 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
Feb 25, 2025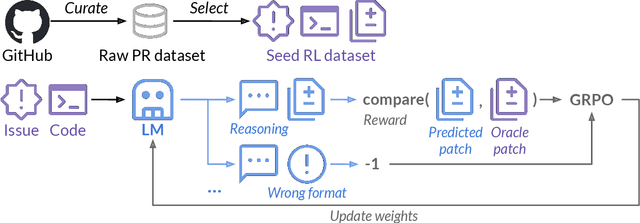


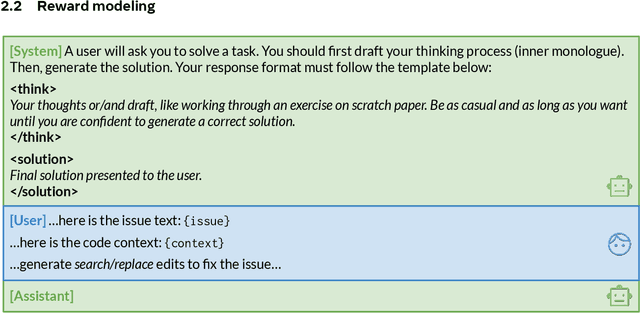
The recent DeepSeek-R1 release has demonstrated the immense potential of reinforcement learning (RL) in enhancing the general reasoning capabilities of large language models (LLMs). While DeepSeek-R1 and other follow-up work primarily focus on applying RL to competitive coding and math problems, this paper introduces SWE-RL, the first approach to scale RL-based LLM reasoning for real-world software engineering. Leveraging a lightweight rule-based reward (e.g., the similarity score between ground-truth and LLM-generated solutions), SWE-RL enables LLMs to autonomously recover a developer's reasoning processes and solutions by learning from extensive open-source software evolution data -- the record of a software's entire lifecycle, including its code snapshots, code changes, and events such as issues and pull requests. Trained on top of Llama 3, our resulting reasoning model, Llama3-SWE-RL-70B, achieves a 41.0% solve rate on SWE-bench Verified -- a human-verified collection of real-world GitHub issues. To our knowledge, this is the best performance reported for medium-sized (<100B) LLMs to date, even comparable to leading proprietary LLMs like GPT-4o. Surprisingly, despite performing RL solely on software evolution data, Llama3-SWE-RL has even emerged with generalized reasoning skills. For example, it shows improved results on five out-of-domain tasks, namely, function coding, library use, code reasoning, mathematics, and general language understanding, whereas a supervised-finetuning baseline even leads to performance degradation on average. Overall, SWE-RL opens up a new direction to improve the reasoning capabilities of LLMs through reinforcement learning on massive software engineering data.
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
Oct 04, 2024



Autonomous systems for software engineering are now capable of fixing bugs and developing features. These systems are commonly evaluated on SWE-bench (Jimenez et al., 2024a), which assesses their ability to solve software issues from GitHub repositories. However, SWE-bench uses only Python repositories, with problem statements presented predominantly as text and lacking visual elements such as images. This limited coverage motivates our inquiry into how existing systems might perform on unrepresented software engineering domains (e.g., front-end, game development, DevOps), which use different programming languages and paradigms. Therefore, we propose SWE-bench Multimodal (SWE-bench M), to evaluate systems on their ability to fix bugs in visual, user-facing JavaScript software. SWE-bench M features 617 task instances collected from 17 JavaScript libraries used for web interface design, diagramming, data visualization, syntax highlighting, and interactive mapping. Each SWE-bench M task instance contains at least one image in its problem statement or unit tests. Our analysis finds that top-performing SWE-bench systems struggle with SWE-bench M, revealing limitations in visual problem-solving and cross-language generalization. Lastly, we show that SWE-agent's flexible language-agnostic features enable it to substantially outperform alternatives on SWE-bench M, resolving 12% of task instances compared to 6% for the next best system.
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Jan 05, 2024We present CRUXEval (Code Reasoning, Understanding, and eXecution Evaluation), a benchmark consisting of 800 Python functions (3-13 lines). Each function comes with an input-output pair, leading to two natural tasks: input prediction and output prediction. First, we propose a generic recipe for generating our execution benchmark which can be used to create future variation of the benchmark. Second, we evaluate twenty code models on our benchmark and discover that many recent high-scoring models on HumanEval do not show the same improvements on our benchmark. Third, we show that simple CoT and fine-tuning schemes can improve performance on our benchmark but remain far from solving it. The best setup, GPT-4 with chain of thought (CoT), achieves a pass@1 of 75% and 81% on input and output prediction, respectively. In contrast, Code Llama 34B achieves a pass@1 of 50% and 46% on input and output prediction, highlighting the gap between open and closed source models. As no model is close to acing CRUXEval, we provide examples of consistent GPT-4 failures on simple programs as a lens into its code reasoning capabilities and areas for improvement.
