 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity and Location-Robust Respiratory Waveform Monitoring with Single-Antenna WiFi
Apr 22, 2026In recent years, WiFi sensing has been recognized as a promising technology to bring respiratory monitoring into everyday homes, thanks to its contactless nature and ubiquitous availability. However, existing WiFi-based respiratory monitoring systems still fall short of deployment-oriented performance: they suffer from restrained hardware scalability, limited accuracy, and are highly sensitive to user location. To overcome these limitations and push WiFi sensing towards clinically meaningful precision, we propose RespirFi, a novel system that robustly delivers high-fidelity respiratory waveforms with WiFi Channel State Information (CSI), thereby enabling accurate estimation of key physiological biomarkers. At the core of RespirFi is a theoretical human reflection model, through which we perform an in-depth characterization of how CSI variations are shaped by both subcarrier frequency and spatial user location. Guided by these insights, we develop a location-robust waveform construction method that adaptively selects high quality subcarriers and aligns their waveform trends, ensuring accurate waveform recovery. Furthermore, we propose a breathing phase identification method that leverages inter-subcarrier CSI differences to reliably distinguish inhalation from exhalation. We implement RespirFi over commodity WiFi devices, and extensive experiments demonstrate that it outperforms state-of-the-art approaches across a wide range of clinically relevant respiratory metrics.
A Framework for Deploying Learning-based Quadruped Loco-Manipulation
Dec 22, 2025Quadruped mobile manipulators offer strong potential for agile loco-manipulation but remain difficult to control and transfer reliably from simulation to reality. Reinforcement learning (RL) shows promise for whole-body control, yet most frameworks are proprietary and hard to reproduce on real hardware. We present an open pipeline for training, benchmarking, and deploying RL-based controllers on the Unitree B1 quadruped with a Z1 arm. The framework unifies sim-to-sim and sim-to-real transfer through ROS, re-implementing a policy trained in Isaac Gym, extending it to MuJoCo via a hardware abstraction layer, and deploying the same controller on physical hardware. Sim-to-sim experiments expose discrepancies between Isaac Gym and MuJoCo contact models that influence policy behavior, while real-world teleoperated object-picking trials show that coordinated whole-body control extends reach and improves manipulation over floating-base baselines. The pipeline provides a transparent, reproducible foundation for developing and analyzing RL-based loco-manipulation controllers and will be released open source to support future research.
Meta-SimGNN: Adaptive and Robust WiFi Localization Across Dynamic Configurations and Diverse Scenarios
Nov 18, 2025To promote the practicality of deep learning-based localization, existing studies aim to address the issue of scenario dependence through meta-learning. However, these studies primarily focus on variations in environmental layouts while overlooking the impact of changes in device configurations, such as bandwidth, the number of access points (APs), and the number of antennas used. Unlike environmental changes, variations in device configurations affect the dimensionality of channel state information (CSI), thereby compromising neural network usability. To address this issue, we propose Meta-SimGNN, a novel WiFi localization system that integrates graph neural networks with meta-learning to improve localization generalization and robustness. First, we introduce a fine-grained CSI graph construction scheme, where each AP is treated as a graph node, allowing for adaptability to changes in the number of APs. To structure the features of each node, we propose an amplitude-phase fusion method and a feature extraction method. The former utilizes both amplitude and phase to construct CSI images, enhancing data reliability, while the latter extracts dimension-consistent features to address variations in bandwidth and the number of antennas. Second, a similarity-guided meta-learning strategy is developed to enhance adaptability in diverse scenarios. The initial model parameters for the fine-tuning stage are determined by comparing the similarity between the new scenario and historical scenarios, facilitating rapid adaptation of the model to the new localization scenario. Extensive experimental results over commodity WiFi devices in different scenarios show that Meta-SimGNN outperforms the baseline methods in terms of localization generalization and accuracy.
Unreal Robotics Lab: A High-Fidelity Robotics Simulator with Advanced Physics and Rendering
Apr 19, 2025High-fidelity simulation is essential for robotics research, enabling safe and efficient testing of perception, control, and navigation algorithms. However, achieving both photorealistic rendering and accurate physics modeling remains a challenge. This paper presents a novel simulation framework--the Unreal Robotics Lab (URL) that integrates the Unreal Engine's advanced rendering capabilities with MuJoCo's high-precision physics simulation. Our approach enables realistic robotic perception while maintaining accurate physical interactions, facilitating benchmarking and dataset generation for vision-based robotics applications. The system supports complex environmental effects, such as smoke, fire, and water dynamics, which are critical for evaluating robotic performance under adverse conditions. We benchmark visual navigation and SLAM methods within our framework, demonstrating its utility for testing real-world robustness in controlled yet diverse scenarios. By bridging the gap between physics accuracy and photorealistic rendering, our framework provides a powerful tool for advancing robotics research and sim-to-real transfer.
Exploring Adversarial Obstacle Attacks in Search-based Path Planning for Autonomous Mobile Robots
Apr 08, 2025



