 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Transform the Code, Code the Transforms: Towards Precise Code Rewriting using LLMs
Oct 11, 2024
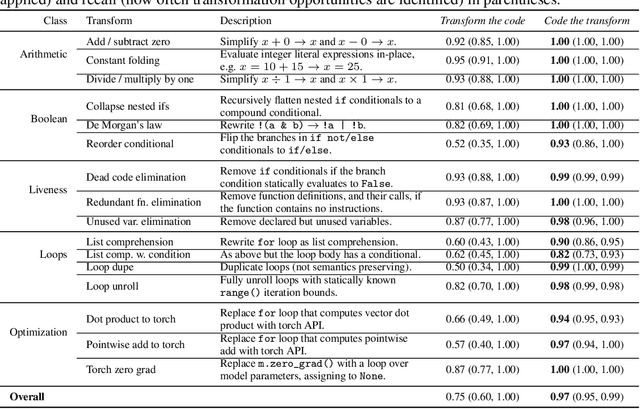

Tools for rewriting, refactoring and optimizing code should be fast and correct. Large language models (LLMs), by their nature, possess neither of these qualities. Yet, there remains tremendous opportunity in using LLMs to improve code. We explore the use of LLMs not to transform code, but to code transforms. We propose a chain-of-thought approach to synthesizing code transformations from a small number of input/output code examples that incorporates execution and feedback. Unlike the direct rewrite approach, LLM-generated transformations are easy to inspect, debug, and validate. The logic of the rewrite is explicitly coded and easy to adapt. The compute required to run code transformations is minute compared to that of LLM rewriting. We test our approach on 16 Python code transformations and find that LLM- generated transforms are perfectly precise for 7 of them and less imprecise than direct LLM rewriting on the others. We hope to encourage further research to improving the precision of LLM code rewriting.
Meta Large Language Model Compiler: Foundation Models of Compiler Optimization
Jun 27, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of software engineering and coding tasks. However, their application in the domain of code and compiler optimization remains underexplored. Training LLMs is resource-intensive, requiring substantial GPU hours and extensive data collection, which can be prohibitive. To address this gap, we introduce Meta Large Language Model Compiler (LLM Compiler), a suite of robust, openly available, pre-trained models specifically designed for code optimization tasks. Built on the foundation of Code Llama, LLM Compiler enhances the understanding of compiler intermediate representations (IRs), assembly language, and optimization techniques. The model has been trained on a vast corpus of 546 billion tokens of LLVM-IR and assembly code and has undergone instruction fine-tuning to interpret compiler behavior. LLM Compiler is released under a bespoke commercial license to allow wide reuse and is available in two sizes: 7 billion and 13 billion parameters. We also present fine-tuned versions of the model, demonstrating its enhanced capabilities in optimizing code size and disassembling from x86_64 and ARM assembly back into LLVM-IR. These achieve 77% of the optimising potential of an autotuning search, and 45% disassembly round trip (14% exact match). This release aims to provide a scalable, cost-effective foundation for further research and development in compiler optimization by both academic researchers and industry practitioners.
LOOPer: A Learned Automatic Code Optimizer For Polyhedral Compilers
Mar 22, 2024



While polyhedral compilers have shown success in implementing advanced code transformations, they still have challenges in selecting the most profitable transformations that lead to the best speedups. This has motivated the use of machine learning to build cost models to guide the search for polyhedral optimizations. State-of-the-art polyhedral compilers have demonstrated a viable proof-of-concept of this approach. While such a proof-of-concept has shown promise, it still has significant limitations. State-of-the-art polyhedral compilers that use a deep-learning cost model only support a small subset of affine transformations, limiting their ability to apply complex code transformations. They also only support simple programs that have a single loop nest and a rectangular iteration domain, limiting their applicability to many programs. These limitations significantly impact the generality of such compilers and autoschedulers and put into question the whole approach. In this paper, we introduce LOOPer, the first polyhedral autoscheduler that uses a deep-learning based cost model and covers a large set of affine transformations and programs. It supports the exploration of a large set of affine transformations, allowing the application of complex sequences of polyhedral transformations. It also supports the optimization of programs with multiple loop nests and with rectangular and non-rectangular iteration domains, allowing the optimization of an extensive set of programs. We implement and evaluate LOOPer and show that it achieves speedups over the state-of-the-art. On the Polybench benchmark, LOOPer achieves a geometric mean speedup of 1.59x over Tiramisu. LOOPer also achieves competitive speedups with a geometric mean speedup of 1.34x over Pluto, a state-of-the-art polyhedral compiler that does not use a machine-learning based cost model.
