 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLLIE: Systematic Construction of Constrained Text Generation Tasks
Jul 17, 2023Text generation under constraints have seen increasing interests in natural language processing, especially with the rapidly improving capabilities of large language models. However, existing benchmarks for constrained generation usually focus on fixed constraint types (e.g.,generate a sentence containing certain words) that have proved to be easy for state-of-the-art models like GPT-4. We present COLLIE, a grammar-based framework that allows the specification of rich, compositional constraints with diverse generation levels (word, sentence, paragraph, passage) and modeling challenges (e.g.,language understanding, logical reasoning, counting, semantic planning). We also develop tools for automatic extraction of task instances given a constraint structure and a raw text corpus. Using COLLIE, we compile the COLLIE-v1 dataset with 2080 instances comprising 13 constraint structures. We perform systematic experiments across five state-of-the-art instruction-tuned language models and analyze their performances to reveal shortcomings. COLLIE is designed to be extensible and lightweight, and we hope the community finds it useful to develop more complex constraints and evaluations in the future.
Semantic Supervision: Enabling Generalization over Output Spaces
Mar 15, 2022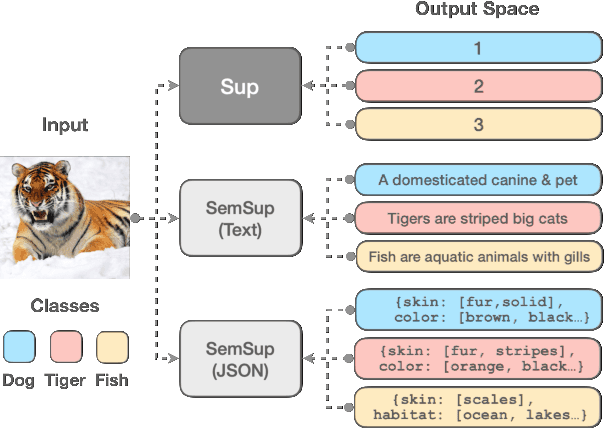
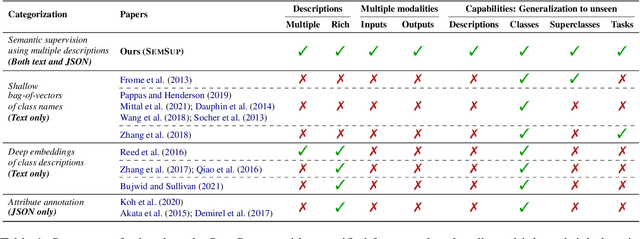
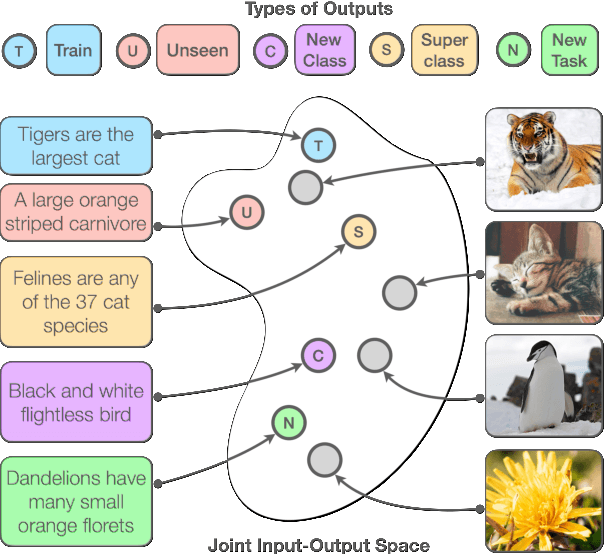
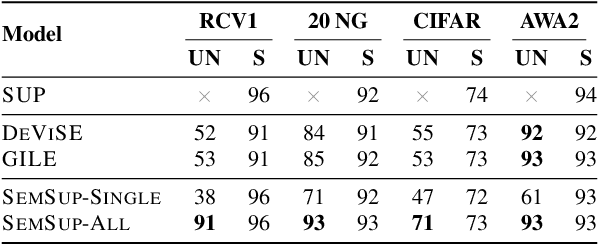
In this paper, we propose Semantic Supervision (SemSup) - a unified paradigm for training classifiers that generalize over output spaces. In contrast to standard classification, which treats classes as discrete symbols, SemSup represents them as dense vector features obtained from descriptions of classes (e.g., "The cat is a small carnivorous mammal"). This allows the output space to be unbounded (in the space of descriptions) and enables models to generalize both over unseen inputs and unseen outputs (e.g. "The aardvark is a nocturnal burrowing mammal with long ears"). Specifically, SemSup enables four types of generalization, to -- (1) unseen class descriptions, (2) unseen classes, (3) unseen super-classes, and (4) unseen tasks. Through experiments on four classification datasets across two variants (multi-class and multi-label), two input modalities (text and images), and two output description modalities (text and JSON), we show that our SemSup models significantly outperform standard supervised models and existing models that leverage word embeddings over class names. For instance, our model outperforms baselines by 40% and 15% precision points on unseen descriptions and classes, respectively, on a news categorization dataset (RCV1). SemSup can serve as a pathway for scaling neural models to large unbounded output spaces and enabling better generalization and model reuse for unseen tasks and domains.
