 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs are Superior Feedback Providers: Bootstrapping Reasoning for Lie Detection with Self-Generated Feedback
Aug 25, 2024



Large Language Models (LLMs) excel at generating human-like dialogues and comprehending text. However, understanding the subtleties of complex exchanges in language remains a challenge. We propose a bootstrapping framework that leverages self-generated feedback to enhance LLM reasoning capabilities for lie detection. The framework consists of three stages: suggestion, feedback collection, and modification. In the suggestion stage, a cost-effective language model generates initial predictions based on game state and dialogue. The feedback-collection stage involves a language model providing feedback on these predictions. In the modification stage, a more advanced language model refines the initial predictions using the auto-generated feedback. We investigate the application of the proposed framework for detecting betrayal and deception in Diplomacy games, and compare it with feedback from professional human players. The LLM-generated feedback exhibits superior quality and significantly enhances the performance of the model. Our approach achieves a 39% improvement over the zero-shot baseline in lying-F1 without the need for any training data, rivaling state-of-the-art supervised learning results.
COLLIE: Systematic Construction of Constrained Text Generation Tasks
Jul 17, 2023Text generation under constraints have seen increasing interests in natural language processing, especially with the rapidly improving capabilities of large language models. However, existing benchmarks for constrained generation usually focus on fixed constraint types (e.g.,generate a sentence containing certain words) that have proved to be easy for state-of-the-art models like GPT-4. We present COLLIE, a grammar-based framework that allows the specification of rich, compositional constraints with diverse generation levels (word, sentence, paragraph, passage) and modeling challenges (e.g.,language understanding, logical reasoning, counting, semantic planning). We also develop tools for automatic extraction of task instances given a constraint structure and a raw text corpus. Using COLLIE, we compile the COLLIE-v1 dataset with 2080 instances comprising 13 constraint structures. We perform systematic experiments across five state-of-the-art instruction-tuned language models and analyze their performances to reveal shortcomings. COLLIE is designed to be extensible and lightweight, and we hope the community finds it useful to develop more complex constraints and evaluations in the future.