Compiler generated feedback for Large Language Models
Mar 18, 2024

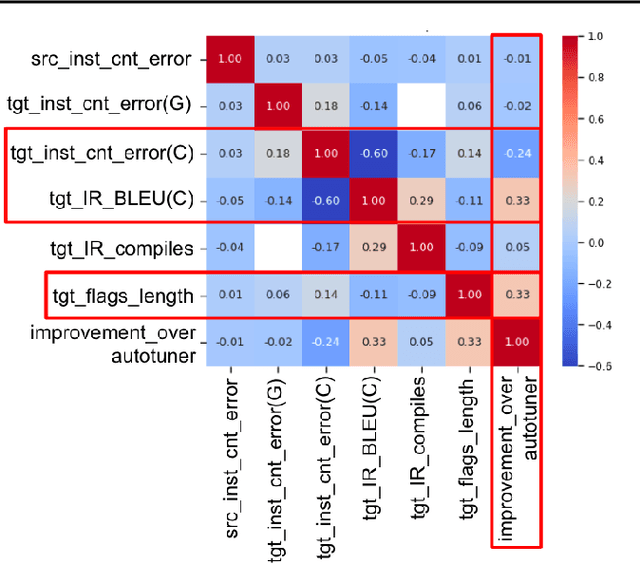
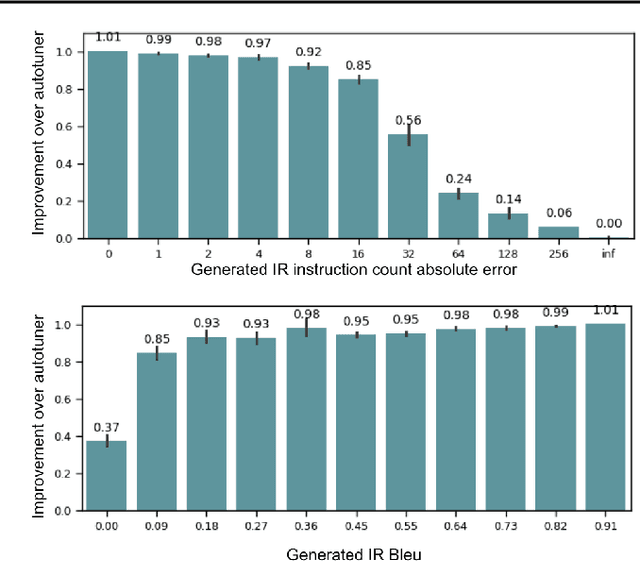
We introduce a novel paradigm in compiler optimization powered by Large Language Models with compiler feedback to optimize the code size of LLVM assembly. The model takes unoptimized LLVM IR as input and produces optimized IR, the best optimization passes, and instruction counts of both unoptimized and optimized IRs. Then we compile the input with generated optimization passes and evaluate if the predicted instruction count is correct, generated IR is compilable, and corresponds to compiled code. We provide this feedback back to LLM and give it another chance to optimize code. This approach adds an extra 0.53% improvement over -Oz to the original model. Even though, adding more information with feedback seems intuitive, simple sampling techniques achieve much higher performance given 10 or more samples.
Priority Sampling of Large Language Models for Compilers
Feb 28, 2024Large language models show great potential in generating and optimizing code. Widely used sampling methods such as Nucleus Sampling increase the diversity of generation but often produce repeated samples for low temperatures and incoherent samples for high temperatures. Furthermore, the temperature coefficient has to be tuned for each task, limiting its usability. We present Priority Sampling, a simple and deterministic sampling technique that produces unique samples ordered by the model's confidence. Each new sample expands the unexpanded token with the highest probability in the augmented search tree. Additionally, Priority Sampling supports generation based on regular expression that provides a controllable and structured exploration process. Priority Sampling outperforms Nucleus Sampling for any number of samples, boosting the performance of the original model from 2.87% to 5% improvement over -Oz. Moreover, it outperforms the autotuner used for the generation of labels for the training of the original model in just 30 samples.
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Jan 05, 2024We present CRUXEval (Code Reasoning, Understanding, and eXecution Evaluation), a benchmark consisting of 800 Python functions (3-13 lines). Each function comes with an input-output pair, leading to two natural tasks: input prediction and output prediction. First, we propose a generic recipe for generating our execution benchmark which can be used to create future variation of the benchmark. Second, we evaluate twenty code models on our benchmark and discover that many recent high-scoring models on HumanEval do not show the same improvements on our benchmark. Third, we show that simple CoT and fine-tuning schemes can improve performance on our benchmark but remain far from solving it. The best setup, GPT-4 with chain of thought (CoT), achieves a pass@1 of 75% and 81% on input and output prediction, respectively. In contrast, Code Llama 34B achieves a pass@1 of 50% and 46% on input and output prediction, highlighting the gap between open and closed source models. As no model is close to acing CRUXEval, we provide examples of consistent GPT-4 failures on simple programs as a lens into its code reasoning capabilities and areas for improvement.
