 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadruped Parkour Learning: Sparsely Gated Mixture of Experts with Visual Input
Apr 21, 2026Robotic parkour provides a compelling benchmark for advancing locomotion over highly challenging terrain, including large discontinuities such as elevated steps. Recent approaches have demonstrated impressive capabilities, including dynamic climbing and jumping, but typically rely on sequential multilayer perceptron (MLP) architectures with densely activated layers. In contrast, sparsely gated mixture-of-experts (MoE) architectures have emerged in the large language model domain as an effective paradigm for improving scalability and performance by activating only a subset of parameters at inference time. In this work, we investigate the application of sparsely gated MoE architectures to vision-based robotic parkour. We compare control policies based on standard MLPs and MoE architectures under a controlled setting where the number of active parameters at inference time is matched. Experimental results on a real Unitree Go2 quadruped robot demonstrate clear performance gains, with the MoE policy achieving double the number of successful trials in traversing large obstacles compared to a standard MLP baseline. We further show that achieving comparable performance with a standard MLP requires scaling its parameter count to match that of the total MoE model, resulting in a 14.3\% increase in computation time. These results highlight that sparsely gated MoE architectures provide a favorable trade-off between performance and computational efficiency, enabling improved scaling of control policies for vision-based robotic parkour. An anonymized link to the codebase is https://osf.io/v2kqj/files/github?view_only=7977dee10c0a44769184498eaba72e44.
SanD-Planner: Sample-Efficient Diffusion Planner in B-Spline Space for Robust Local Navigation
Jan 31, 2026The challenge of generating reliable local plans has long hindered practical applications in highly cluttered and dynamic environments. Key fundamental bottlenecks include acquiring large-scale expert demonstrations across diverse scenes and improving learning efficiency with limited data. This paper proposes SanD-Planner, a sample-efficient diffusion-based local planner that conducts depth image-based imitation learning within the clamped B-spline space. By operating within this compact space, the proposed algorithm inherently yields smooth outputs with bounded prediction errors over local supports, naturally aligning with receding-horizon execution. Integration of an ESDF-based safety checker with explicit clearance and time-to-completion metrics further reduces the training burden associated with value-function learning for feasibility assessment. Experiments show that training with $500$ episodes (merely $0.25\%$ of the demonstration scale used by the baseline), SanD-Planner achieves state-of-the-art performance on the evaluated open benchmark, attaining success rates of $90.1\%$ in simulated cluttered environments and $72.0\%$ in indoor simulations. The performance is further proven by demonstrating zero-shot transferability to realistic experimentation in both 2D and 3D scenes. The dataset and pre-trained models will also be open-sourced.
OpenNavMap: Structure-Free Topometric Mapping via Large-Scale Collaborative Localization
Jan 18, 2026Scalable and maintainable map representations are fundamental to enabling large-scale visual navigation and facilitating the deployment of robots in real-world environments. While collaborative localization across multi-session mapping enhances efficiency, traditional structure-based methods struggle with high maintenance costs and fail in feature-less environments or under significant viewpoint changes typical of crowd-sourced data. To address this, we propose OPENNAVMAP, a lightweight, structure-free topometric system leveraging 3D geometric foundation models for on-demand reconstruction. Our method unifies dynamic programming-based sequence matching, geometric verification, and confidence-calibrated optimization to robust, coarse-to-fine submap alignment without requiring pre-built 3D models. Evaluations on the Map-Free benchmark demonstrate superior accuracy over structure-from-motion and regression baselines, achieving an average translation error of 0.62m. Furthermore, the system maintains global consistency across 15km of multi-session data with an absolute trajectory error below 3m for map merging. Finally, we validate practical utility through 12 successful autonomous image-goal navigation tasks on simulated and physical robots. Code and datasets will be publicly available in https://rpl-cs-ucl.github.io/OpenNavMap_page.
A Framework for Deploying Learning-based Quadruped Loco-Manipulation
Dec 22, 2025Quadruped mobile manipulators offer strong potential for agile loco-manipulation but remain difficult to control and transfer reliably from simulation to reality. Reinforcement learning (RL) shows promise for whole-body control, yet most frameworks are proprietary and hard to reproduce on real hardware. We present an open pipeline for training, benchmarking, and deploying RL-based controllers on the Unitree B1 quadruped with a Z1 arm. The framework unifies sim-to-sim and sim-to-real transfer through ROS, re-implementing a policy trained in Isaac Gym, extending it to MuJoCo via a hardware abstraction layer, and deploying the same controller on physical hardware. Sim-to-sim experiments expose discrepancies between Isaac Gym and MuJoCo contact models that influence policy behavior, while real-world teleoperated object-picking trials show that coordinated whole-body control extends reach and improves manipulation over floating-base baselines. The pipeline provides a transparent, reproducible foundation for developing and analyzing RL-based loco-manipulation controllers and will be released open source to support future research.
