 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetaining by Doing: The Role of On-Policy Data in Mitigating Forgetting
Oct 21, 2025
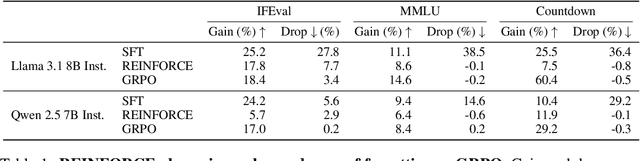
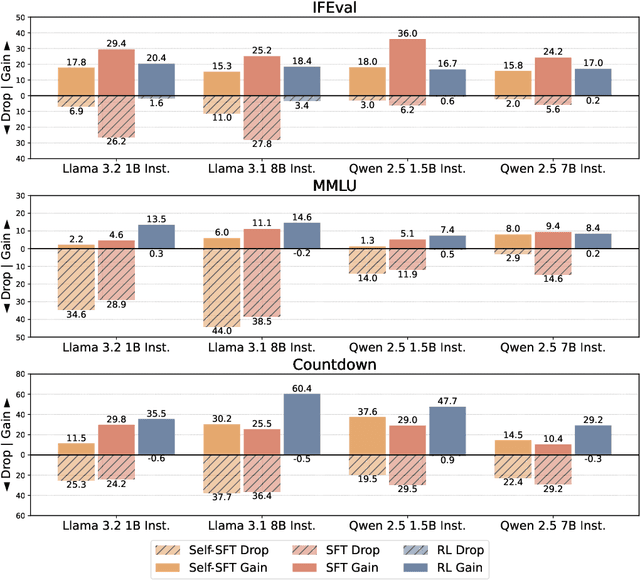
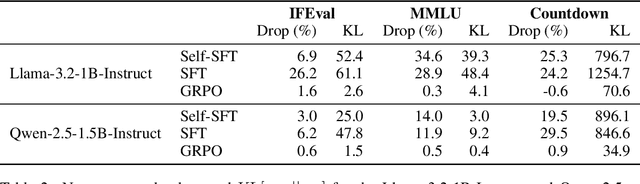
Adapting language models (LMs) to new tasks via post-training carries the risk of degrading existing capabilities -- a phenomenon classically known as catastrophic forgetting. In this paper, toward identifying guidelines for mitigating this phenomenon, we systematically compare the forgetting patterns of two widely adopted post-training methods: supervised fine-tuning (SFT) and reinforcement learning (RL). Our experiments reveal a consistent trend across LM families (Llama, Qwen) and tasks (instruction following, general knowledge, and arithmetic reasoning): RL leads to less forgetting than SFT while achieving comparable or higher target task performance. To investigate the cause for this difference, we consider a simplified setting in which the LM is modeled as a mixture of two distributions, one corresponding to prior knowledge and the other to the target task. We identify that the mode-seeking nature of RL, which stems from its use of on-policy data, enables keeping prior knowledge intact when learning the target task. We then verify this insight by demonstrating that the use on-policy data underlies the robustness of RL to forgetting in practical settings, as opposed to other algorithmic choices such as the KL regularization or advantage estimation. Lastly, as a practical implication, our results highlight the potential of mitigating forgetting using approximately on-policy data, which can be substantially more efficient to obtain than fully on-policy data.
Are Large Language Models Reliable AI Scientists? Assessing Reverse-Engineering of Black-Box Systems
May 23, 2025Using AI to create autonomous researchers has the potential to accelerate scientific discovery. A prerequisite for this vision is understanding how well an AI model can identify the underlying structure of a black-box system from its behavior. In this paper, we explore how well a large language model (LLM) learns to identify a black-box function from passively observed versus actively collected data. We investigate the reverse-engineering capabilities of LLMs across three distinct types of black-box systems, each chosen to represent different problem domains where future autonomous AI researchers may have considerable impact: Program, Formal Language, and Math Equation. Through extensive experiments, we show that LLMs fail to extract information from observations, reaching a performance plateau that falls short of the ideal of Bayesian inference. However, we demonstrate that prompting LLMs to not only observe but also intervene -- actively querying the black-box with specific inputs to observe the resulting output -- improves performance by allowing LLMs to test edge cases and refine their beliefs. By providing the intervention data from one LLM to another, we show that this improvement is partly a result of engaging in the process of generating effective interventions, paralleling results in the literature on human learning. Further analysis reveals that engaging in intervention can help LLMs escape from two common failure modes: overcomplication, where the LLM falsely assumes prior knowledge about the black-box, and overlooking, where the LLM fails to incorporate observations. These insights provide practical guidance for helping LLMs more effectively reverse-engineer black-box systems, supporting their use in making new discoveries.
