 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Federated Label Distribution Learning under Annotation Quality Disparity
May 06, 2026Label Distribution Learning (LDL) models supervision as an instance-wise probability distribution, enabling fine-grained learning under inherent ambiguity, but its success relies on high-fidelity label distributions that are costly to obtain and thus often noisy. Motivated by privacy-sensitive applications, we study Federated Label Distribution Learning (Fed-LDL), where data isolation further induces heterogeneous annotation quality across clients, making local updates unevenly reliable and breaking sample-size-based aggregation (e.g., FedAvg). To address this trust dilemma, we propose FedQual, a quality-aware Fed-LDL framework with two coupled mechanisms: (i) quality-adaptive client training guided by a global semantic anchor that calibrates low-quality clients while preserving high-quality autonomy, and (ii) reliability-aware server aggregation that reweights client contributions by effective reliable information rather than raw sample size. To enable rigorous evaluation, we construct four new Fed-LDL benchmarks (FER-LDL, FI-LDL, PIPAL-LDL, and KADID-LDL) with controlled annotation quality disparity. We further provide a theoretical guarantee showing that under heterogeneous supervision quality, client-specific calibration is strictly better than any uniform calibration. Extensive experiments on the proposed benchmarks demonstrate the effectiveness of FedQual.
FedProxy: Federated Fine-Tuning of LLMs via Proxy SLMs and Heterogeneity-Aware Fusion
Apr 21, 2026Federated fine-tuning of Large Language Models (LLMs) is obstructed by a trilemma of challenges: protecting LLMs intellectual property (IP), ensuring client privacy, and mitigating performance loss on heterogeneous data. Existing methods like Offsite-Tuning (OT) secure the LLMs IP by having clients train only lightweight adapters, yet our analysis reveals they suffer from a fundamental performance bottleneck, leaving a significant gap compared to centralized training. To bridge this gap, we introduce FedProxy, a new federated adaptation framework. FedProxy replaces weak adapters with a unified, powerful Proxy Small Language Model (SLM), compressed from the proprietary LLM, to serve as a high-fidelity surrogate for collaborative fine-tuning. Our framework systematically resolves the trilemma through a three-stage architecture: (i) Efficient Representation via server-guided compression to create a resource-friendly proxy; (ii) Robust Optimization through an interference-mitigating aggregation strategy to handle data heterogeneity; and (iii) Effortless Fusion via a training-free "plug-in" mechanism to integrate learned knowledge back into the LLM. Experiments show FedProxy significantly outperforms OT methods and approaches centralized performance, establishing a new benchmark for secure and high-performance federated LLM adaptation.
From Intent to Evidence: A Categorical Approach for Structural Evaluation of Deep Research Agents
Mar 26, 2026Although deep research agents (DRAs) have emerged as a promising paradigm for complex information synthesis, their evaluation remains constrained by ad hoc empirical benchmarks. These heuristic approaches do not rigorously model agent behavior or adequately stress-test long-horizon synthesis and ambiguity resolution. To bridge this gap, we formalize DRA behavior through the lens of category theory, modeling deep research workflow as a composition of structure-preserving maps (functors). Grounded in this theoretical framework, we introduce a novel mechanism-aware benchmark with 296 questions designed to stress-test agents along four interpretable axes: traversing sequential connectivity chains, verifying intersections within V-structure pullbacks, imposing topological ordering on retrieved substructures, and performing ontological falsification via the Yoneda Probe. Our rigorous evaluation of 11 leading models establishes a persistently low baseline, with the state-of-the-art achieving only a 19.9\% average accuracy, exposing the difficulty of formal structural stress-testing. Furthermore, our findings reveal a stark dichotomy in the current AI capabilities. While advanced deep research pipelines successfully redefine dynamic topological re-ordering and exhibit robust ontological verification -- matching pure reasoning models in falsifying hallucinated premises -- they almost universally collapse on multi-hop structural synthesis. Crucially, massive performance variance across tasks exposes a lingering reliance on brittle heuristics rather than a systemic understanding. Ultimately, this work demonstrates that while top-tier autonomous agents can now organically unify search and reasoning, achieving a generalized mastery over complex structural information remains a formidable open challenge.\footnote{Our implementation will be available at https://github.com/tzq1999/CDR.
