 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Single Extractor: Re-thinking HTML-to-Text Extraction for LLM Pretraining
Feb 23, 2026One of the first pre-processing steps for constructing web-scale LLM pretraining datasets involves extracting text from HTML. Despite the immense diversity of web content, existing open-source datasets predominantly apply a single fixed extractor to all webpages. In this work, we investigate whether this practice leads to suboptimal coverage and utilization of Internet data. We first show that while different extractors may lead to similar model performance on standard language understanding tasks, the pages surviving a fixed filtering pipeline can differ substantially. This suggests a simple intervention: by taking a Union over different extractors, we can increase the token yield of DCLM-Baseline by up to 71% while maintaining benchmark performance. We further show that for structured content such as tables and code blocks, extractor choice can significantly impact downstream task performance, with differences of up to 10 percentage points (p.p.) on WikiTQ and 3 p.p. on HumanEval.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
Language Models Improve When Pretraining Data Matches Target Tasks
Jul 16, 2025Every data selection method inherently has a target. In practice, these targets often emerge implicitly through benchmark-driven iteration: researchers develop selection strategies, train models, measure benchmark performance, then refine accordingly. This raises a natural question: what happens when we make this optimization explicit? To explore this, we propose benchmark-targeted ranking (BETR), a simple method that selects pretraining documents based on similarity to benchmark training examples. BETR embeds benchmark examples and a sample of pretraining documents in a shared space, scores this sample by similarity to benchmarks, then trains a lightweight classifier to predict these scores for the full corpus. We compare data selection methods by training over 500 models spanning $10^{19}$ to $10^{22}$ FLOPs and fitting scaling laws to them. From this, we find that simply aligning pretraining data to evaluation benchmarks using BETR achieves a 2.1x compute multiplier over DCLM-Baseline (4.7x over unfiltered data) and improves performance on 9 out of 10 tasks across all scales. BETR also generalizes well: when targeting a diverse set of benchmarks disjoint from our evaluation suite, it still matches or outperforms baselines. Our scaling analysis further reveals a clear trend: larger models require less aggressive filtering. Overall, our findings show that directly matching pretraining data to target tasks precisely shapes model capabilities and highlight that optimal selection strategies must adapt to model scale.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
TiC-LM: A Web-Scale Benchmark for Time-Continual LLM Pretraining
Apr 02, 2025Large Language Models (LLMs) trained on historical web data inevitably become outdated. We investigate evaluation strategies and update methods for LLMs as new data becomes available. We introduce a web-scale dataset for time-continual pretraining of LLMs derived from 114 dumps of Common Crawl (CC) - orders of magnitude larger than previous continual language modeling benchmarks. We also design time-stratified evaluations across both general CC data and specific domains (Wikipedia, StackExchange, and code documentation) to assess how well various continual learning methods adapt to new data while retaining past knowledge. Our findings demonstrate that, on general CC data, autoregressive meta-schedules combined with a fixed-ratio replay of older data can achieve comparable held-out loss to re-training from scratch, while requiring significantly less computation (2.6x). However, the optimal balance between incorporating new data and replaying old data differs as replay is crucial to avoid forgetting on generic web data but less so on specific domains.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Stronger Than You Think: Benchmarking Weak Supervision on Realistic Tasks
Jan 13, 2025Weak supervision (WS) is a popular approach for label-efficient learning, leveraging diverse sources of noisy but inexpensive weak labels to automatically annotate training data. Despite its wide usage, WS and its practical value are challenging to benchmark due to the many knobs in its setup, including: data sources, labeling functions (LFs), aggregation techniques (called label models), and end model pipelines. Existing evaluation suites tend to be limited, focusing on particular components or specialized use cases. Moreover, they often involve simplistic benchmark tasks or de-facto LF sets that are suboptimally written, producing insights that may not generalize to real-world settings. We address these limitations by introducing a new benchmark, BOXWRENCH, designed to more accurately reflect real-world usages of WS. This benchmark features tasks with (1) higher class cardinality and imbalance, (2) notable domain expertise requirements, and (3) multilingual variations across parallel corpora. For all tasks, LFs are written using a careful procedure aimed at mimicking real-world settings. In contrast to existing WS benchmarks, we show that supervised learning requires substantial amounts (1000+) of labeled examples to match WS in many settings.
