 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanisms of Generative Image-to-Image Translation Networks
Nov 15, 2024Generative Adversarial Networks (GANs) are a class of neural networks that have been widely used in the field of image-to-image translation. In this paper, we propose a streamlined image-to-image translation network with a simpler architecture compared to existing models. We investigate the relationship between GANs and autoencoders and provide an explanation for the efficacy of employing only the GAN component for tasks involving image translation. We show that adversarial for GAN models yields results comparable to those of existing methods without additional complex loss penalties. Subsequently, we elucidate the rationale behind this phenomenon. We also incorporate experimental results to demonstrate the validity of our findings.
Two-Stage Hierarchical and Explainable Feature Selection Framework for Dimensionality Reduction in Sleep Staging
Aug 31, 2024


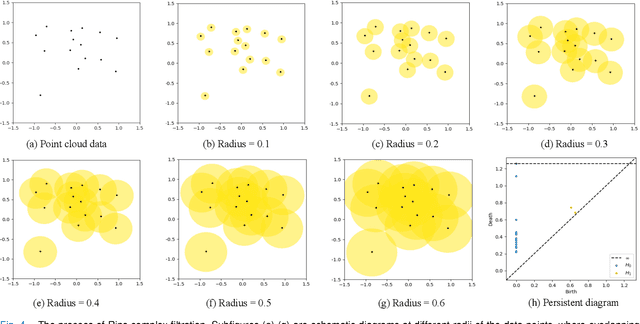
Sleep is crucial for human health, and EEG signals play a significant role in sleep research. Due to the high-dimensional nature of EEG signal data sequences, data visualization and clustering of different sleep stages have been challenges. To address these issues, we propose a two-stage hierarchical and explainable feature selection framework by incorporating a feature selection algorithm to improve the performance of dimensionality reduction. Inspired by topological data analysis, which can analyze the structure of high-dimensional data, we extract topological features from the EEG signals to compensate for the structural information loss that happens in traditional spectro-temporal data analysis. Supported by the topological visualization of the data from different sleep stages and the classification results, the proposed features are proven to be effective supplements to traditional features. Finally, we compare the performances of three dimensionality reduction algorithms: Principal Component Analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), and Uniform Manifold Approximation and Projection (UMAP). Among them, t-SNE achieved the highest accuracy of 79.8%, but considering the overall performance in terms of computational resources and metrics, UMAP is the optimal choice.
Shape-Preserving Generation of Food Images for Automatic Dietary Assessment
Aug 23, 2024



Traditional dietary assessment methods heavily rely on self-reporting, which is time-consuming and prone to bias. Recent advancements in Artificial Intelligence (AI) have revealed new possibilities for dietary assessment, particularly through analysis of food images. Recognizing foods and estimating food volumes from images are known as the key procedures for automatic dietary assessment. However, both procedures required large amounts of training images labeled with food names and volumes, which are currently unavailable. Alternatively, recent studies have indicated that training images can be artificially generated using Generative Adversarial Networks (GANs). Nonetheless, convenient generation of large amounts of food images with known volumes remain a challenge with the existing techniques. In this work, we present a simple GAN-based neural network architecture for conditional food image generation. The shapes of the food and container in the generated images closely resemble those in the reference input image. Our experiments demonstrate the realism of the generated images and shape-preserving capabilities of the proposed framework.
A Survey of Heterogeneous Transfer Learning
Oct 15, 2023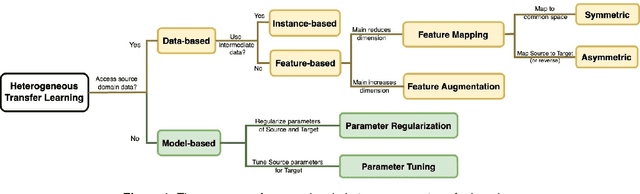