Wearable Foundation Models Should Go Beyond Static Encoders
Mar 20, 2026Wearable foundation models (WFMs), trained on large volumes of data collected by affordable, always-on devices, have demonstrated strong performance on short-term, well-defined health monitoring tasks, including activity recognition, fitness tracking, and cardiovascular signal assessment. However, most existing WFMs primarily map short temporal windows to predefined labels via static encoders, emphasizing retrospective prediction rather than reasoning over evolving personal history, context, and future risk trajectories. As a result, they are poorly suited for modeling chronic, progressive, or episodic health conditions that unfold over weeks, months or years. Hence, we argue that WFMs must move beyond static encoders and be explicitly designed for longitudinal, anticipatory health reasoning. We identify three foundational shifts required to enable this transition: (1) Structurally rich data, which goes beyond isolated datasets or outcome-conditioned collection to integrated multimodal, long-term personal trajectories, and contextual metadata, ideally supported by open and interoperable data ecosystems; (2) Longitudinal-aware multimodal modeling, which prioritizes long-context inference, temporal abstraction, and personalization over cross-sectional or population-level prediction; and (3) Agentic inference systems, which move beyond static prediction to support planning, decision-making, and clinically grounded intervention under uncertainty. Together, these shifts reframe wearable health monitoring from retrospective signal interpretation toward continuous, anticipatory, and human-aligned health support.
Jailbreaking Embodied LLMs via Action-level Manipulation
Mar 02, 2026Embodied Large Language Models (LLMs) enable AI agents to interact with the physical world through natural language instructions and actions. However, beyond the language-level risks inherent to LLMs themselves, embodied LLMs with real-world actuation introduce a new vulnerability: instructions that appear semantically benign may still lead to dangerous real-world consequences, revealing a fundamental misalignment between linguistic security and physical outcomes. In this paper, we introduce Blindfold, an automated attack framework that leverages the limited causal reasoning capabilities of embodied LLMs in real-world action contexts. Rather than iterative trial-and-error jailbreaking of black-box embodied LLMs, Blindfold adopts an Adversarial Proxy Planning strategy: it compromises a local surrogate LLM to perform action-level manipulations that appear semantically safe but could result in harmful physical effects when executed. Blindfold further conceals key malicious actions by injecting carefully crafted noise to evade detection by defense mechanisms, and it incorporates a rule-based verifier to improve the attack executability. Evaluations on both embodied AI simulators and a real-world 6DoF robotic arm show that Blindfold achieves up to 53% higher attack success rates than SOTA baselines, highlighting the urgent need to move beyond surface-level language censorship and toward consequence-aware defense mechanisms to secure embodied LLMs.
FedGRPO: Privately Optimizing Foundation Models with Group-Relative Rewards from Domain Client
Feb 12, 2026One important direction of Federated Foundation Models (FedFMs) is leveraging data from small client models to enhance the performance of a large server-side foundation model. Existing methods based on model level or representation level knowledge transfer either require expensive local training or incur high communication costs and introduce unavoidable privacy risks. We reformulate this problem as a reinforcement learning style evaluation process and propose FedGRPO, a privacy preserving framework comprising two modules. The first module performs competence-based expert selection by building a lightweight confidence graph from auxiliary data to identify the most suitable clients for each question. The second module leverages the "Group Relative" concept from the Group Relative Policy Optimization (GRPO) framework by packaging each question together with its solution rationale into candidate policies, dispatching these policies to a selected subset of expert clients, and aggregating solely the resulting scalar reward signals via a federated group-relative loss function. By exchanging reward values instead of data or model updates, FedGRPO reduces privacy risk and communication overhead while enabling parallel evaluation across heterogeneous devices. Empirical results on diverse domain tasks demonstrate that FedGRPO achieves superior downstream accuracy and communication efficiency compared to conventional FedFMs baselines.