DataMUX: Data Multiplexing for Neural Networks
Feb 18, 2022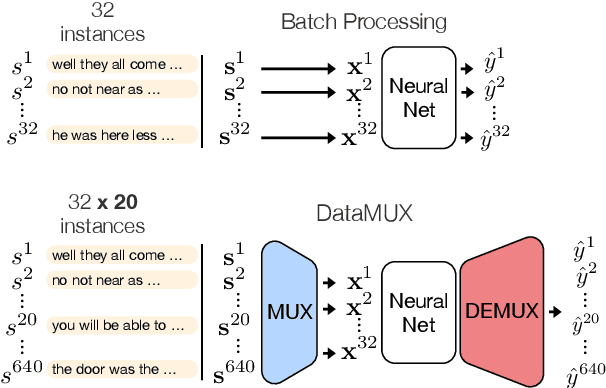
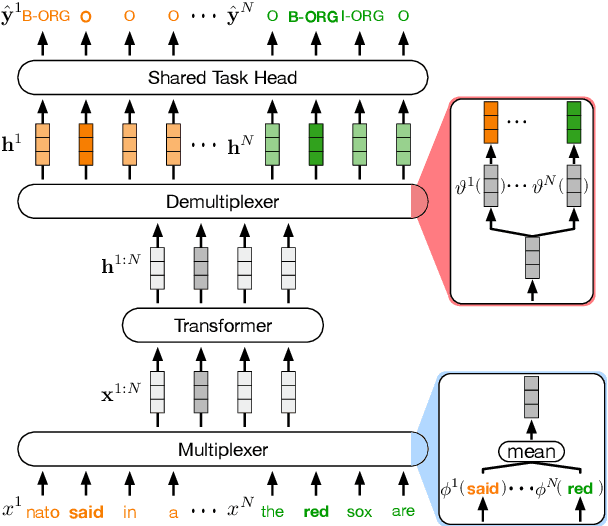
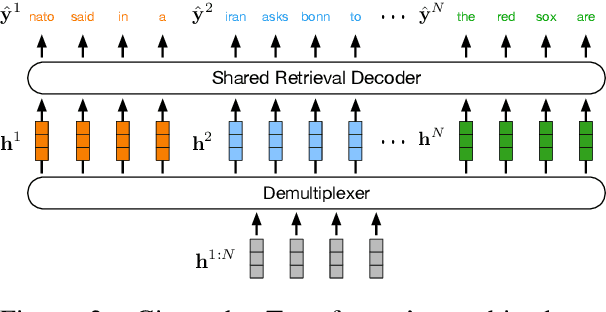
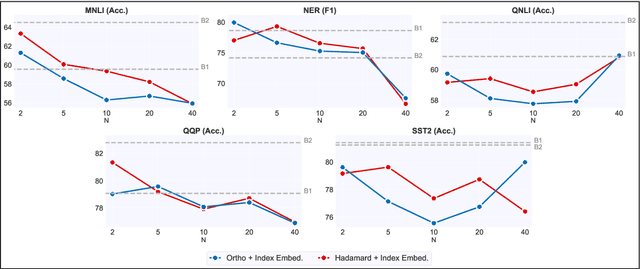
In this paper, we introduce data multiplexing (DataMUX), a technique that enables deep neural networks to process multiple inputs simultaneously using a single compact representation. DataMUX demonstrates that neural networks are capable of generating accurate predictions over mixtures of inputs, resulting in increased throughput with minimal extra memory requirements. Our approach uses two key components -- 1) a multiplexing layer that performs a fixed linear transformation to each input before combining them to create a mixed representation of the same size as a single input, which is then processed by the base network, and 2) a demultiplexing layer that converts the base network's output back into independent representations before producing predictions for each input. We show the viability of DataMUX for different architectures (Transformers, and to a lesser extent MLPs and CNNs) across six different tasks spanning sentence classification, named entity recognition and image classification. For instance, DataMUX for Transformers can multiplex up to $20$x/$40$x inputs, achieving $11$x/$18$x increase in throughput with minimal absolute performance drops of $<2\%$ and $<4\%$ respectively on MNLI, a natural language inference task. We also provide a theoretical construction for multiplexing in self-attention networks and analyze the effect of various design elements in DataMUX.
Generating Strategic Dialogue for Negotiation with Theory of Mind
Oct 20, 2020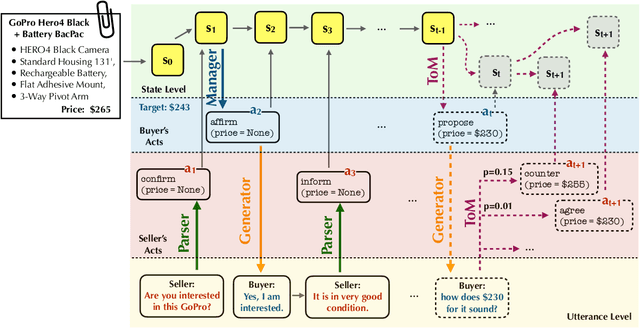

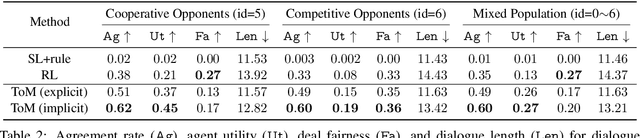
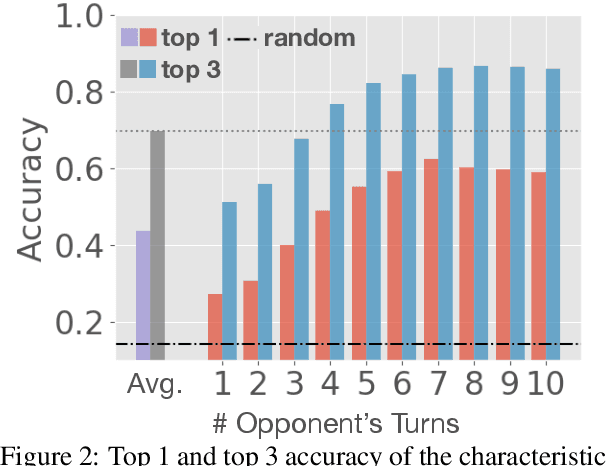
We propose a framework to integrate the concept of Theory of Mind (ToM) into generating utterances for task-oriented dialogue. Our approach explores the ability to model and infer personality types of opponents, predicts their responses, and uses this information to adapt the agent's high-level strategy in negotiation tasks. We introduce a probabilistic formulation for the first-order theory of mind and test our approach on the CraigslistBargain dataset. Experiments show that our method using ToM inference achieves a 40\% higher dialogue agreement rate compared to baselines on a mixed population of opponents. We also show that our model displays diverse negotiation behavior with different types of opponents.