Accessing Higher Dimensions for Unsupervised Word Translation
May 23, 2023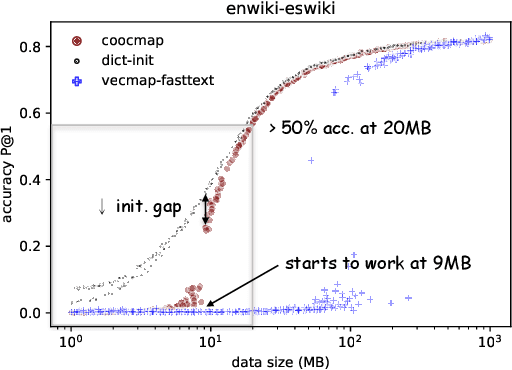
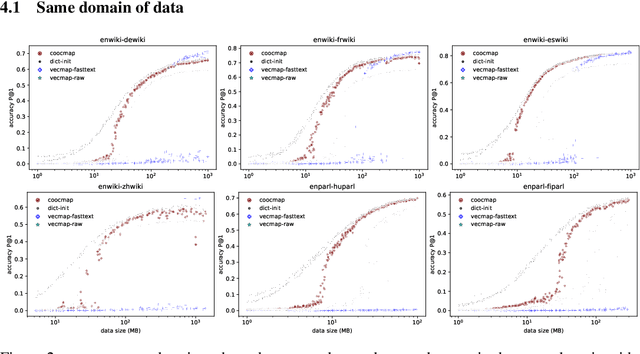
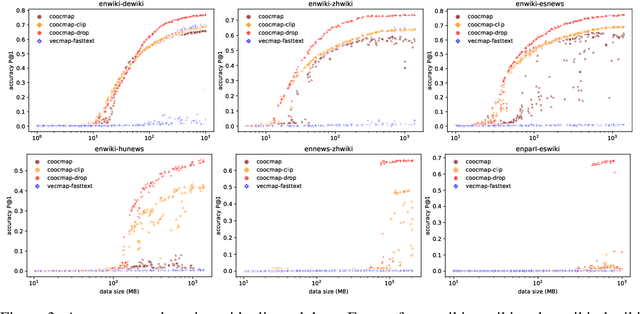
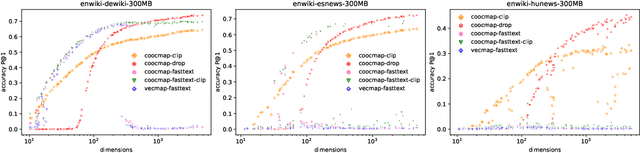
The striking ability of unsupervised word translation has been demonstrated with the help of word vectors / pretraining; however, they require large amounts of data and usually fails if the data come from different domains. We propose coocmap, a method that can use either high-dimensional co-occurrence counts or their lower-dimensional approximations. Freed from the limits of low dimensions, we show that relying on low-dimensional vectors and their incidental properties miss out on better denoising methods and useful world knowledge in high dimensions, thus stunting the potential of the data. Our results show that unsupervised translation can be achieved more easily and robustly than previously thought -- less than 80MB and minutes of CPU time is required to achieve over 50\% accuracy for English to Finnish, Hungarian, and Chinese translations when trained on similar data; even under domain mismatch, we show coocmap still works fully unsupervised on English NewsCrawl to Chinese Wikipedia and English Europarl to Spanish Wikipedia, among others. These results challenge prevailing assumptions on the necessity and superiority of low-dimensional vectors, and suggest that similarly processed co-occurrences can outperform dense vectors on other tasks too.
Learning to Simulate Natural Language Feedback for Interactive Semantic Parsing
May 14, 2023



Interactive semantic parsing based on natural language (NL) feedback, where users provide feedback to correct the parser mistakes, has emerged as a more practical scenario than the traditional one-shot semantic parsing. However, prior work has heavily relied on human-annotated feedback data to train the interactive semantic parser, which is prohibitively expensive and not scalable. In this work, we propose a new task of simulating NL feedback for interactive semantic parsing. We accompany the task with a novel feedback evaluator. The evaluator is specifically designed to assess the quality of the simulated feedback, based on which we decide the best feedback simulator from our proposed variants. On a text-to-SQL dataset, we show that our feedback simulator can generate high-quality NL feedback to boost the error correction ability of a specific parser. In low-data settings, our feedback simulator can help achieve comparable error correction performance as trained using the costly, full set of human annotations.