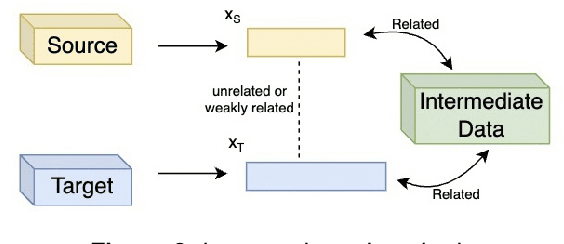

The application of transfer learning, an approach utilizing knowledge from a source domain to enhance model performance in a target domain, has seen a tremendous rise in recent years, underpinning many real-world scenarios. The key to its success lies in the shared common knowledge between the domains, a prerequisite in most transfer learning methodologies. These methods typically presuppose identical feature spaces and label spaces in both domains, known as homogeneous transfer learning, which, however, is not always a practical assumption. Oftentimes, the source and target domains vary in feature spaces, data distributions, and label spaces, making it challenging or costly to secure source domain data with identical feature and label spaces as the target domain. Arbitrary elimination of these differences is not always feasible or optimal. Thus, heterogeneous transfer learning, acknowledging and dealing with such disparities, has emerged as a promising approach for a variety of tasks. Despite the existence of a survey in 2017 on this topic, the fast-paced advances post-2017 necessitate an updated, in-depth review. We therefore present a comprehensive survey of recent developments in heterogeneous transfer learning methods, offering a systematic guide for future research. Our paper reviews methodologies for diverse learning scenarios, discusses the limitations of current studies, and covers various application contexts, including Natural Language Processing, Computer Vision, Multimodality, and Biomedicine, to foster a deeper understanding and spur future research.
Self-supervised Learning with Fully Convolutional Networks
Dec 18, 2020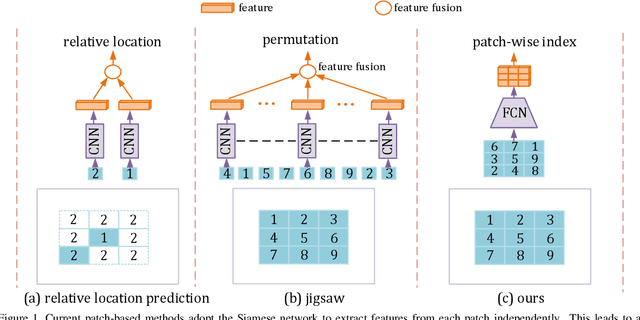
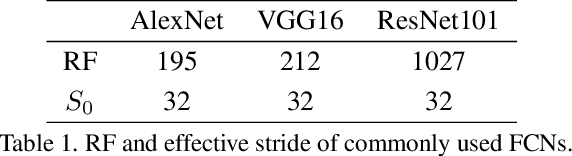
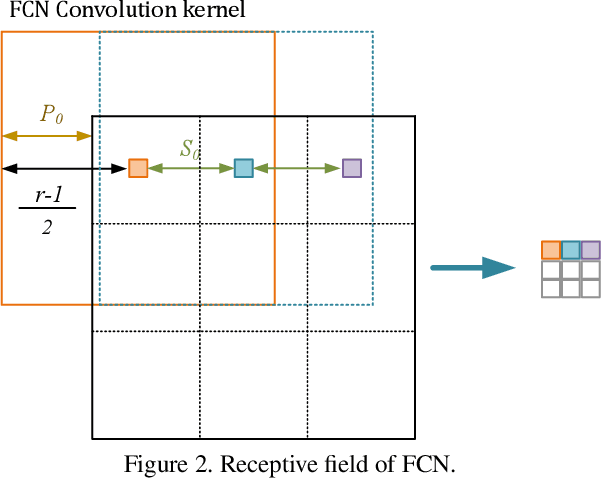

Although deep learning based methods have achieved great success in many computer vision tasks, their performance relies on a large number of densely annotated samples that are typically difficult to obtain. In this paper, we focus on the problem of learning representation from unlabeled data for semantic segmentation. Inspired by two patch-based methods, we develop a novel self-supervised learning framework by formulating the Jigsaw Puzzle problem as a patch-wise classification process and solving it with a fully convolutional network. By learning to solve a Jigsaw Puzzle problem with 25 patches and transferring the learned features to semantic segmentation task on Cityscapes dataset, we achieve a 5.8 percentage point improvement over the baseline model that initialized from random values. Moreover, experiments show that our self-supervised learning method can be applied to different datasets and models. In particular, we achieved competitive performance with the state-of-the-art methods on the PASCAL VOC2012 dataset using significant fewer training images.
Real time backbone for semantic segmentation
Mar 16, 2019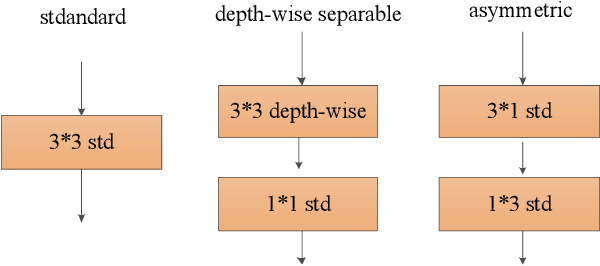
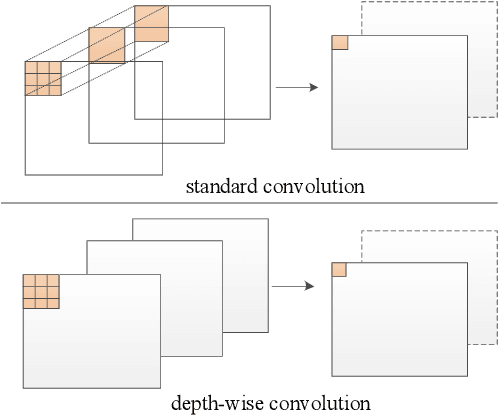

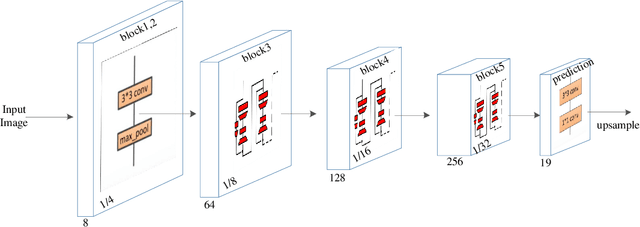
The rapid development of autonomous driving in recent years presents lots of challenges for scene understanding. As an essential step towards scene understanding, semantic segmentation thus received lots of attention in past few years. Although deep learning based state-of-the-arts have achieved great success in improving the segmentation accuracy, most of them suffer from an inefficiency problem and can hardly applied to practical applications. In this paper, we systematically analyze the computation cost of Convolutional Neural Network(CNN) and found that the inefficiency of CNN is mainly caused by its wide structure rather than the deep structure. In addition, the success of pruning based model compression methods proved that there are many redundant channels in CNN. Thus, we designed a very narrow while deep backbone network to improve the efficiency of semantic segmentation. By casting our network to FCN32 segmentation architecture, the basic structure of most segmentation methods, we achieved 60.6\% mIoU on Cityscape val dataset with 54 frame per seconds(FPS) on $1024\times2048$ inputs, which already outperforms one of the earliest real time deep learning based segmentation methods: ENet.