SIEVE: Multimodal Dataset Pruning Using Image Captioning Models
Oct 03, 2023
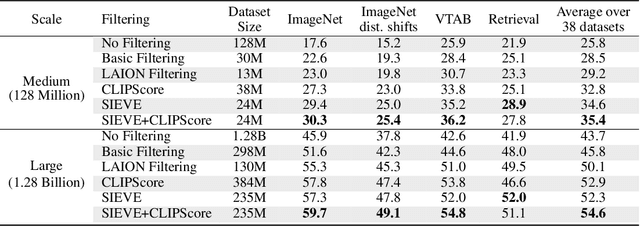
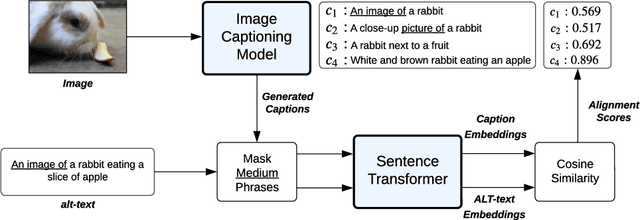
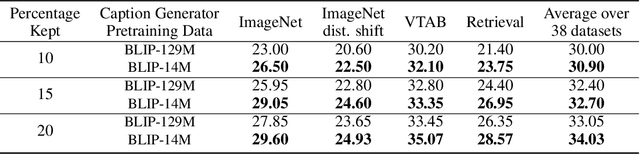
Vision-Language Models (VLMs) are pretrained on large, diverse, and noisy web-crawled datasets. This underscores the critical need for dataset pruning, as the quality of these datasets is strongly correlated with the performance of VLMs on downstream tasks. Using CLIPScore from a pretrained model to only train models using highly-aligned samples is one of the most successful methods for pruning.We argue that this approach suffers from multiple limitations including: 1) false positives due to spurious correlations captured by the pretrained CLIP model, 2) false negatives due to poor discrimination between hard and bad samples, and 3) biased ranking towards samples similar to the pretrained CLIP dataset. We propose a pruning method, SIEVE, that employs synthetic captions generated by image-captioning models pretrained on small, diverse, and well-aligned image-text pairs to evaluate the alignment of noisy image-text pairs. To bridge the gap between the limited diversity of generated captions and the high diversity of alternative text (alt-text), we estimate the semantic textual similarity in the embedding space of a language model pretrained on billions of sentences. Using DataComp, a multimodal dataset filtering benchmark, we achieve state-of-the-art performance on the large scale pool, and competitive results on the medium scale pool, surpassing CLIPScore-based filtering by 1.7% and 2.6% on average, on 38 downstream tasks.
Large Language Models for Compiler Optimization
Sep 11, 2023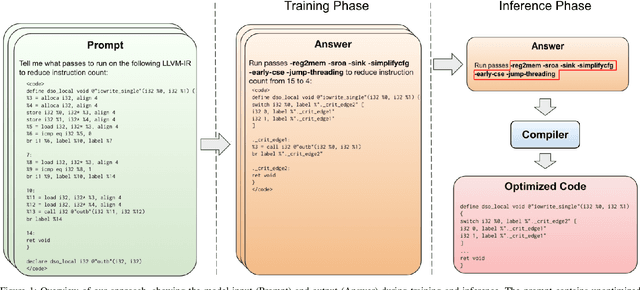
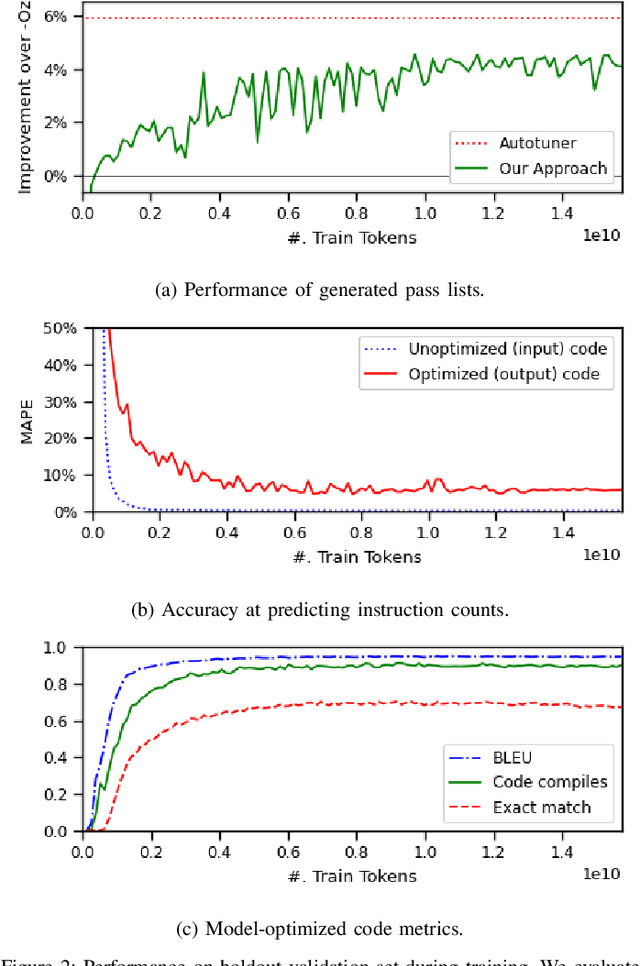
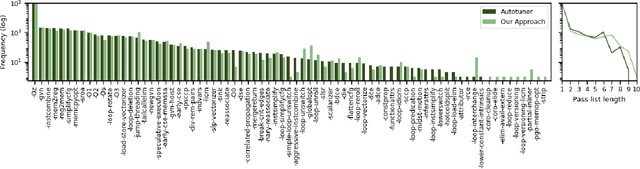
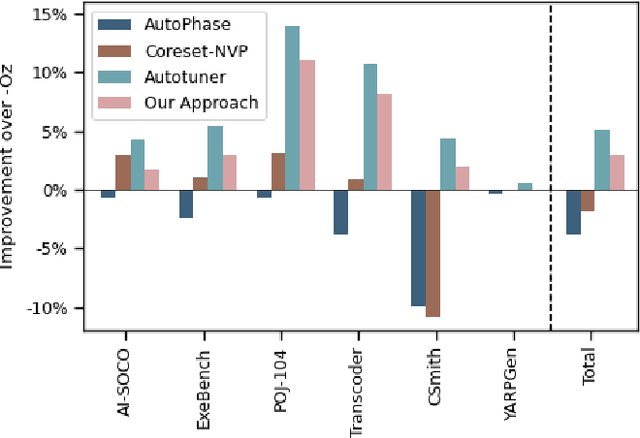
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
BenchDirect: A Directed Language Model for Compiler Benchmarks
Mar 02, 2023The exponential increase of hardware-software complexity has made it impossible for compiler engineers to find the right optimization heuristics manually. Predictive models have been shown to find near optimal heuristics with little human effort but they are limited by a severe lack of diverse benchmarks to train on. Generative AI has been used by researchers to synthesize benchmarks into existing datasets. However, the synthetic programs are short, exceedingly simple and lacking diversity in their features. We develop