Continual Memorization of Factoids in Large Language Models
Nov 11, 2024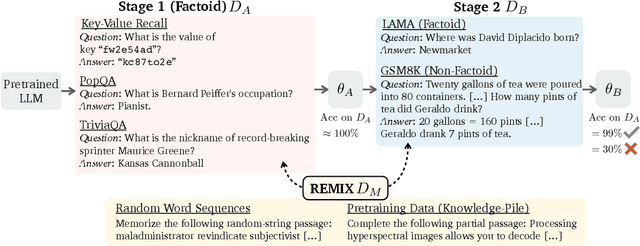
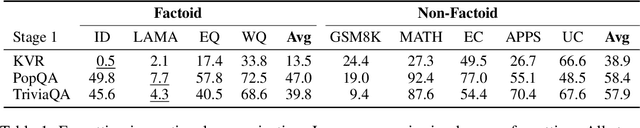
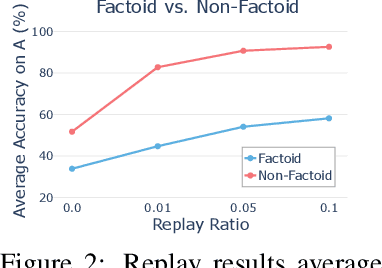
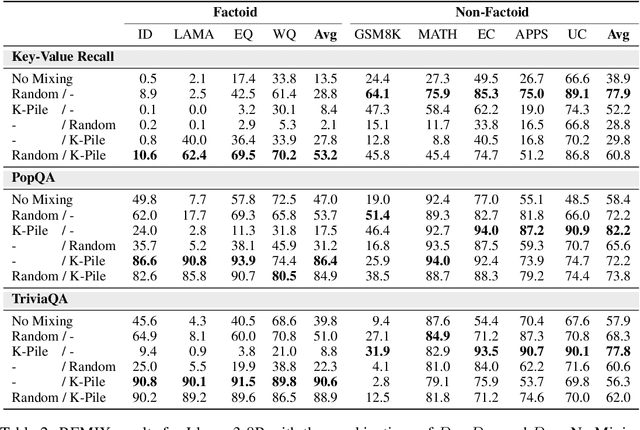
Large language models can absorb a massive amount of knowledge through pretraining, but pretraining is inefficient for acquiring long-tailed or specialized facts. Therefore, fine-tuning on specialized or new knowledge that reflects changes in the world has become popular, though it risks disrupting the model's original capabilities. We study this fragility in the context of continual memorization, where the model is trained on a small set of long-tail factoids (factual associations) and must retain these factoids after multiple stages of subsequent training on other datasets. Through extensive experiments, we show that LLMs suffer from forgetting across a wide range of subsequent tasks, and simple replay techniques do not fully prevent forgetting, especially when the factoid datasets are trained in the later stages. We posit that there are two ways to alleviate forgetting: 1) protect the memorization process as the model learns the factoids, or 2) reduce interference from training in later stages. With this insight, we develop an effective mitigation strategy: REMIX (Random and Generic Data Mixing). REMIX prevents forgetting by mixing generic data sampled from pretraining corpora or even randomly generated word sequences during each stage, despite being unrelated to the memorized factoids in the first stage. REMIX can recover performance from severe forgetting, often outperforming replay-based methods that have access to the factoids from the first stage. We then analyze how REMIX alters the learning process and find that successful forgetting prevention is associated with a pattern: the model stores factoids in earlier layers than usual and diversifies the set of layers that store these factoids. The efficacy of REMIX invites further investigation into the underlying dynamics of memorization and forgetting, opening exciting possibilities for future research.
