 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobiDiary: Autoregressive Action Captioning with Wearable Devices and Wireless Signals
Jan 13, 2026Human Activity Recognition (HAR) in smart homes is critical for health monitoring and assistive living. While vision-based systems are common, they face privacy concerns and environmental limitations (e.g., occlusion). In this work, we present MobiDiary, a framework that generates natural language descriptions of daily activities directly from heterogeneous physical signals (specifically IMU and Wi-Fi). Unlike conventional approaches that restrict outputs to pre-defined labels, MobiDiary produces expressive, human-readable summaries. To bridge the semantic gap between continuous, noisy physical signals and discrete linguistic descriptions, we propose a unified sensor encoder. Instead of relying on modality-specific engineering, we exploit the shared inductive biases of motion-induced signals--where both inertial and wireless data reflect underlying kinematic dynamics. Specifically, our encoder utilizes a patch-based mechanism to capture local temporal correlations and integrates heterogeneous placement embedding to unify spatial contexts across different sensors. These unified signal tokens are then fed into a Transformer-based decoder, which employs an autoregressive mechanism to generate coherent action descriptions word-by-word. We comprehensively evaluate our approach on multiple public benchmarks (XRF V2, UWash, and WiFiTAD). Experimental results demonstrate that MobiDiary effectively generalizes across modalities, achieving state-of-the-art performance on captioning metrics (e.g., BLEU@4, CIDEr, RMC) and outperforming specialized baselines in continuous action understanding.
FedConv: A Learning-on-Model Paradigm for Heterogeneous Federated Clients
Feb 28, 2025



Federated Learning (FL) facilitates collaborative training of a shared global model without exposing clients' private data. In practical FL systems, clients (e.g., edge servers, smartphones, and wearables) typically have disparate system resources. Conventional FL, however, adopts a one-size-fits-all solution, where a homogeneous large global model is transmitted to and trained on each client, resulting in an overwhelming workload for less capable clients and starvation for other clients. To address this issue, we propose FedConv, a client-friendly FL framework, which minimizes the computation and memory burden on resource-constrained clients by providing heterogeneous customized sub-models. FedConv features a novel learning-on-model paradigm that learns the parameters of the heterogeneous sub-models via convolutional compression. Unlike traditional compression methods, the compressed models in FedConv can be directly trained on clients without decompression. To aggregate the heterogeneous sub-models, we propose transposed convolutional dilation to convert them back to large models with a unified size while retaining personalized information from clients. The compression and dilation processes, transparent to clients, are optimized on the server leveraging a small public dataset. Extensive experiments on six datasets demonstrate that FedConv outperforms state-of-the-art FL systems in terms of model accuracy (by more than 35% on average), computation and communication overhead (with 33% and 25% reduction, respectively).
XRF V2: A Dataset for Action Summarization with Wi-Fi Signals, and IMUs in Phones, Watches, Earbuds, and Glasses
Jan 31, 2025



Human Action Recognition (HAR) plays a crucial role in applications such as health monitoring, smart home automation, and human-computer interaction. While HAR has been extensively studied, action summarization, which involves identifying and summarizing continuous actions, remains an emerging task. This paper introduces the novel XRF V2 dataset, designed for indoor daily activity Temporal Action Localization (TAL) and action summarization. XRF V2 integrates multimodal data from Wi-Fi signals, IMU sensors (smartphones, smartwatches, headphones, and smart glasses), and synchronized video recordings, offering a diverse collection of indoor activities from 16 volunteers across three distinct environments. To tackle TAL and action summarization, we propose the XRFMamba neural network, which excels at capturing long-term dependencies in untrimmed sensory sequences and outperforms state-of-the-art methods, such as ActionFormer and WiFiTAD. We envision XRF V2 as a valuable resource for advancing research in human action localization, action forecasting, pose estimation, multimodal foundation models pre-training, synthetic data generation, and more.
EgoHand: Ego-centric Hand Pose Estimation and Gesture Recognition with Head-mounted Millimeter-wave Radar and IMUs
Jan 23, 2025