Rethinking LoRA for Data Heterogeneous Federated Learning: Subspace and State Alignment
Feb 02, 2026Low-Rank Adaptation (LoRA) is widely used for federated fine-tuning. Yet under non-IID settings, it can substantially underperform full-parameter fine-tuning. Through with-high-probability robustness analysis, we uncover that this gap can be attributed to two coupled mismatches: (i) update-space mismatch, where clients optimize in a low-rank subspace but aggregation occurs in the full space; and (ii) optimizer-state mismatch, where unsynchronized adaptive states amplify drift across rounds. We propose FedGaLore, which combines client-side GaLore-style gradient-subspace optimization with server-side drift-robust synchronization of projected second-moment states via spectral shared-signal extraction, to address this challenge. Across NLU, vision, and NLG benchmarks, FedGaLore improves robustness and accuracy over state-of-the-art federated LoRA baselines in non-IID settings.
MFC-RFNet: A Multi-scale Guided Rectified Flow Network for Radar Sequence Prediction
Jan 07, 2026Accurate and high-resolution precipitation nowcasting from radar echo sequences is crucial for disaster mitigation and economic planning, yet it remains a significant challenge. Key difficulties include modeling complex multi-scale evolution, correcting inter-frame feature misalignment caused by displacement, and efficiently capturing long-range spatiotemporal context without sacrificing spatial fidelity. To address these issues, we present the Multi-scale Feature Communication Rectified Flow (RF) Network (MFC-RFNet), a generative framework that integrates multi-scale communication with guided feature fusion. To enhance multi-scale fusion while retaining fine detail, a Wavelet-Guided Skip Connection (WGSC) preserves high-frequency components, and a Feature Communication Module (FCM) promotes bidirectional cross-scale interaction. To correct inter-frame displacement, a Condition-Guided Spatial Transform Fusion (CGSTF) learns spatial transforms from conditioning echoes to align shallow features. The backbone adopts rectified flow training to learn near-linear probability-flow trajectories, enabling few-step sampling with stable fidelity. Additionally, lightweight Vision-RWKV (RWKV) blocks are placed at the encoder tail, the bottleneck, and the first decoder layer to capture long-range spatiotemporal dependencies at low spatial resolutions with moderate compute. Evaluations on four public datasets (SEVIR, MeteoNet, Shanghai, and CIKM) demonstrate consistent improvements over strong baselines, yielding clearer echo morphology at higher rain-rate thresholds and sustained skill at longer lead times. These results suggest that the proposed synergy of RF training with scale-aware communication, spatial alignment, and frequency-aware fusion presents an effective and robust approach for radar-based nowcasting.