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs
Jun 26, 2024



Chart understanding plays a pivotal role when applying Multimodal Large Language Models (MLLMs) to real-world tasks such as analyzing scientific papers or financial reports. However, existing datasets often focus on oversimplified and homogeneous charts with template-based questions, leading to an over-optimistic measure of progress. We demonstrate that although open-source models can appear to outperform strong proprietary models on these benchmarks, a simple stress test with slightly different charts or questions can deteriorate performance by up to 34.5%. In this work, we propose CharXiv, a comprehensive evaluation suite involving 2,323 natural, challenging, and diverse charts from arXiv papers. CharXiv includes two types of questions: 1) descriptive questions about examining basic chart elements and 2) reasoning questions that require synthesizing information across complex visual elements in the chart. To ensure quality, all charts and questions are handpicked, curated, and verified by human experts. Our results reveal a substantial, previously underestimated gap between the reasoning skills of the strongest proprietary model (i.e., GPT-4o), which achieves 47.1% accuracy, and the strongest open-source model (i.e., InternVL Chat V1.5), which achieves 29.2%. All models lag far behind human performance of 80.5%, underscoring weaknesses in the chart understanding capabilities of existing MLLMs. We hope CharXiv facilitates future research on MLLM chart understanding by providing a more realistic and faithful measure of progress. Project page and leaderboard: https://charxiv.github.io/
Language Models as Science Tutors
Feb 16, 2024



NLP has recently made exciting progress toward training language models (LMs) with strong scientific problem-solving skills. However, model development has not focused on real-life use-cases of LMs for science, including applications in education that require processing long scientific documents. To address this, we introduce TutorEval and TutorChat. TutorEval is a diverse question-answering benchmark consisting of questions about long chapters from STEM textbooks, written by experts. TutorEval helps measure real-life usability of LMs as scientific assistants, and it is the first benchmark combining long contexts, free-form generation, and multi-disciplinary scientific knowledge. Moreover, we show that fine-tuning base models with existing dialogue datasets leads to poor performance on TutorEval. Therefore, we create TutorChat, a dataset of 80,000 long synthetic dialogues about textbooks. We use TutorChat to fine-tune Llemma models with 7B and 34B parameters. These LM tutors specialized in math have a 32K-token context window, and they excel at TutorEval while performing strongly on GSM8K and MATH. Our datasets build on open-source materials, and we release our models, data, and evaluations.
Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading
Oct 08, 2023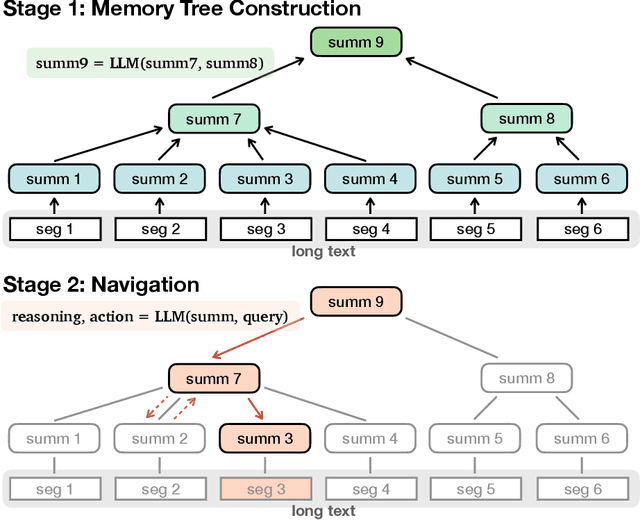

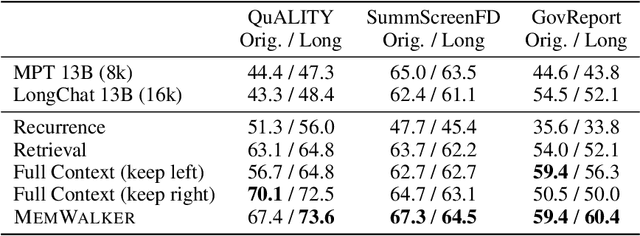
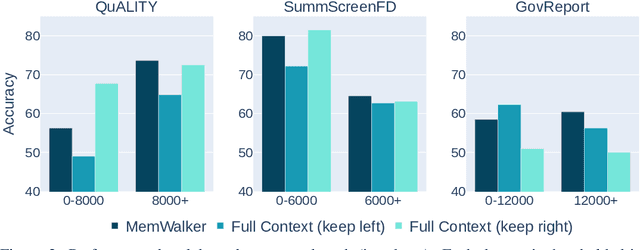
Large language models (LLMs) have advanced in large strides due to the effectiveness of the self-attention mechanism that processes and compares all tokens at once. However, this mechanism comes with a fundamental issue -- the predetermined context window is bound to be limited. Despite attempts to extend the context window through methods like extrapolating the positional embedding, using recurrence, or selectively retrieving essential parts of the long sequence, long-text understanding continues to be a challenge. We propose an alternative approach which instead treats the LLM as an interactive agent, allowing it to decide how to read the text via iterative prompting. We introduce MemWalker, a method that first processes the long context into a tree of summary nodes. Upon receiving a query, the model navigates this tree in search of relevant information, and responds once it gathers sufficient information. On long-text question answering tasks our method outperforms baseline approaches that use long context windows, recurrence, and retrieval. We show that, beyond effective reading, MemWalker enhances explainability by highlighting the reasoning steps as it interactively reads the text; pinpointing the relevant text segments related to the query.