LEVER: Learning to Verify Language-to-Code Generation with Execution
Feb 16, 2023The advent of pre-trained code language models (CodeLMs) has lead to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
Coder Reviewer Reranking for Code Generation
Nov 29, 2022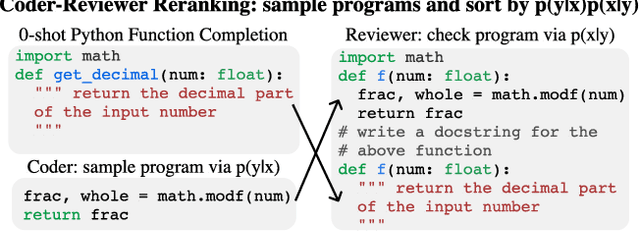
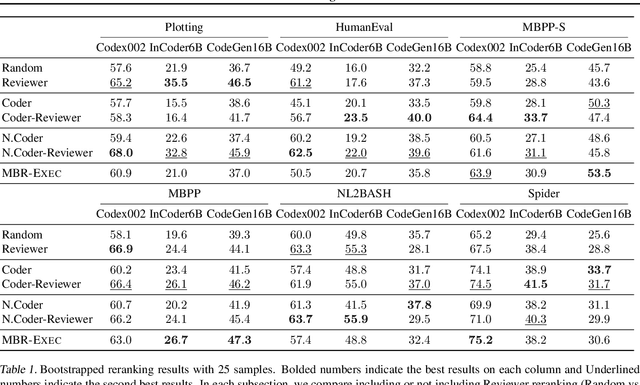

Sampling diverse programs from a code language model and reranking with model likelihood is a popular method for code generation but it is prone to preferring degenerate solutions. Inspired by collaborative programming, we propose Coder-Reviewer reranking. We augment Coder language models from past work, which generate programs given language instructions, with Reviewer models, which evaluate the likelihood of the instruction given the generated programs. We perform an extensive study across six datasets with eight models from three model families. Experimental results show that Coder-Reviewer reranking leads to consistent and significant improvement (up to 17% absolute accuracy gain) over reranking with the Coder model only. When combined with executability filtering, Coder-Reviewer reranking can often outperform the minimum Bayes risk method. Coder-Reviewer reranking is easy to implement by prompting, can generalize to different programming languages, and works well with off-the-shelf hyperparameters.
Natural Language to Code Translation with Execution
Apr 25, 2022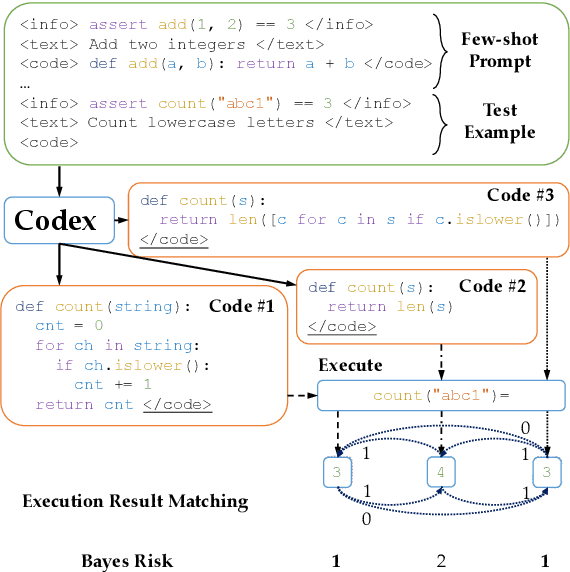

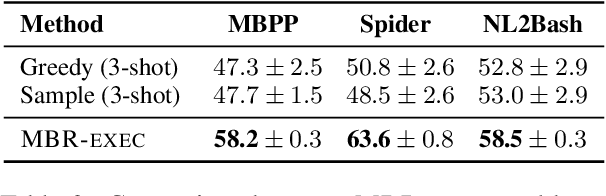
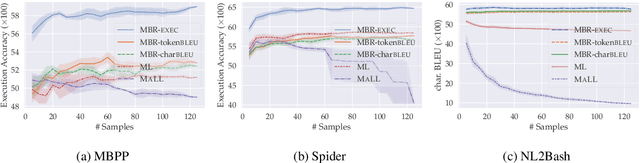
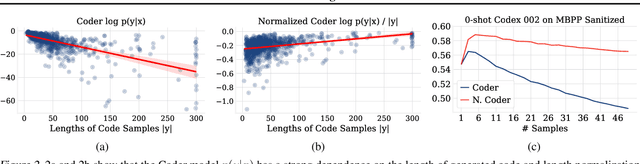
Generative models of code, pretrained on large corpora of programs, have shown great success in translating natural language to code (Chen et al., 2021; Austin et al., 2021; Li et al., 2022, inter alia). While these models do not explicitly incorporate program semantics (i.e., execution results) during training, they are able to generate correct solutions for many problems. However, choosing a single correct program from among a generated set for each problem remains challenging. In this work, we introduce execution result--based minimum Bayes risk decoding (MBR-EXEC) for program selection and show that it improves the few-shot performance