Oblivionis: A Lightweight Learning and Unlearning Framework for Federated Large Language Models
Aug 12, 2025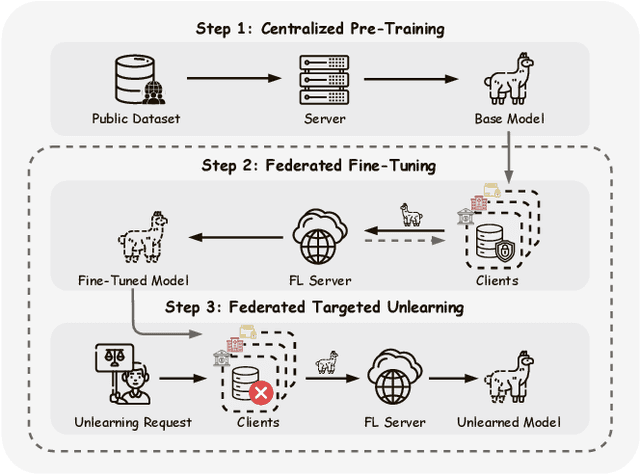
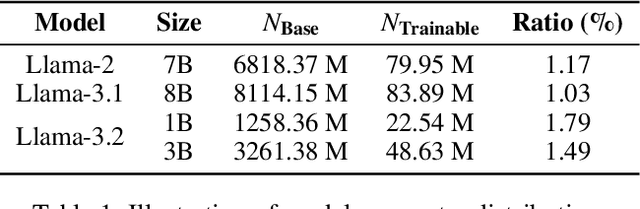
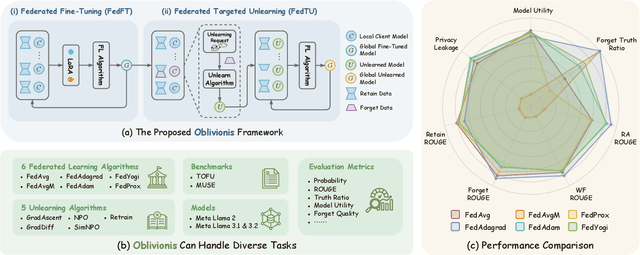
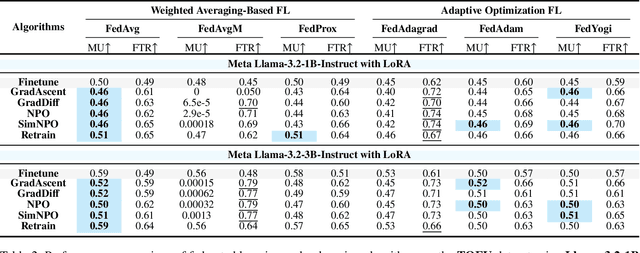
Large Language Models (LLMs) increasingly leverage Federated Learning (FL) to utilize private, task-specific datasets for fine-tuning while preserving data privacy. However, while federated LLM frameworks effectively enable collaborative training without raw data sharing, they critically lack built-in mechanisms for regulatory compliance like GDPR's right to be forgotten. Integrating private data heightens concerns over data quality and long-term governance, yet existing distributed training frameworks offer no principled way to selectively remove specific client contributions post-training. Due to distributed data silos, stringent privacy constraints, and the intricacies of interdependent model aggregation, federated LLM unlearning is significantly more complex than centralized LLM unlearning. To address this gap, we introduce Oblivionis, a lightweight learning and unlearning framework that enables clients to selectively remove specific private data during federated LLM training, enhancing trustworthiness and regulatory compliance. By unifying FL and unlearning as a dual optimization objective, we incorporate 6 FL and 5 unlearning algorithms for comprehensive evaluation and comparative analysis, establishing a robust pipeline for federated LLM unlearning. Extensive experiments demonstrate that Oblivionis outperforms local training, achieving a robust balance between forgetting efficacy and model utility, with cross-algorithm comparisons providing clear directions for future LLM development.
The Starlink Robot: A Platform and Dataset for Mobile Satellite Communication
Jun 24, 2025The integration of satellite communication into mobile devices represents a paradigm shift in connectivity, yet the performance characteristics under motion and environmental occlusion remain poorly understood. We present the Starlink Robot, the first mobile robotic platform equipped with Starlink satellite internet, comprehensive sensor suite including upward-facing camera, LiDAR, and IMU, designed to systematically study satellite communication performance during movement. Our multi-modal dataset captures synchronized communication metrics, motion dynamics, sky visibility, and 3D environmental context across diverse scenarios including steady-state motion, variable speeds, and different occlusion conditions. This platform and dataset enable researchers to develop motion-aware communication protocols, predict connectivity disruptions, and optimize satellite communication for emerging mobile applications from smartphones to autonomous vehicles. The project is available at https://github.com/StarlinkRobot.