COLLIE: Systematic Construction of Constrained Text Generation Tasks
Jul 17, 2023Text generation under constraints have seen increasing interests in natural language processing, especially with the rapidly improving capabilities of large language models. However, existing benchmarks for constrained generation usually focus on fixed constraint types (e.g.,generate a sentence containing certain words) that have proved to be easy for state-of-the-art models like GPT-4. We present COLLIE, a grammar-based framework that allows the specification of rich, compositional constraints with diverse generation levels (word, sentence, paragraph, passage) and modeling challenges (e.g.,language understanding, logical reasoning, counting, semantic planning). We also develop tools for automatic extraction of task instances given a constraint structure and a raw text corpus. Using COLLIE, we compile the COLLIE-v1 dataset with 2080 instances comprising 13 constraint structures. We perform systematic experiments across five state-of-the-art instruction-tuned language models and analyze their performances to reveal shortcomings. COLLIE is designed to be extensible and lightweight, and we hope the community finds it useful to develop more complex constraints and evaluations in the future.
CSTS: Conditional Semantic Textual Similarity
May 24, 2023
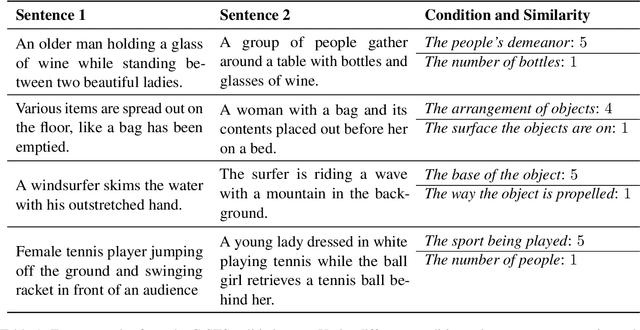
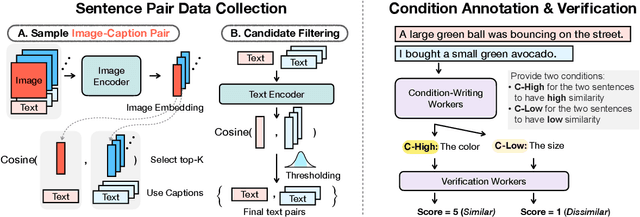
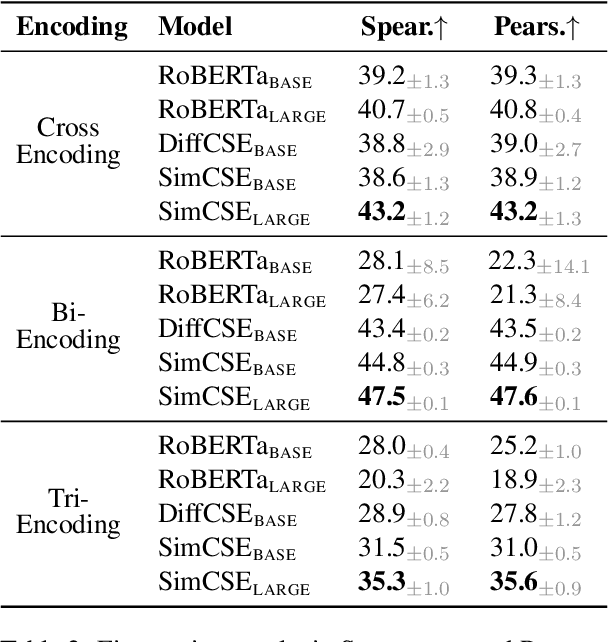
Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). As an example, the similarity between the sentences "The NBA player shoots a three-pointer." and "A man throws a tennis ball into the air to serve." is higher for the condition "The motion of the ball." (both upward) and lower for "The size of the ball." (one large and one small). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we evaluate several state-of-the-art models to demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging, with Spearman correlation scores of <50. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding.
