 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing initial human-AI proof formalization workflows
Jun 02, 2026For centuries, human mathematicians have written proofs to substantiate their mathematical arguments; yet, the ability to automatically verify the validity of proofs has long been a challenge. Advances in AI systems' ability to generate code and engage in increasingly high-level mathematical reasoning promise to transform people's ability to formalize and thereby verify proofs. While many works focus on benchmarking the current frontier, we instead study how people use these tools. We conduct a mixed-methods analysis into the initial impact of AI on people's formalization workflows: what people claim they want, what they see as the barriers to those visions, and how they actually use and adapt AI in practice. A qualitative survey shows that people's preferences are diverse, but with a general desire for AI assistance in formalization that preserves high-level human control over the proof discovery process. To assess how people actually engage with AI for formalization under such limitations, we conduct a controlled user study in which participants formalize informal math problems and their proofs, with and without AI, across a range of mathematical problems at varying levels of difficulty and domains. Despite limitations of the tools at the time for autoformalization, participants tend to attain higher formalization accuracy when allowed access to AI tools than when formalizing on their own, with most participants flexibly choosing to use multiple different AI tools. Taken together, our work sheds light on the early stages of AI integration into formalization workflows, involving an intimate interplay of human and AI engagement.
Comparing Developer and LLM Biases in Code Evaluation
Mar 25, 2026As LLMs are increasingly used as judges in code applications, they should be evaluated in realistic interactive settings that capture partial context and ambiguous intent. We present TRACE (Tool for Rubric Analysis in Code Evaluation), a framework that evaluates LLM judges' ability to predict human preferences and automatically extracts rubric items to reveal systematic biases in how humans and models weigh each item. Across three modalities -- chat-based programming, IDE autocompletion, and instructed code editing -- we use TRACE to measure how well LLM judges align with developer preferences. Among 13 different models, the best judges underperform human annotators by 12-23%. TRACE identifies 35 significant sources of misalignment between humans and judges across interaction modalities, the majority of which correspond to existing software engineering code quality criteria. For example, in chat-based coding, judges are biased towards longer code explanations while humans prefer shorter ones. We find significant misalignment on the majority of existing code quality dimensions, showing alignment gaps between LLM judges and human preference in realistic coding applications.
RCTs & Human Uplift Studies: Methodological Challenges and Practical Solutions for Frontier AI Evaluation
Mar 11, 2026Human uplift studies - or studies that measure AI effects on human performance relative to a status quo, typically using randomized controlled trial (RCT) methodology - are increasingly used to inform deployment, governance, and safety decisions for frontier AI systems. While the methods underlying these studies are well-established, their interaction with the distinctive properties of frontier AI systems remains underexamined, particularly when results are used to inform high-stakes decisions. We present findings from interviews with 16 expert practitioners with experience conducting human uplift studies in domains including biosecurity, cybersecurity, education, and labor. Across interviews, experts described a recurring tension between standard causal inference assumptions and the object of study itself. Rapidly evolving AI systems, shifting baselines, heterogeneous and changing user proficiency, and porous real-world settings strain assumptions underlying internal, external, and construct validity, complicating the interpretation and appropriate use of uplift evidence. We synthesize these challenges across key stages of the human uplift research lifecycle and map them to practitioner-reported solutions, clarifying both the limits and the appropriate uses of evidence from human uplift studies in high-stakes decision-making.
A Rubric-Supervised Critic from Sparse Real-World Outcomes
Mar 04, 2026Academic benchmarks for coding agents tend to reward autonomous task completion, measured by verifiable rewards such as unit-test success. In contrast, real-world coding agents operate with humans in the loop, where success signals are typically noisy, delayed, and sparse. How can we bridge this gap? In this paper, we propose a process to learn a "critic" model from sparse and noisy interaction data, which can then be used both as a reward model for either RL-based training or inference-time scaling. Specifically, we introduce Critic Rubrics, a rubric-based supervision framework with 24 behavioral features that can be derived from human-agent interaction traces alone. Using a semi-supervised objective, we can then jointly predict these rubrics and sparse human feedback (when present). In experiments, we demonstrate that, despite being trained primarily from trace-observable rubrics and sparse real-world outcome proxies, these critics improve best-of-N reranking on SWE-bench (Best@8 +15.9 over Random@8 over the rerankable subset of trajectories), enable early stopping (+17.7 with 83% fewer attempts), and support training-time data curation via critic-selected trajectories.
How Well Does Agent Development Reflect Real-World Work?
Mar 01, 2026AI agents are increasingly developed and evaluated on benchmarks relevant to human work, yet it remains unclear how representative these benchmarking efforts are of the labor market as a whole. In this work, we systematically study the relationship between agent development efforts and the distribution of real-world human work by mapping benchmark instances to work domains and skills. We first analyze 43 benchmarks and 72,342 tasks, measuring their alignment with human employment and capital allocation across all 1,016 real-world occupations in the U.S. labor market. We reveal substantial mismatches between agent development that tends to be programming-centric, and the categories in which human labor and economic value are concentrated. Within work areas that agents currently target, we further characterize current agent utility by measuring their autonomy levels, providing practical guidance for agent interaction strategies across work scenarios. Building on these findings, we propose three measurable principles for designing benchmarks that better capture socially important and technically challenging forms of work: coverage, realism, and granular evaluation.
