 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Neural Scaling Laws
Jan 27, 2026Neural scaling laws predict how language model performance improves with increased compute. While aggregate metrics like validation loss can follow smooth power-law curves, individual downstream tasks exhibit diverse scaling behaviors: some improve monotonically, others plateau, and some even degrade with scale. We argue that predicting downstream performance from validation perplexity suffers from two limitations: averaging token-level losses obscures signal, and no simple parametric family can capture the full spectrum of scaling behaviors. To address this, we propose Neural Neural Scaling Laws (NeuNeu), a neural network that frames scaling law prediction as time-series extrapolation. NeuNeu combines temporal context from observed accuracy trajectories with token-level validation losses, learning to predict future performance without assuming any bottleneck or functional form. Trained entirely on open-source model checkpoints from HuggingFace, NeuNeu achieves 2.04% mean absolute error in predicting model accuracy on 66 downstream tasks -- a 38% reduction compared to logistic scaling laws (3.29% MAE). Furthermore, NeuNeu generalizes zero-shot to unseen model families, parameter counts, and downstream tasks. Our work suggests that predicting downstream scaling laws directly from data outperforms parametric alternatives.
Beyond Memorization: Mapping the Originality-Quality Frontier of Language Models
Apr 13, 2025As large language models (LLMs) are increasingly used for ideation and scientific discovery, it is important to evaluate their ability to generate novel output. Prior work evaluates novelty as the originality with respect to training data, but original outputs can be low quality. In contrast, non-expert judges may favor high-quality but memorized outputs, limiting the reliability of human preference as a metric. We propose a new novelty metric for LLM generations that balances originality and quality -- the harmonic mean of the fraction of \ngrams unseen during training and a task-specific quality score. We evaluate the novelty of generations from two families of open-data models (OLMo and Pythia) on three creative tasks: story completion, poetry writing, and creative tool use. We find that LLM generated text is less novel than human written text. To elicit more novel outputs, we experiment with various inference-time methods, which reveals a trade-off between originality and quality. While these methods can boost novelty, they do so by increasing originality at the expense of quality. In contrast, increasing model size or applying post-training reliably shifts the Pareto frontier, highlighting that starting with a stronger base model is a more effective way to improve novelty.
Reasoning Models Know When They're Right: Probing Hidden States for Self-Verification
Apr 07, 2025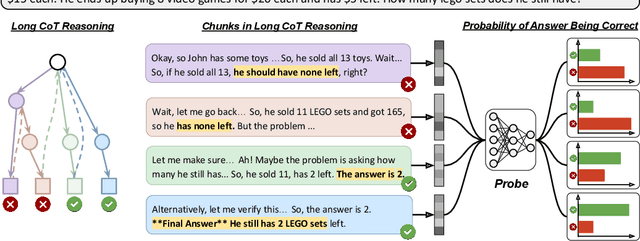
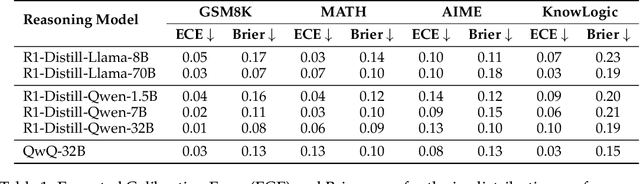
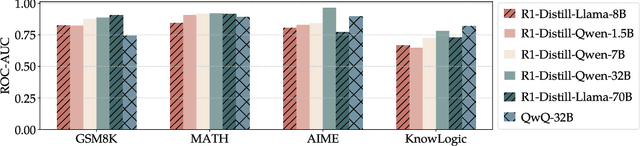
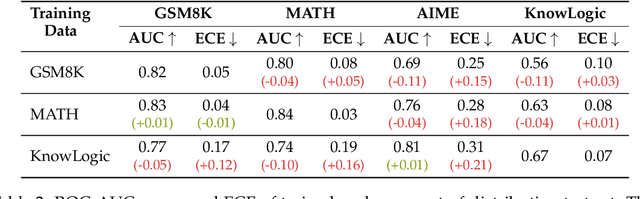
Reasoning models have achieved remarkable performance on tasks like math and logical reasoning thanks to their ability to search during reasoning. However, they still suffer from overthinking, often performing unnecessary reasoning steps even after reaching the correct answer. This raises the question: can models evaluate the correctness of their intermediate answers during reasoning? In this work, we study whether reasoning models encode information about answer correctness through probing the model's hidden states. The resulting probe can verify intermediate answers with high accuracy and produces highly calibrated scores. Additionally, we find models' hidden states encode correctness of future answers, enabling early prediction of the correctness before the intermediate answer is fully formulated. We then use the probe as a verifier to decide whether to exit reasoning at intermediate answers during inference, reducing the number of inference tokens by 24\% without compromising performance. These findings confirm that reasoning models do encode a notion of correctness yet fail to exploit it, revealing substantial untapped potential to enhance their efficiency.
