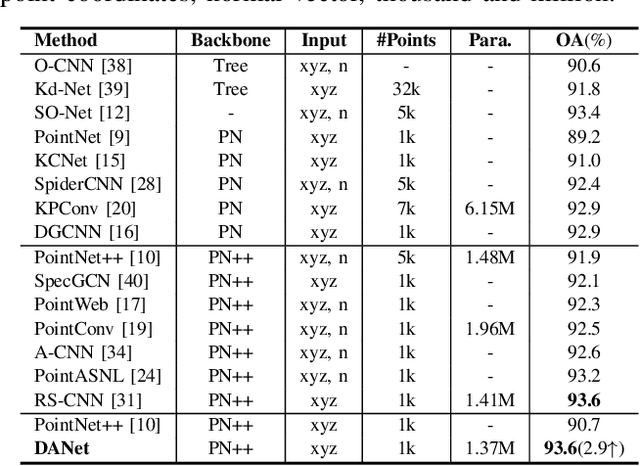
Local features and contextual dependencies are crucial for 3D point cloud analysis. Many works have been devoted to designing better local convolutional kernels that exploit the contextual dependencies. However, current point convolutions lack robustness to varying point cloud density. Moreover, contextual modeling is dominated by non-local or self-attention models which are computationally expensive. To solve these problems, we propose density adaptive convolution, coined DAConv. The key idea is to adaptively learn the convolutional weights from geometric connections obtained from the point density and position. To extract precise context dependencies with fewer computations, we propose an interactive attention module (IAM) that embeds spatial information into channel attention along different spatial directions. DAConv and IAM are integrated in a hierarchical network architecture to achieve local density and contextual direction-aware learning for point cloud analysis. Experiments show that DAConv is significantly more robust to point density compared to existing methods and extensive comparisons on challenging 3D point cloud datasets show that our network achieves state-of-the-art classification results of 93.6% on ModelNet40, competitive semantic segmentation results of 68.71% mIoU on S3DIS and part segmentation results of 86.7% mIoU on ShapeNet.
Domain-invariant Prototypes for Semantic Segmentation
Aug 12, 2022
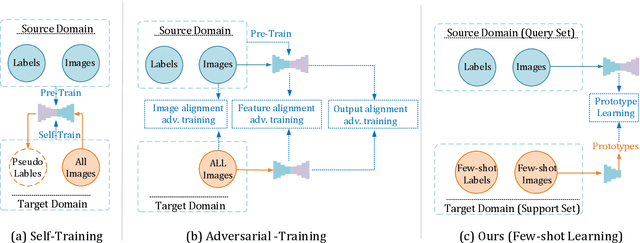
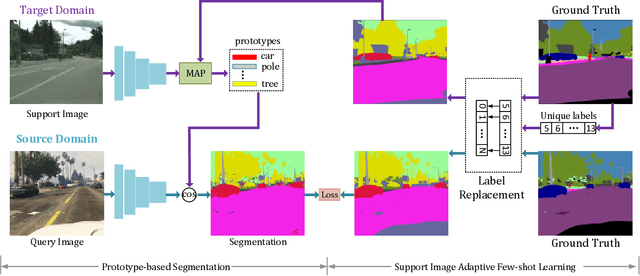
Deep Learning has greatly advanced the performance of semantic segmentation, however, its success relies on the availability of large amounts of annotated data for training. Hence, many efforts have been devoted to domain adaptive semantic segmentation that focuses on transferring semantic knowledge from a labeled source domain to an unlabeled target domain. Existing self-training methods typically require multiple rounds of training, while another popular framework based on adversarial training is known to be sensitive to hyper-parameters. In this paper, we present an easy-to-train framework that learns domain-invariant prototypes for domain adaptive semantic segmentation. In particular, we show that domain adaptation shares a common character with few-shot learning in that both aim to recognize some types of unseen data with knowledge learned from large amounts of seen data. Thus, we propose a unified framework for domain adaptation and few-shot learning. The core idea is to use the class prototypes extracted from few-shot annotated target images to classify pixels of both source images and target images. Our method involves only one-stage training and does not need to be trained on large-scale un-annotated target images. Moreover, our method can be extended to variants of both domain adaptation and few-shot learning. Experiments on adapting GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes show that our method achieves competitive performance to state-of-the-art.