Recent advanced Virtual Reality (VR) headsets, such as the Apple Vision Pro, employ bottom-facing cameras to detect hand gestures and inputs, which offers users significant convenience in VR interactions. However, these bottom-facing cameras can sometimes be inconvenient and pose a risk of unintentionally exposing sensitive information, such as private body parts or personal surroundings. To mitigate these issues, we introduce EgoHand. This system provides an alternative solution by integrating millimeter-wave radar and IMUs for hand gesture recognition, thereby offering users an additional option for gesture interaction that enhances privacy protection. To accurately recognize hand gestures, we devise a two-stage skeleton-based gesture recognition scheme. In the first stage, a novel end-to-end Transformer architecture is employed to estimate the coordinates of hand joints. Subsequently, these estimated joint coordinates are utilized for gesture recognition. Extensive experiments involving 10 subjects show that EgoHand can detect hand gestures with 90.8% accuracy. Furthermore, EgoHand demonstrates robust performance across a variety of cross-domain tests, including different users, dominant hands, body postures, and scenes.
CCS: Continuous Learning for Customized Incremental Wireless Sensing Services
Dec 06, 2024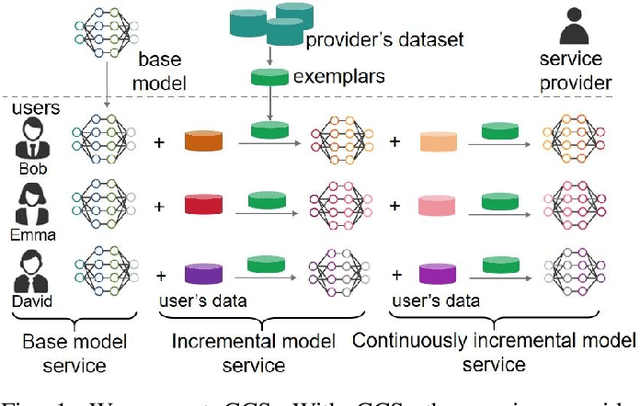
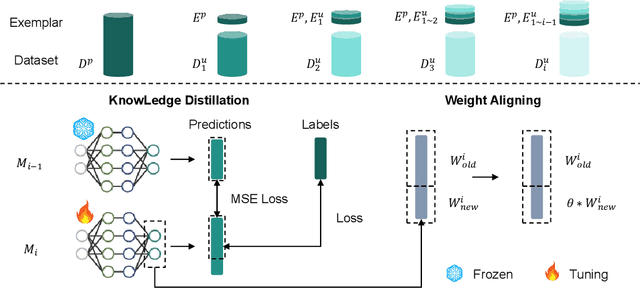
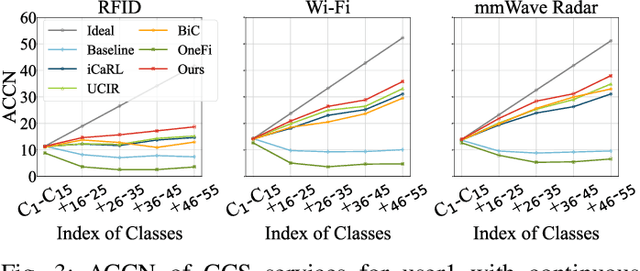
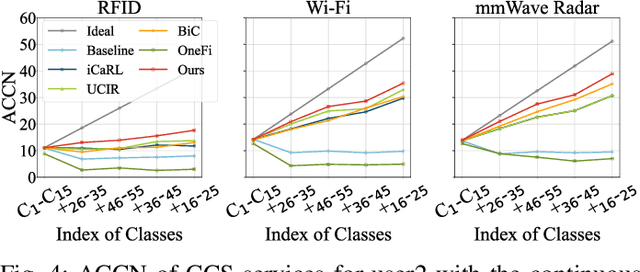
Wireless sensing has made significant progress in tasks ranging from action recognition, vital sign estimation, pose estimation, etc. After over a decade of work, wireless sensing currently stands at the tipping point transitioning from proof-of-concept systems to the large-scale deployment. We envision a future service scenario where wireless sensing service providers distribute sensing models to users. During usage, users might request new sensing capabilities. For example, if someone is away from home on a business trip or vacation for an extended period, they may want a new sensing capability that can detect falls in elderly parents or grandparents and promptly alert them. In this paper, we propose CCS (continuous customized service), enabling model updates on users' local computing resources without data transmission to the service providers. To address the issue of catastrophic forgetting in model updates where updating model parameters to implement new capabilities leads to the loss of existing capabilities we design knowledge distillation and weight alignment modules. These modules enable the sensing model to acquire new capabilities while retaining the existing ones. We conducted extensive experiments on the large-scale XRF55 dataset across Wi-Fi, millimeter-wave radar, and RFID modalities to simulate scenarios where four users sequentially introduced new customized demands. The results affirm that CCS excels in continuous model services across all the above wireless modalities, significantly outperforming existing approaches like OneFi.
Adversary Helps: Gradient-based Device-Free Domain-Independent Gesture Recognition
Apr 08, 2020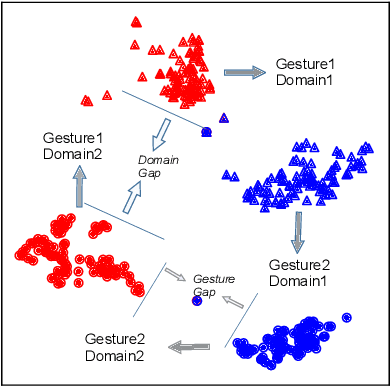
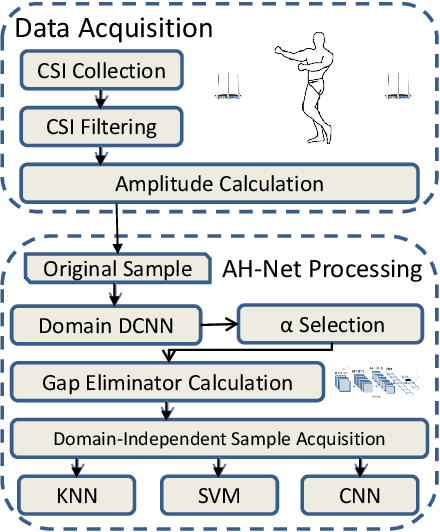