What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning
May 16, 2023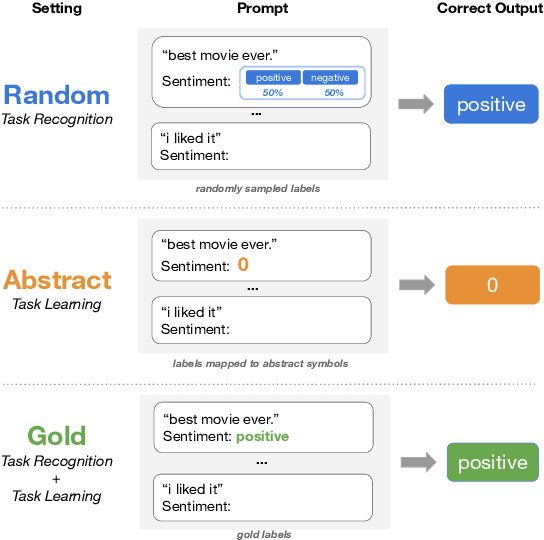

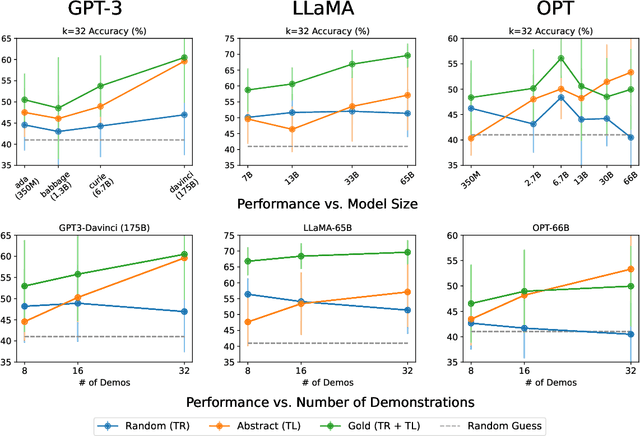
Large language models (LLMs) exploit in-context learning (ICL) to solve tasks with only a few demonstrations, but its mechanisms are not yet well-understood. Some works suggest that LLMs only recall already learned concepts from pre-training, while others hint that ICL performs implicit learning over demonstrations. We characterize two ways through which ICL leverages demonstrations. Task recognition (TR) captures the extent to which LLMs can recognize a task through demonstrations -- even without ground-truth labels -- and apply their pre-trained priors, whereas task learning (TL) is the ability to capture new input-label mappings unseen in pre-training. Using a wide range of classification datasets and three LLM families (GPT-3, LLaMA and OPT), we design controlled experiments to disentangle the roles of TR and TL in ICL. We show that (1) models can achieve non-trivial performance with only TR, and TR does not further improve with larger models or more demonstrations; (2) LLMs acquire TL as the model scales, and TL's performance consistently improves with more demonstrations in context. Our findings unravel two different forces behind ICL and we advocate for discriminating them in future ICL research due to their distinct nature.
Controllable Text Generation with Language Constraints
Dec 20, 2022



We consider the task of text generation in language models with constraints specified in natural language. To this end, we first create a challenging benchmark Cognac that provides as input to the model a topic with example text, along with a constraint on text to be avoided. Unlike prior work, our benchmark contains knowledge-intensive constraints sourced from databases like Wordnet and Wikidata, which allows for straightforward evaluation while striking a balance between broad attribute-level and narrow lexical-level controls. We find that even state-of-the-art language models like GPT-3 fail often on this task, and propose a solution to leverage a language model's own internal knowledge to guide generation. Our method, called CognacGen, first queries the language model to generate guidance terms for a specified topic or constraint, and uses the guidance to modify the model's token generation probabilities. We propose three forms of guidance (binary verifier, top-k tokens, textual example), and employ prefix-tuning approaches to distill the guidance to tackle diverse natural language constraints. Through extensive empirical evaluations, we demonstrate that CognacGen can successfully generalize to unseen instructions and outperform competitive baselines in generating constraint conforming text.