SDS -- See it, Do it, Sorted: Quadruped Skill Synthesis from Single Video Demonstration
Oct 15, 2024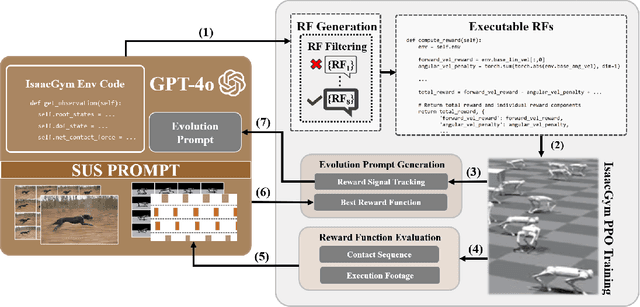


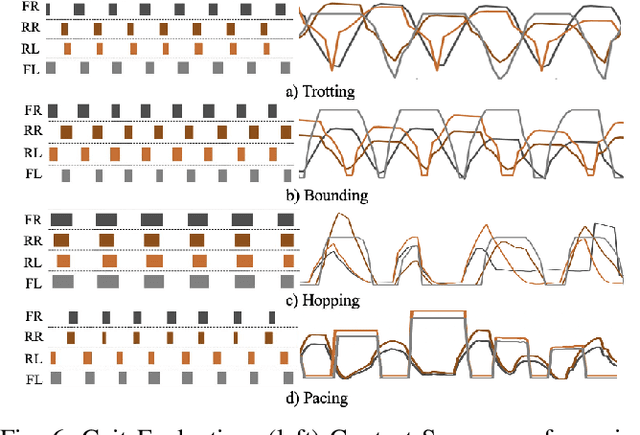
In this paper, we present SDS (``See it. Do it. Sorted.''), a novel pipeline for intuitive quadrupedal skill learning from a single demonstration video. Leveraging the Visual capabilities of GPT-4o, SDS processes input videos through our novel chain-of-thought promoting technique (SUS) and generates executable reward functions (RFs) that drive the imitation of locomotion skills, through learning a Proximal Policy Optimization (PPO)-based Reinforcement Learning (RL) policy, using environment information from the NVIDIA IsaacGym simulator. SDS autonomously evaluates the RFs by monitoring the individual reward components and supplying training footage and fitness metrics back into GPT-4o, which is then prompted to evolve the RFs to achieve higher task fitness at each iteration. We validate our method on the Unitree Go1 robot, demonstrating its ability to execute variable skills such as trotting, bounding, pacing and hopping, achieving high imitation fidelity and locomotion stability. SDS shows improvements over SOTA methods in task adaptability, reduced dependence on domain-specific knowledge, and bypassing the need for labor-intensive reward engineering and large-scale training datasets. Additional information and the open-sourced code can be found in: https://rpl-cs-ucl.github.io/SDSweb
Better Alignment with Instruction Back-and-Forth Translation
Aug 08, 2024



We propose a new method, instruction back-and-forth translation, to construct high-quality synthetic data grounded in world knowledge for aligning large language models (LLMs). Given documents from a web corpus, we generate and curate synthetic instructions using the backtranslation approach proposed by Li et al.(2023a), and rewrite the responses to improve their quality further based on the initial documents. Fine-tuning with the resulting (backtranslated instruction, rewritten response) pairs yields higher win rates on AlpacaEval than using other common instruction datasets such as Humpback, ShareGPT, Open Orca, Alpaca-GPT4 and Self-instruct. We also demonstrate that rewriting the responses with an LLM outperforms direct distillation, and the two generated text distributions exhibit significant distinction in embedding space. Further analysis shows that our backtranslated instructions are of higher quality than other sources of synthetic instructions, while our responses are more diverse and complex than those obtained from distillation. Overall we find that instruction back-and-forth translation combines the best of both worlds -- making use of the information diversity and quantity found on the web, while ensuring the quality of the responses which is necessary for effective alignment.