Deep Learning based 3D Segmentation: A Survey
Mar 10, 2021


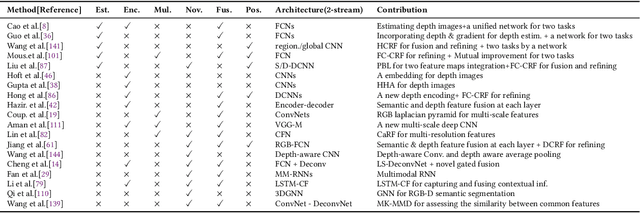
3D object segmentation is a fundamental and challenging problem in computer vision with applications in autonomous driving, robotics, augmented reality and medical image analysis. It has received significant attention from the computer vision, graphics and machine learning communities. Traditionally, 3D segmentation was performed with hand-crafted features and engineered methods which failed to achieve acceptable accuracy and could not generalize to large-scale data. Driven by their great success in 2D computer vision, deep learning techniques have recently become the tool of choice for 3D segmentation tasks as well. This has led to an influx of a large number of methods in the literature that have been evaluated on different benchmark datasets. This paper provides a comprehensive survey of recent progress in deep learning based 3D segmentation covering over 150 papers. It summarizes the most commonly used pipelines, discusses their highlights and shortcomings, and analyzes the competitive results of these segmentation methods. Based on the analysis, it also provides promising research directions for the future.
Self-supervised Learning with Fully Convolutional Networks
Dec 18, 2020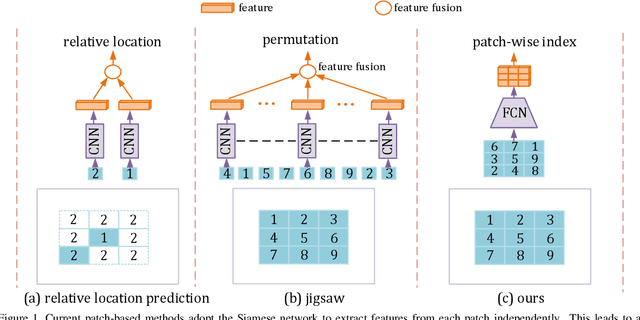
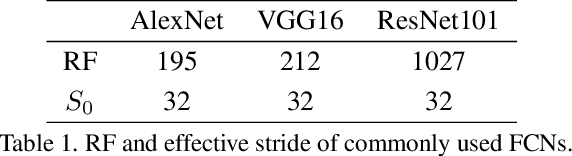
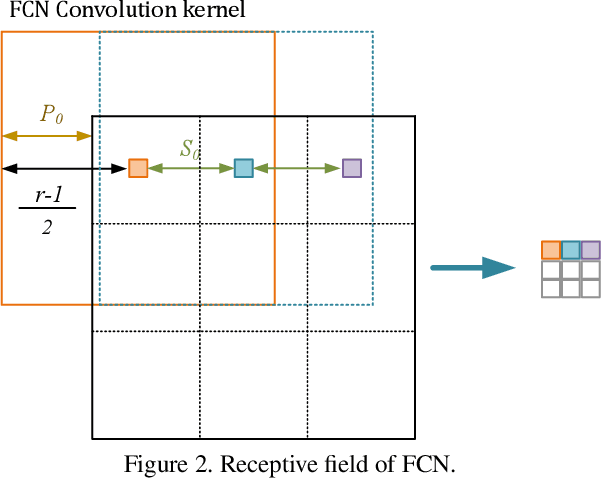

Although deep learning based methods have achieved great success in many computer vision tasks, their performance relies on a large number of densely annotated samples that are typically difficult to obtain. In this paper, we focus on the problem of learning representation from unlabeled data for semantic segmentation. Inspired by two patch-based methods, we develop a novel self-supervised learning framework by formulating the Jigsaw Puzzle problem as a patch-wise classification process and solving it with a fully convolutional network. By learning to solve a Jigsaw Puzzle problem with 25 patches and transferring the learned features to semantic segmentation task on Cityscapes dataset, we achieve a 5.8 percentage point improvement over the baseline model that initialized from random values. Moreover, experiments show that our self-supervised learning method can be applied to different datasets and models. In particular, we achieved competitive performance with the state-of-the-art methods on the PASCAL VOC2012 dataset using significant fewer training images.