Spontaneous Reward Hacking in Iterative Self-Refinement
Jul 05, 2024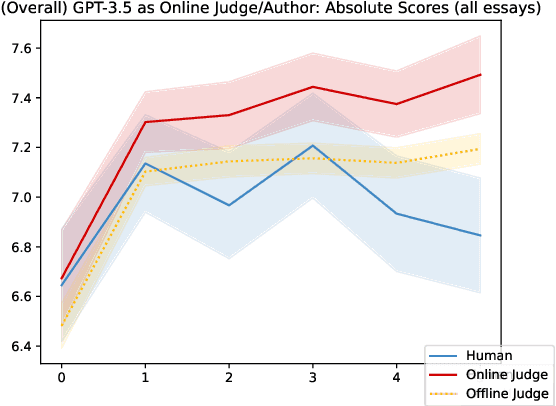
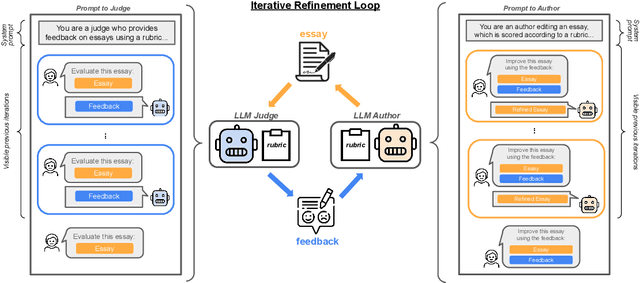
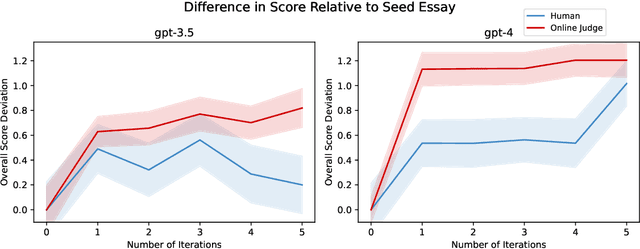
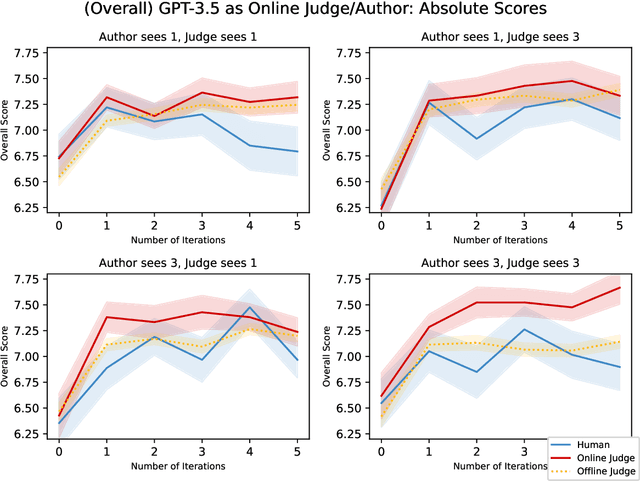
Language models are capable of iteratively improving their outputs based on natural language feedback, thus enabling in-context optimization of user preference. In place of human users, a second language model can be used as an evaluator, providing feedback along with numerical ratings which the generator attempts to optimize. However, because the evaluator is an imperfect proxy of user preference, this optimization can lead to reward hacking, where the evaluator's ratings improve while the generation quality remains stagnant or even decreases as judged by actual user preference. The concern of reward hacking is heightened in iterative self-refinement where the generator and the evaluator use the same underlying language model, in which case the optimization pressure can drive them to exploit shared vulnerabilities. Using an essay editing task, we show that iterative self-refinement leads to deviation between the language model evaluator and human judgment, demonstrating that reward hacking can occur spontaneously in-context with the use of iterative self-refinement. In addition, we study conditions under which reward hacking occurs and observe two factors that affect reward hacking severity: model size and context sharing between the generator and the evaluator.