of pretrained code models on natural-language-to-code tasks. We select output programs from a generated candidate set by marginalizing over program implementations that share the same semantics. Because exact equivalence is intractable, we execute each program on a small number of test inputs to approximate semantic equivalence. Across datasets, execution or simulated execution significantly outperforms the methods that do not involve program semantics. We find that MBR-EXEC consistently improves over all execution-unaware selection methods, suggesting it as an effective approach for natural language to code translation.
UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
Jan 20, 2022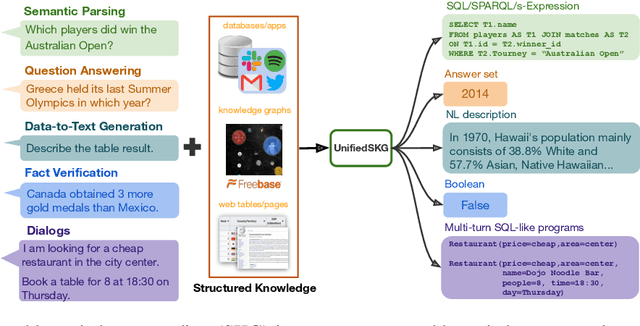
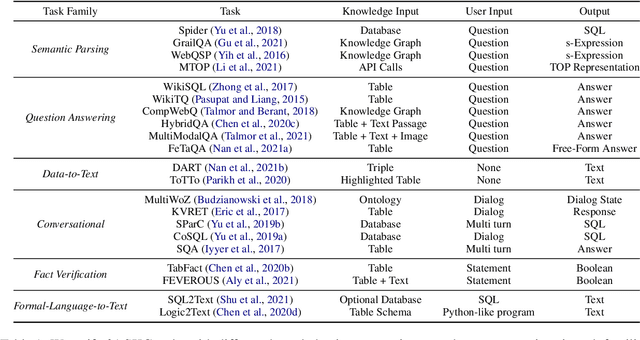
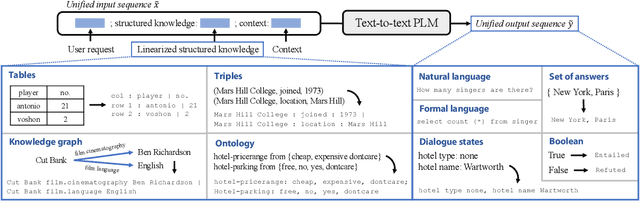
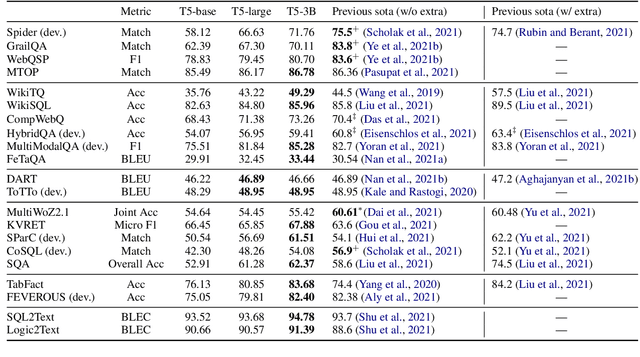
Structured knowledge grounding (SKG) leverages structured knowledge to complete user requests, such as semantic parsing over databases and question answering over knowledge bases. Since the inputs and outputs of SKG tasks are heterogeneous, they have been studied separately by different communities, which limits systematic and compatible research on SKG. In this paper, we overcome this limitation by proposing the SKG framework, which unifies 21 SKG tasks into a text-to-text format, aiming to promote systematic SKG research, instead of being exclusive to a single task, domain, or dataset. We use UnifiedSKG to benchmark T5 with different sizes and show that T5, with simple modifications when necessary, achieves state-of-the-art performance on almost all of the 21 tasks. We further demonstrate that multi-task prefix-tuning improves the performance on most tasks, largely improving the overall performance. UnifiedSKG also facilitates the investigation of zero-shot and few-shot learning, and we show that T0, GPT-3, and Codex struggle in zero-shot and few-shot learning for SKG. We also use UnifiedSKG to conduct a series of controlled experiments on structured knowledge encoding variants across SKG tasks. UnifiedSKG is easily extensible to more tasks, and it is open-sourced at https://github.com/hkunlp/unifiedskg Latest collections at https://unifiedskg.com.