Wireless signal-based gesture recognition has promoted the developments of VR game, smart home, etc. However, traditional approaches suffer from the influence of the domain gap. Low recognition accuracy occurs when the recognition model is trained in one domain but is used in another domain. Though some solutions, such as adversarial learning, transfer learning and body-coordinate velocity profile, have been proposed to achieve cross-domain recognition, these solutions more or less have flaws. In this paper, we define the concept of domain gap and then propose a more promising solution, namely DI, to eliminate domain gap and further achieve domain-independent gesture recognition. DI leverages the sign map of the gradient map as the domain gap eliminator to improve the recognition accuracy. We conduct experiments with ten domains and ten gestures. The experiment results show that DI can achieve the recognition accuracies of 87.13%, 90.12% and 94.45% on KNN, SVM and CNN, which outperforms existing solutions.
Temporal Unet: Sample Level Human Action Recognition using WiFi
Apr 19, 2019


Human doing actions will result in WiFi distortion, which is widely explored for action recognition, such as the elderly fallen detection, hand sign language recognition, and keystroke estimation. As our best survey, past work recognizes human action by categorizing one complete distortion series into one action, which we term as series-level action recognition. In this paper, we introduce a much more fine-grained and challenging action recognition task into WiFi sensing domain, i.e., sample-level action recognition. In this task, every WiFi distortion sample in the whole series should be categorized into one action, which is a critical technique in precise action localization, continuous action segmentation, and real-time action recognition. To achieve WiFi-based sample-level action recognition, we fully analyze approaches in image-based semantic segmentation as well as in video-based frame-level action recognition, then propose a simple yet efficient deep convolutional neural network, i.e., Temporal Unet. Experimental results show that Temporal Unet achieves this novel task well. Codes have been made publicly available at https://github.com/geekfeiw/WiSLAR.
Can WiFi Estimate Person Pose?
Apr 02, 2019
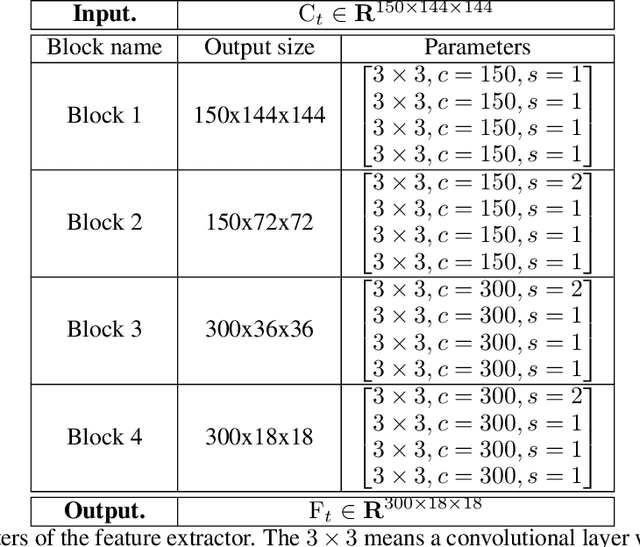
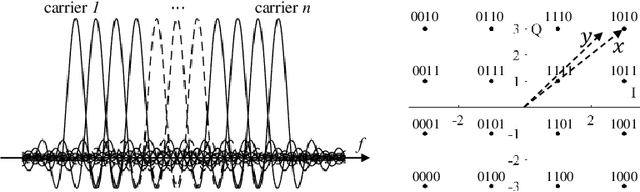

WiFi human sensing has achieved great progress in indoor localization, activity classification, etc. Retracing the development of these work, we have a natural question: can WiFi devices work like cameras for vision applications? In this paper We try to answer this question by exploring the ability of WiFi on estimating single person pose. We use a 3-antenna WiFi sender and a 3-antenna receiver to generate WiFi data. Meanwhile, we use a synchronized camera to capture person videos for corresponding keypoint annotations. We further propose a fully convolutional network (FCN), termed WiSPPN, to estimate single person pose from the collected data and annotations. Evaluation on over 80k images (16 sites and 8 persons) replies aforesaid question with a positive answer. Codes have been made publicly available at https://github.com/geekfeiw/WiSPPN.
Person-in-WiFi: Fine-grained Person Perception using WiFi
Mar 30, 2019