FastORB-SLAM: a Fast ORB-SLAM Method with Coarse-to-Fine Descriptor Independent Keypoint Matching
Aug 22, 2020
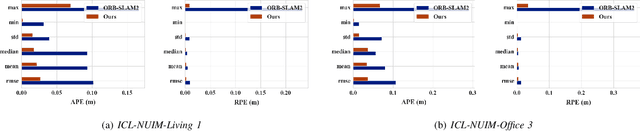
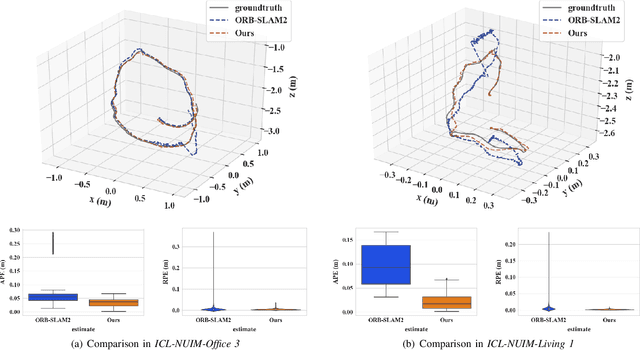

Indirect methods for visual SLAM are gaining popularity due to their robustness to varying environments. ORB-SLAM2 is a benchmark method in this domain, however, the computation of descriptors in ORB-SLAM2 is time-consuming and the descriptors cannot be reused unless a frame is selected as a keyframe. To overcome these problems, we present FastORB-SLAM which is light-weight and efficient as it tracks keypoints between adjacent frames without computing descriptors. To achieve this, a two-stage coarse-to-fine descriptor independent keypoint matching method is proposed based on sparse optical flow. In the first stage, we first predict initial keypoint correspondences via a uniform acceleration motion model and then robustly establish the correspondences via a pyramid-based sparse optical flow tracking method. In the second stage, we leverage motion smoothness and the epipolar constraint to refine the correspondences. In particular, our method computes descriptors only for keyframes. We test FastORB-SLAM with an RGBD camera on \textit{TUM} and \textit{ICL-NUIM} datasets and compare its accuracy and efficiency to nine existing RGBD SLAM methods. Qualitative and quantitative results show that our method achieves state-of-the-art performance in accuracy and is about twice as fast as the ORB-SLAM2
Real time backbone for semantic segmentation
Mar 16, 2019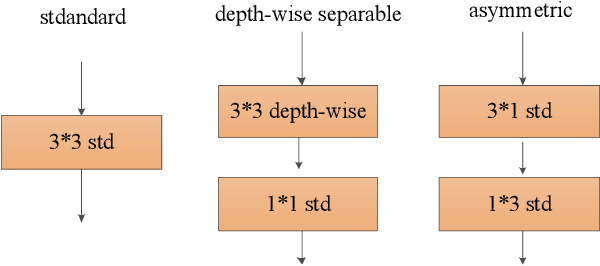
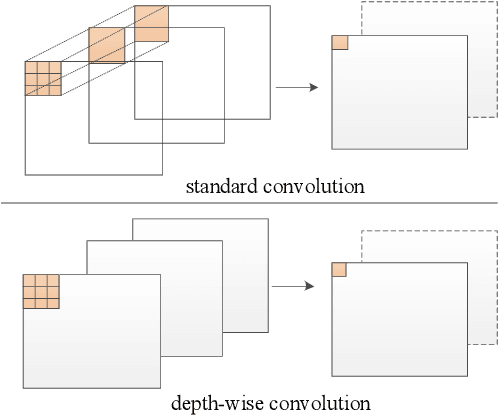

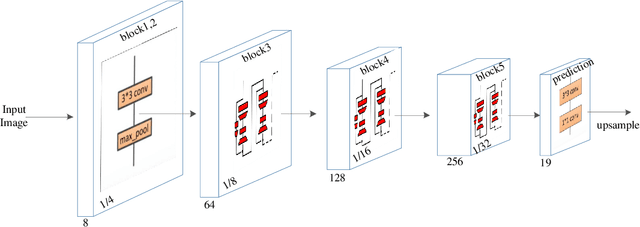
The rapid development of autonomous driving in recent years presents lots of challenges for scene understanding. As an essential step towards scene understanding, semantic segmentation thus received lots of attention in past few years. Although deep learning based state-of-the-arts have achieved great success in improving the segmentation accuracy, most of them suffer from an inefficiency problem and can hardly applied to practical applications. In this paper, we systematically analyze the computation cost of Convolutional Neural Network(CNN) and found that the inefficiency of CNN is mainly caused by its wide structure rather than the deep structure. In addition, the success of pruning based model compression methods proved that there are many redundant channels in CNN. Thus, we designed a very narrow while deep backbone network to improve the efficiency of semantic segmentation. By casting our network to FCN32 segmentation architecture, the basic structure of most segmentation methods, we achieved 60.6\% mIoU on Cityscape val dataset with 54 frame per seconds(FPS) on $1024\times2048$ inputs, which already outperforms one of the earliest real time deep learning based segmentation methods: ENet.