Path planning algorithms, such as the search-based A*, are a critical component of autonomous mobile robotics, enabling robots to navigate from a starting point to a destination efficiently and safely. We investigated the resilience of the A* algorithm in the face of potential adversarial interventions known as obstacle attacks. The adversary's goal is to delay the robot's timely arrival at its destination by introducing obstacles along its original path. We developed malicious software to execute the attacks and conducted experiments to assess their impact, both in simulation using TurtleBot in Gazebo and in real-world deployment with the Unitree Go1 robot. In simulation, the attacks resulted in an average delay of 36\%, with the most significant delays occurring in scenarios where the robot was forced to take substantially longer alternative paths. In real-world experiments, the delays were even more pronounced, with all attacks successfully rerouting the robot and causing measurable disruptions. These results highlight that the algorithm's robustness is not solely an attribute of its design but is significantly influenced by the operational environment. For example, in constrained environments like tunnels, the delays were maximized due to the limited availability of alternative routes.
FedConv: A Learning-on-Model Paradigm for Heterogeneous Federated Clients
Feb 28, 2025



Federated Learning (FL) facilitates collaborative training of a shared global model without exposing clients' private data. In practical FL systems, clients (e.g., edge servers, smartphones, and wearables) typically have disparate system resources. Conventional FL, however, adopts a one-size-fits-all solution, where a homogeneous large global model is transmitted to and trained on each client, resulting in an overwhelming workload for less capable clients and starvation for other clients. To address this issue, we propose FedConv, a client-friendly FL framework, which minimizes the computation and memory burden on resource-constrained clients by providing heterogeneous customized sub-models. FedConv features a novel learning-on-model paradigm that learns the parameters of the heterogeneous sub-models via convolutional compression. Unlike traditional compression methods, the compressed models in FedConv can be directly trained on clients without decompression. To aggregate the heterogeneous sub-models, we propose transposed convolutional dilation to convert them back to large models with a unified size while retaining personalized information from clients. The compression and dilation processes, transparent to clients, are optimized on the server leveraging a small public dataset. Extensive experiments on six datasets demonstrate that FedConv outperforms state-of-the-art FL systems in terms of model accuracy (by more than 35% on average), computation and communication overhead (with 33% and 25% reduction, respectively).
DiPPeST: Diffusion-based Path Planner for Synthesizing Trajectories Applied on Quadruped Robots
May 29, 2024



We present DiPPeST, a novel image and goal conditioned diffusion-based trajectory generator for quadrupedal robot path planning. DiPPeST is a zero-shot adaptation of our previously introduced diffusion-based 2D global trajectory generator (DiPPeR). The introduced system incorporates a novel strategy for local real-time path refinements, that is reactive to camera input, without requiring any further training, image processing, or environment interpretation techniques. DiPPeST achieves 92% success rate in obstacle avoidance for nominal environments and an average of 88% success rate when tested in environments that are up to 3.5 times more complex in pixel variation than DiPPeR. A visual-servoing framework is developed to allow for real-world execution, tested on the quadruped robot, achieving 80% success rate in different environments and showcasing improved behavior than complex state-of-the-art local planners, in narrow environments.
DiPPeR: Diffusion-based 2D Path Planner applied on Legged Robots
Oct 11, 2023



In this work, we present DiPPeR, a novel and fast 2D path planning framework for quadrupedal locomotion, leveraging diffusion-driven techniques. Our contributions include a scalable dataset of map images and corresponding end-to-end trajectories, an image-conditioned diffusion planner for mobile robots, and a training/inference pipeline employing CNNs. We validate our approach in several mazes, as well as in real-world deployment scenarios on Boston Dynamic's Spot and Unitree's Go1 robots. DiPPeR performs on average 70 times faster for trajectory generation against both search based and data driven path planning algorithms with an average of 80% consistency in producing feasible paths of various length in maps of variable size, and obstacle structure.
ViT-A*: Legged Robot Path Planning using Vision Transformer A*
Oct 11, 2023