SILG: The Multi-environment Symbolic Interactive Language Grounding Benchmark
Oct 20, 2021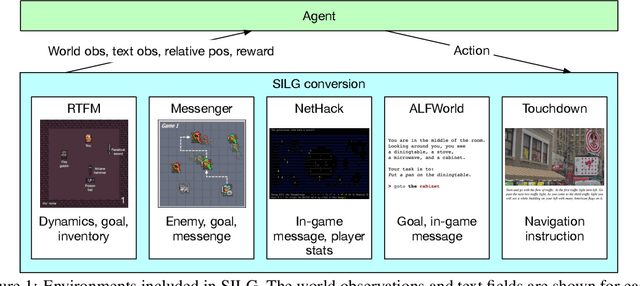
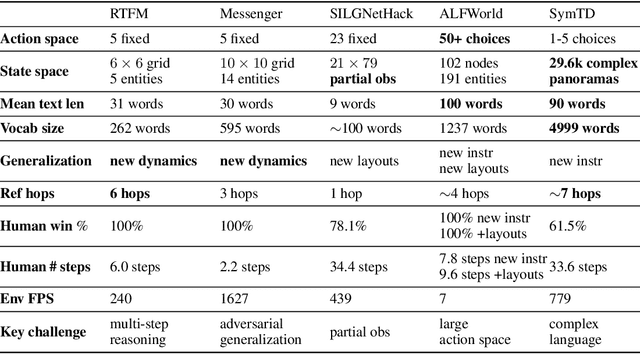
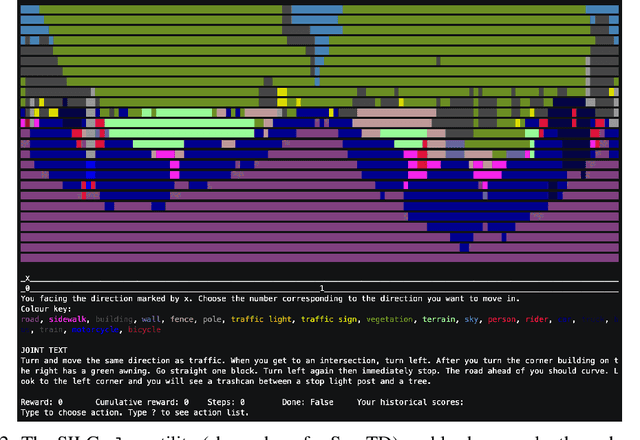
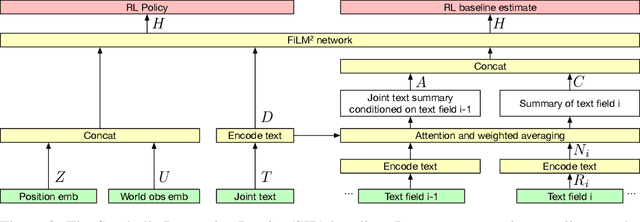
Existing work in language grounding typically study single environments. How do we build unified models that apply across multiple environments? We propose the multi-environment Symbolic Interactive Language Grounding benchmark (SILG), which unifies a collection of diverse grounded language learning environments under a common interface. SILG consists of grid-world environments that require generalization to new dynamics, entities, and partially observed worlds (RTFM, Messenger, NetHack), as well as symbolic counterparts of visual worlds that require interpreting rich natural language with respect to complex scenes (ALFWorld, Touchdown). Together, these environments provide diverse grounding challenges in richness of observation space, action space, language specification, and plan complexity. In addition, we propose the first shared model architecture for RL on these environments, and evaluate recent advances such as egocentric local convolution, recurrent state-tracking, entity-centric attention, and pretrained LM using SILG. Our shared architecture achieves comparable performance to environment-specific architectures. Moreover, we find that many recent modelling advances do not result in significant gains on environments other than the one they were designed for. This highlights the need for a multi-environment benchmark. Finally, the best models significantly underperform humans on SILG, which suggests ample room for future work. We hope SILG enables the community to quickly identify new methodologies for language grounding that generalize to a diverse set of environments and their associated challenges.