E-SDS: Environment-aware See it, Do it, Sorted - Automated Environment-Aware Reinforcement Learning for Humanoid Locomotion
Dec 18, 2025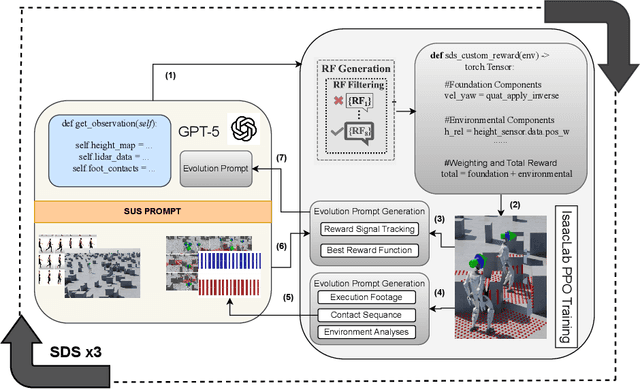
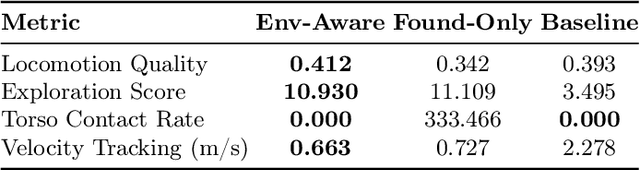
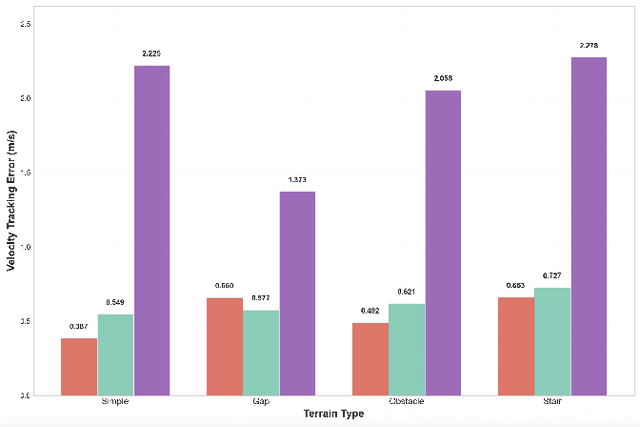

Vision-language models (VLMs) show promise in automating reward design in humanoid locomotion, which could eliminate the need for tedious manual engineering. However, current VLM-based methods are essentially "blind", as they lack the environmental perception required to navigate complex terrain. We present E-SDS (Environment-aware See it, Do it, Sorted), a framework that closes this perception gap. E-SDS integrates VLMs with real-time terrain sensor analysis to automatically generate reward functions that facilitate training of robust perceptive locomotion policies, grounded by example videos. Evaluated on a Unitree G1 humanoid across four distinct terrains (simple, gaps, obstacles, stairs), E-SDS uniquely enabled successful stair descent, while policies trained with manually-designed rewards or a non-perceptive automated baseline were unable to complete the task. In all terrains, E-SDS also reduced velocity tracking error by 51.9-82.6%. Our framework reduces the human effort of reward design from days to less than two hours while simultaneously producing more robust and capable locomotion policies.
* 12 pages, 3 figures, 4 tables. Accepted at RiTA 2025 (Springer LNNS)
The Starlink Robot: A Platform and Dataset for Mobile Satellite Communication
Jun 24, 2025The integration of satellite communication into mobile devices represents a paradigm shift in connectivity, yet the performance characteristics under motion and environmental occlusion remain poorly understood. We present the Starlink Robot, the first mobile robotic platform equipped with Starlink satellite internet, comprehensive sensor suite including upward-facing camera, LiDAR, and IMU, designed to systematically study satellite communication performance during movement. Our multi-modal dataset captures synchronized communication metrics, motion dynamics, sky visibility, and 3D environmental context across diverse scenarios including steady-state motion, variable speeds, and different occlusion conditions. This platform and dataset enable researchers to develop motion-aware communication protocols, predict connectivity disruptions, and optimize satellite communication for emerging mobile applications from smartphones to autonomous vehicles. The project is available at https://github.com/StarlinkRobot.