Legged robots, particularly quadrupeds, offer promising navigation capabilities, especially in scenarios requiring traversal over diverse terrains and obstacle avoidance. This paper addresses the challenge of enabling legged robots to navigate complex environments effectively through the integration of data-driven path-planning methods. We propose an approach that utilizes differentiable planners, allowing the learning of end-to-end global plans via a neural network for commanding quadruped robots. The approach leverages 2D maps and obstacle specifications as inputs to generate a global path. To enhance the functionality of the developed neural network-based path planner, we use Vision Transformers (ViT) for map pre-processing, to enable the effective handling of larger maps. Experimental evaluations on two real robotic quadrupeds (Boston Dynamics Spot and Unitree Go1) demonstrate the effectiveness and versatility of the proposed approach in generating reliable path plans.
* 6 pages, 6 figures, conference
MACSA: A Multimodal Aspect-Category Sentiment Analysis Dataset with Multimodal Fine-grained Aligned Annotations
Jun 28, 2022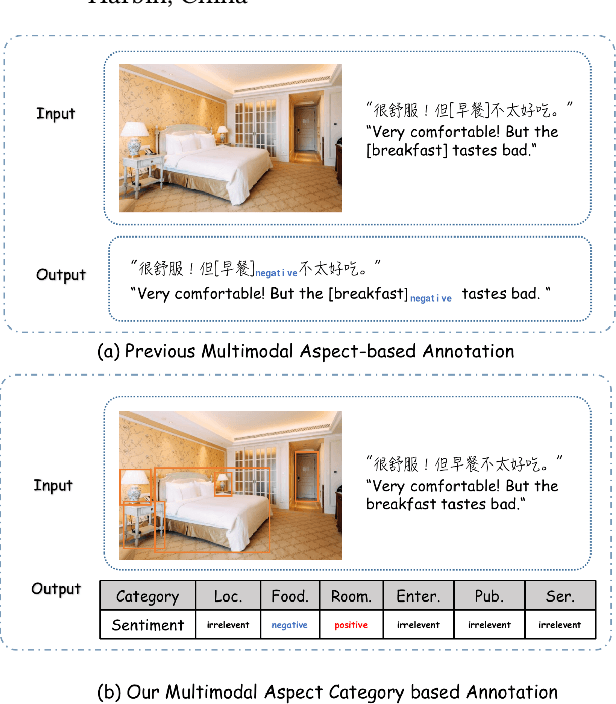
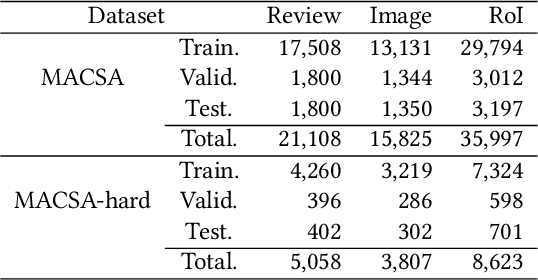
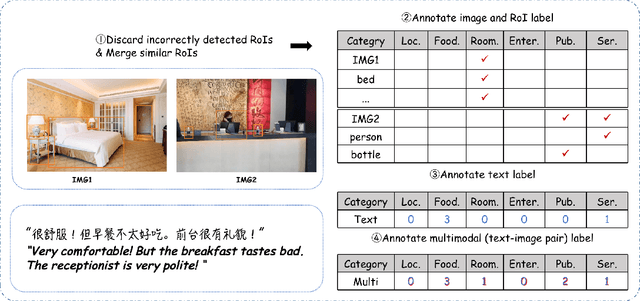
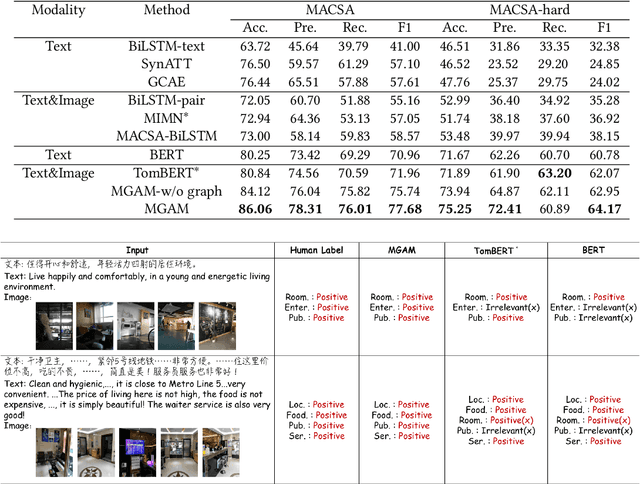
Multimodal fine-grained sentiment analysis has recently attracted increasing attention due to its broad applications. However, the existing multimodal fine-grained sentiment datasets most focus on annotating the fine-grained elements in text but ignore those in images, which leads to the fine-grained elements in visual content not receiving the full attention they deserve. In this paper, we propose a new dataset, the Multimodal Aspect-Category Sentiment Analysis (MACSA) dataset, which contains more than 21K text-image pairs. The dataset provides fine-grained annotations for both textual and visual content and firstly uses the aspect category as the pivot to align the fine-grained elements between the two modalities. Based on our dataset, we propose the Multimodal ACSA task and a multimodal graph-based aligned model (MGAM), which adopts a fine-grained cross-modal fusion method. Experimental results show that our method can facilitate the baseline comparison for future research on this corpus. We will make the dataset and code publicly available.