GameDevBench: Evaluating Agentic Capabilities Through Game Development
Feb 11, 2026Despite rapid progress on coding agents, progress on their multimodal counterparts has lagged behind. A key challenge is the scarcity of evaluation testbeds that combine the complexity of software development with the need for deep multimodal understanding. Game development provides such a testbed as agents must navigate large, dense codebases while manipulating intrinsically multimodal assets such as shaders, sprites, and animations within a visual game scene. We present GameDevBench, the first benchmark for evaluating agents on game development tasks. GameDevBench consists of 132 tasks derived from web and video tutorials. Tasks require significant multimodal understanding and are complex -- the average solution requires over three times the amount of lines of code and file changes compared to prior software development benchmarks. Agents still struggle with game development, with the best agent solving only 54.5% of tasks. We find a strong correlation between perceived task difficulty and multimodal complexity, with success rates dropping from 46.9% on gameplay-oriented tasks to 31.6% on 2D graphics tasks. To improve multimodal capability, we introduce two simple image and video-based feedback mechanisms for agents. Despite their simplicity, these methods consistently improve performance, with the largest change being an increase in Claude Sonnet 4.5's performance from 33.3% to 47.7%. We release GameDevBench publicly to support further research into agentic game development.
SWE-Tester: Training Open-Source LLMs for Issue Reproduction in Real-World Repositories
Jan 20, 2026Software testing is crucial for ensuring the correctness and reliability of software systems. Automated generation of issue reproduction tests from natural language issue descriptions enhances developer productivity by simplifying root cause analysis, promotes test-driven development -- "test first, write code later", and can be used for improving the effectiveness of automated issue resolution systems like coding agents. Existing methods proposed for this task predominantly rely on closed-source LLMs, with limited exploration of open models. To address this, we propose SWE-Tester -- a novel pipeline for training open-source LLMs to generate issue reproduction tests. First, we curate a high-quality training dataset of 41K instances from 2.6K open-source GitHub repositories and use it to train LLMs of varying sizes and families. The fine-tuned models achieve absolute improvements of up to 10\% in success rate and 21\% in change coverage on SWT-Bench Verified. Further analysis shows consistent improvements with increased inference-time compute, more data, and larger models. These results highlight the effectiveness of our framework for advancing open-source LLMs in this domain.
The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents
Nov 05, 2025


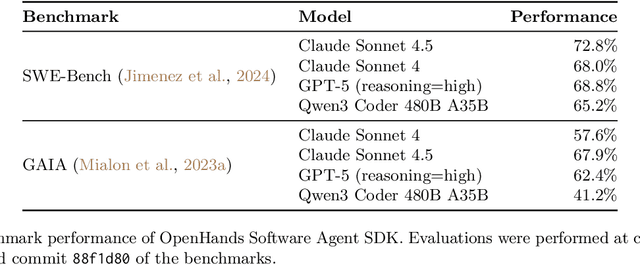
Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
Completion $ eq$ Collaboration: Scaling Collaborative Effort with Agents
Oct 30, 2025Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals are often underspecified and evolve. We argue for a shift from building and assessing task completion agents to developing collaborative agents, assessed not only by the quality of their final outputs but by how well they engage with and enhance human effort throughout the problem-solving process. To support this shift, we introduce collaborative effort scaling, a framework that captures how an agent's utility grows with increasing user involvement. Through case studies and simulated evaluations, we show that state-of-the-art agents often underperform in multi-turn, real-world scenarios, revealing a missing ingredient in agent design: the ability to sustain engagement and scaffold user understanding. Collaborative effort scaling offers a lens for diagnosing agent behavior and guiding development toward more effective interactions.
Beyond Memorization: Mapping the Originality-Quality Frontier of Language Models
Apr 13, 2025As large language models (LLMs) are increasingly used for ideation and scientific discovery, it is important to evaluate their ability to generate novel output. Prior work evaluates novelty as the originality with respect to training data, but original outputs can be low quality. In contrast, non-expert judges may favor high-quality but memorized outputs, limiting the reliability of human preference as a metric. We propose a new novelty metric for LLM generations that balances originality and quality -- the harmonic mean of the fraction of \ngrams unseen during training and a task-specific quality score. We evaluate the novelty of generations from two families of open-data models (OLMo and Pythia) on three creative tasks: story completion, poetry writing, and creative tool use. We find that LLM generated text is less novel than human written text. To elicit more novel outputs, we experiment with various inference-time methods, which reveals a trade-off between originality and quality. While these methods can boost novelty, they do so by increasing originality at the expense of quality. In contrast, increasing model size or applying post-training reliably shifts the Pareto frontier, highlighting that starting with a stronger base model is a more effective way to improve novelty.