BenchPress, the first ML compiler benchmark generator that can be directed within source code feature representations. BenchPress synthesizes executable functions by infilling code that conditions on the program's left and right context. BenchPress uses active learning to introduce new benchmarks with unseen features into the dataset of Grewe's et al. CPU vs GPU heuristic, improving its acquired performance by 50%. BenchPress targets features that has been impossible for other synthesizers to reach. In 3 feature spaces, we outperform human-written code from GitHub, CLgen, CLSmith and the SRCIROR mutator in targeting the features of Rodinia benchmarks. BenchPress steers generation with beam search over a feature-agnostic language model. We improve this with BenchDirect which utilizes a directed LM that infills programs by jointly observing source code context and the compiler features that are targeted. BenchDirect achieves up to 36% better accuracy in targeting the features of Rodinia benchmarks, it is 1.8x more likely to give an exact match and it speeds up execution time by up to 72% compared to BenchPress. Both our models produce code that is difficult to distinguish from human-written code. We conduct a Turing test which shows our models' synthetic benchmarks are labelled as 'human-written' as often as human-written code from GitHub.
Learning to compile smartly for program size reduction
Jan 09, 2023Compiler optimization passes are an important tool for improving program efficiency and reducing program size, but manually selecting optimization passes can be time-consuming and error-prone. While human experts have identified a few fixed sequences of optimization passes (e.g., the Clang -Oz passes) that perform well for a wide variety of programs, these sequences are not conditioned on specific programs. In this paper, we propose a novel approach that learns a policy to select passes for program size reduction, allowing for customization and adaptation to specific programs. Our approach uses a search mechanism that helps identify useful pass sequences and a GNN with customized attention that selects the optimal sequence to use. Crucially it is able to generalize to new, unseen programs, making it more flexible and general than previous approaches. We evaluate our approach on a range of programs and show that it leads to size reduction compared to traditional optimization techniques. Our results demonstrate the potential of a single policy that is able to optimize many programs.