Follow Everything: A Leader-Following and Obstacle Avoidance Framework with Goal-Aware Adaptation
May 01, 2025



Robust and flexible leader-following is a critical capability for robots to integrate into human society. While existing methods struggle to generalize to leaders of arbitrary form and often fail when the leader temporarily leaves the robot's field of view, this work introduces a unified framework addressing both challenges. First, traditional detection models are replaced with a segmentation model, allowing the leader to be anything. To enhance recognition robustness, a distance frame buffer is implemented that stores leader embeddings at multiple distances, accounting for the unique characteristics of leader-following tasks. Second, a goal-aware adaptation mechanism is designed to govern robot planning states based on the leader's visibility and motion, complemented by a graph-based planner that generates candidate trajectories for each state, ensuring efficient following with obstacle avoidance. Simulations and real-world experiments with a legged robot follower and various leaders (human, ground robot, UAV, legged robot, stop sign) in both indoor and outdoor environments show competitive improvements in follow success rate, reduced visual loss duration, lower collision rate, and decreased leader-follower distance.
Immersive Teleoperation Framework for Locomanipulation Tasks
Apr 21, 2025Recent advancements in robotic loco-manipulation have leveraged Virtual Reality (VR) to enhance the precision and immersiveness of teleoperation systems, significantly outperforming traditional methods reliant on 2D camera feeds and joystick controls. Despite these advancements, challenges remain, particularly concerning user experience across different setups. This paper introduces a novel VR-based teleoperation framework designed for a robotic manipulator integrated onto a mobile platform. Central to our approach is the application of Gaussian splatting, a technique that abstracts the manipulable scene into a VR environment, thereby enabling more intuitive and immersive interactions. Users can navigate and manipulate within the virtual scene as if interacting with a real robot, enhancing both the engagement and efficacy of teleoperation tasks. An extensive user study validates our approach, demonstrating significant usability and efficiency improvements. Two-thirds (66%) of participants completed tasks faster, achieving an average time reduction of 43%. Additionally, 93% preferred the Gaussian Splat interface overall, with unanimous (100%) recommendations for future use, highlighting improvements in precision, responsiveness, and situational awareness. Finally, we demonstrate the effectiveness of our framework through real-world experiments in two distinct application scenarios, showcasing the practical capabilities and versatility of the Splat-based VR interface.
Unreal Robotics Lab: A High-Fidelity Robotics Simulator with Advanced Physics and Rendering
Apr 19, 2025High-fidelity simulation is essential for robotics research, enabling safe and efficient testing of perception, control, and navigation algorithms. However, achieving both photorealistic rendering and accurate physics modeling remains a challenge. This paper presents a novel simulation framework--the Unreal Robotics Lab (URL) that integrates the Unreal Engine's advanced rendering capabilities with MuJoCo's high-precision physics simulation. Our approach enables realistic robotic perception while maintaining accurate physical interactions, facilitating benchmarking and dataset generation for vision-based robotics applications. The system supports complex environmental effects, such as smoke, fire, and water dynamics, which are critical for evaluating robotic performance under adverse conditions. We benchmark visual navigation and SLAM methods within our framework, demonstrating its utility for testing real-world robustness in controlled yet diverse scenarios. By bridging the gap between physics accuracy and photorealistic rendering, our framework provides a powerful tool for advancing robotics research and sim-to-real transfer.
Exploring Adversarial Obstacle Attacks in Search-based Path Planning for Autonomous Mobile Robots
Apr 08, 2025



Path planning algorithms, such as the search-based A*, are a critical component of autonomous mobile robotics, enabling robots to navigate from a starting point to a destination efficiently and safely. We investigated the resilience of the A* algorithm in the face of potential adversarial interventions known as obstacle attacks. The adversary's goal is to delay the robot's timely arrival at its destination by introducing obstacles along its original path. We developed malicious software to execute the attacks and conducted experiments to assess their impact, both in simulation using TurtleBot in Gazebo and in real-world deployment with the Unitree Go1 robot. In simulation, the attacks resulted in an average delay of 36\%, with the most significant delays occurring in scenarios where the robot was forced to take substantially longer alternative paths. In real-world experiments, the delays were even more pronounced, with all attacks successfully rerouting the robot and causing measurable disruptions. These results highlight that the algorithm's robustness is not solely an attribute of its design but is significantly influenced by the operational environment. For example, in constrained environments like tunnels, the delays were maximized due to the limited availability of alternative routes.