BitextEdit: Automatic Bitext Editing for Improved Low-Resource Machine Translation
Nov 12, 2021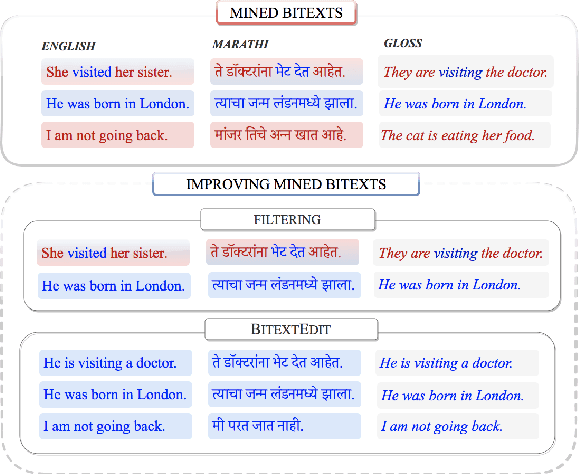
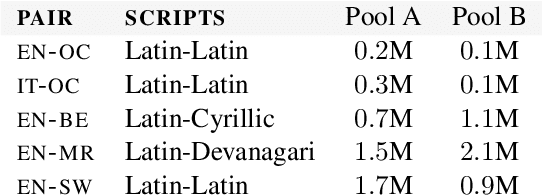
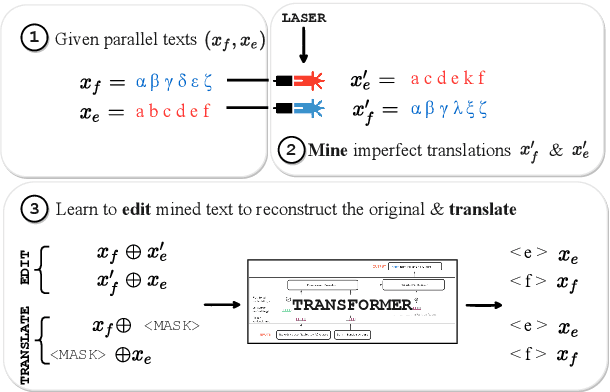
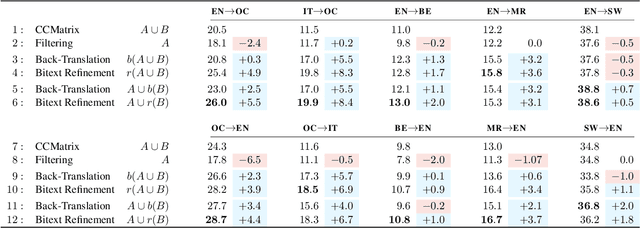
Mined bitexts can contain imperfect translations that yield unreliable training signals for Neural Machine Translation (NMT). While filtering such pairs out is known to improve final model quality, we argue that it is suboptimal in low-resource conditions where even mined data can be limited. In our work, we propose instead, to refine the mined bitexts via automatic editing: given a sentence in a language xf, and a possibly imperfect translation of it xe, our model generates a revised version xf' or xe' that yields a more equivalent translation pair (i.e., <xf, xe'> or <xf', xe>). We use a simple editing strategy by (1) mining potentially imperfect translations for each sentence in a given bitext, (2) learning a model to reconstruct the original translations and translate, in a multi-task fashion. Experiments demonstrate that our approach successfully improves the quality of CCMatrix mined bitext for 5 low-resource language-pairs and 10 translation directions by up to ~ 8 BLEU points, in most cases improving upon a competitive back-translation baseline.