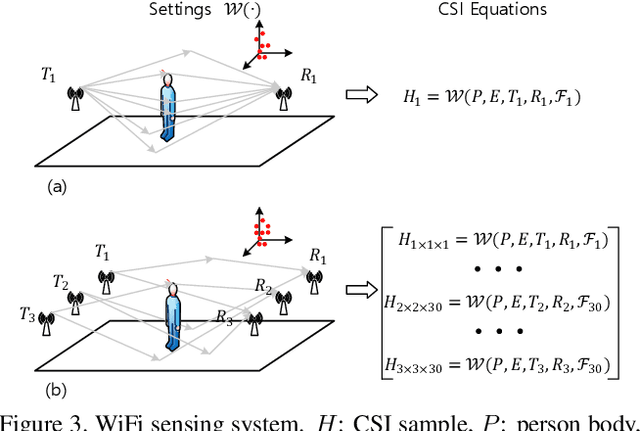

Fine-grained person perception such as body segmentation and pose estimation has been achieved with many 2D and 3D sensors such as RGB/depth cameras, radars (e.g., RF-Pose) and LiDARs. These sensors capture 2D pixels or 3D point clouds of person bodies with high spatial resolution, such that the existing Convolutional Neural Networks can be directly applied for perception. In this paper, we take one step forward to show that fine-grained person perception is possible even with 1D sensors: WiFi antennas. To our knowledge, this is the first work to perceive persons with pervasive WiFi devices, which is cheaper and power efficient than radars and LiDARs, invariant to illumination, and has little privacy concern comparing to cameras. We used two sets of off-the-shelf WiFi antennas to acquire signals, i.e., one transmitter set and one receiver set. Each set contains three antennas lined-up as a regular household WiFi router. The WiFi signal generated by a transmitter antenna, penetrates through and reflects on human bodies, furniture and walls, and then superposes at a receiver antenna as a 1D signal sample (instead of 2D pixels or 3D point clouds). We developed a deep learning approach that uses annotations on 2D images, takes the received 1D WiFi signals as inputs, and performs body segmentation and pose estimation in an end-to-end manner. Experimental results on over 100000 frames under 16 indoor scenes demonstrate that Person-in-WiFi achieved person perception comparable to approaches using 2D images.
Continuous User Authentication by Contactless Wireless Sensing
Dec 04, 2018

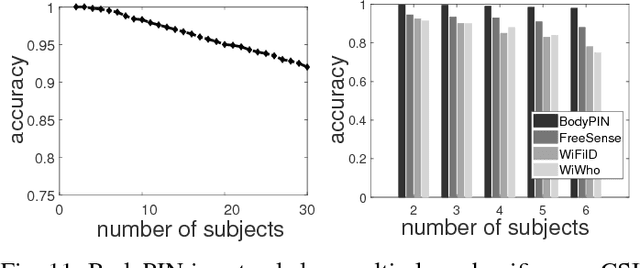
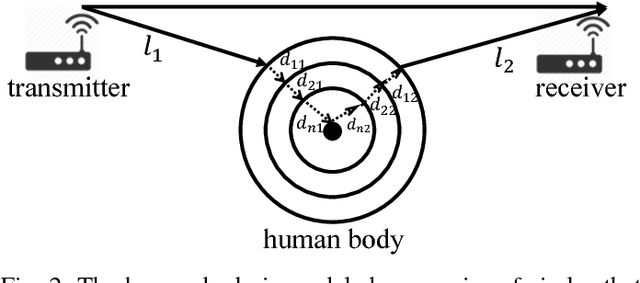
This paper presents BodyPIN, which is a continuous user authentication system by contactless wireless sensing using commodity Wi-Fi. BodyPIN can track the current user's legal identity throughout a computer system's execution. In case the authentication fails, the consequent accesses will be denied to protect the system. The recent rich wireless-based user identification designs cannot be applied to BodyPIN directly, because they identify a user's various activities, rather than the user herself. The enforced to be performed activities can thus interrupt the user's operations on the system, highly inconvenient and not user-friendly. In this paper, we leverage the bio-electromagnetics domain human model for quantifying the impact of human body on the bypassing Wi-Fi signals and deriving the component that indicates a user's identity. Then we extract suitable Wi-Fi signal features to fully represent such an identity component, based on which we fulfill the continuous user authentication design. We implement a BodyPIN prototype by commodity Wi-Fi NICs without any extra or dedicated wireless hardware. We show that BodyPIN achieves promising authentication performances, which is also lightweight and robust under various practical settings.