A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation
Aug 21, 2019
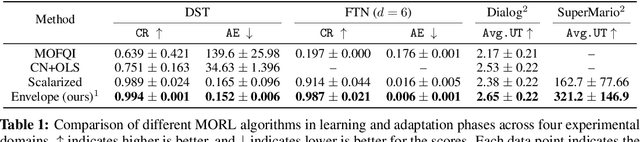
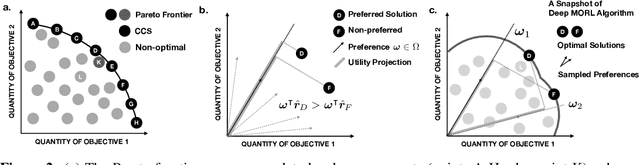

We introduce a new algorithm for multi-objective reinforcement learning (MORL) with linear preferences, with the goal of enabling few-shot adaptation to new tasks. In MORL, the aim is to learn policies over multiple competing objectives whose relative importance (preferences) is unknown to the agent. While this alleviates dependence on scalar reward design, the expected return of a policy can change significantly with varying preferences, making it challenging to learn a single model to produce optimal policies under different preference conditions. We propose a generalized version of the Bellman equation to learn a single parametric representation for optimal policies over the space of all possible preferences. After this initial learning phase, our agent can quickly adapt to any given preference, or automatically infer an underlying preference with very few samples. Experiments across four different domains demonstrate the effectiveness of our approach.
Imitation Refinement
May 07, 2018
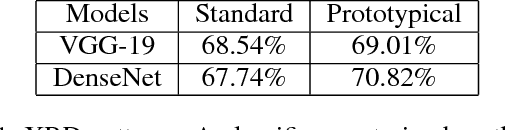
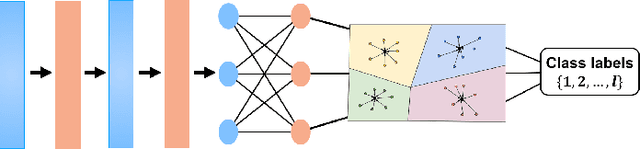

Many real-world tasks involve identifying patterns from data satisfying background and prior knowledge, for which the ground truth is not available, but ideal data can be obtained, for example, using theoretical simulations. We propose a novel approach, imitation refinement, which refines imperfect patterns by imitating ideal patterns. The imperfect patterns are obtained for example using an unsupervised learner. Imitation refinement imitates ideal data by incorporating prior knowledge captured by a classifier trained on the ideal data: an imitation refiner applies small modifications to imperfect patterns so that the classifier can identify them. In a sense, imitation refinement fits the data to the classifier, which complements the classical supervised learning task. We show that our imitation refinement approach outperforms existing methods in identifying crystal patterns from X-ray diffraction data in materials discovery. We also show the generality of our approach by illustrating its applicability to a computer vision task.