What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning
May 16, 2023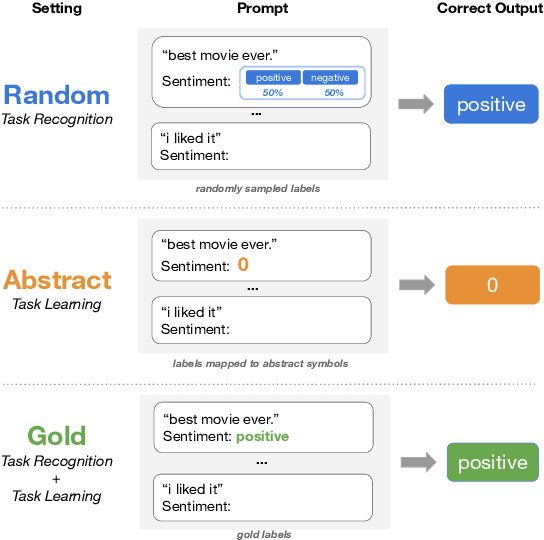

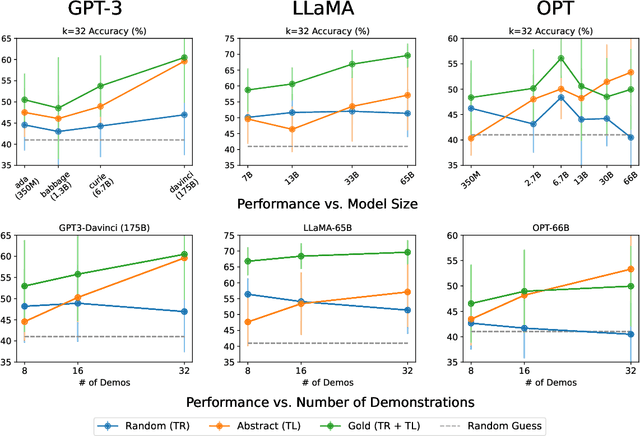
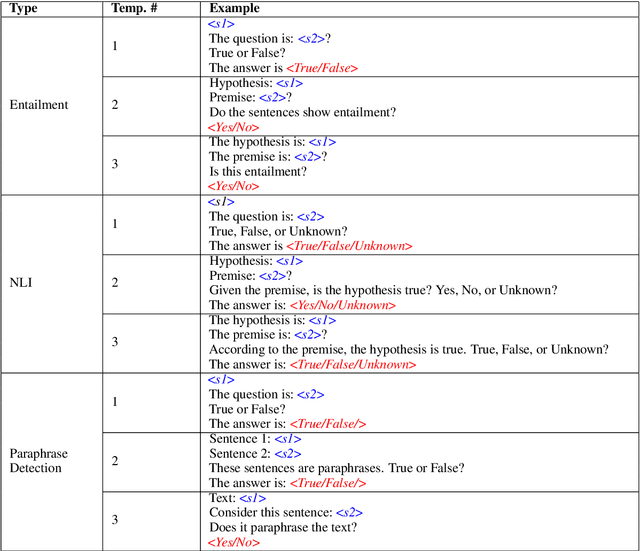
Large language models (LLMs) exploit in-context learning (ICL) to solve tasks with only a few demonstrations, but its mechanisms are not yet well-understood. Some works suggest that LLMs only recall already learned concepts from pre-training, while others hint that ICL performs implicit learning over demonstrations. We characterize two ways through which ICL leverages demonstrations. Task recognition (TR) captures the extent to which LLMs can recognize a task through demonstrations -- even without ground-truth labels -- and apply their pre-trained priors, whereas task learning (TL) is the ability to capture new input-label mappings unseen in pre-training. Using a wide range of classification datasets and three LLM families (GPT-3, LLaMA and OPT), we design controlled experiments to disentangle the roles of TR and TL in ICL. We show that (1) models can achieve non-trivial performance with only TR, and TR does not further improve with larger models or more demonstrations; (2) LLMs acquire TL as the model scales, and TL's performance consistently improves with more demonstrations in context. Our findings unravel two different forces behind ICL and we advocate for discriminating them in future ICL research due to their distinct nature.