 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDS -- See it, Do it, Sorted: Quadruped Skill Synthesis from Single Video Demonstration
Paper and Code
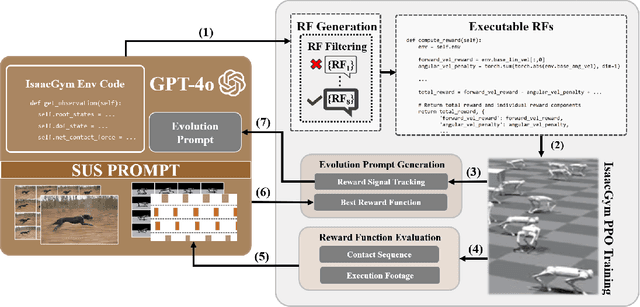


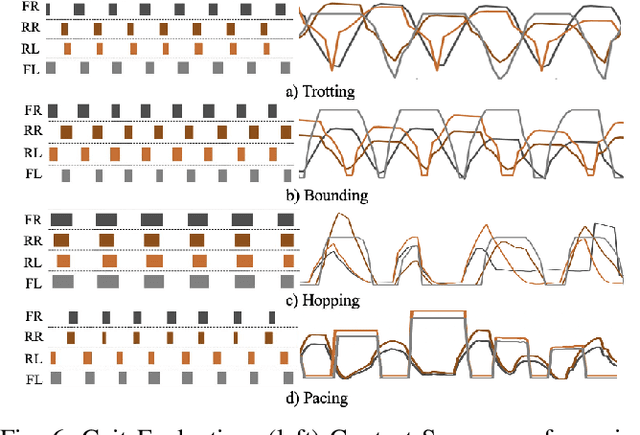
In this paper, we present SDS (``See it. Do it. Sorted.''), a novel pipeline for intuitive quadrupedal skill learning from a single demonstration video. Leveraging the Visual capabilities of GPT-4o, SDS processes input videos through our novel chain-of-thought promoting technique (SUS) and generates executable reward functions (RFs) that drive the imitation of locomotion skills, through learning a Proximal Policy Optimization (PPO)-based Reinforcement Learning (RL) policy, using environment information from the NVIDIA IsaacGym simulator. SDS autonomously evaluates the RFs by monitoring the individual reward components and supplying training footage and fitness metrics back into GPT-4o, which is then prompted to evolve the RFs to achieve higher task fitness at each iteration. We validate our method on the Unitree Go1 robot, demonstrating its ability to execute variable skills such as trotting, bounding, pacing and hopping, achieving high imitation fidelity and locomotion stability. SDS shows improvements over SOTA methods in task adaptability, reduced dependence on domain-specific knowledge, and bypassing the need for labor-intensive reward engineering and large-scale training datasets. Additional information and the open-sourced code can be found in: https://rpl-cs-ucl.github.io/SDSweb