 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Transform the Code, Code the Transforms: Towards Precise Code Rewriting using LLMs
Oct 11, 2024
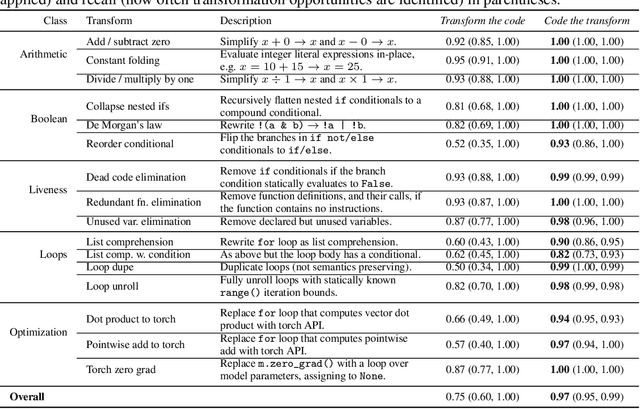

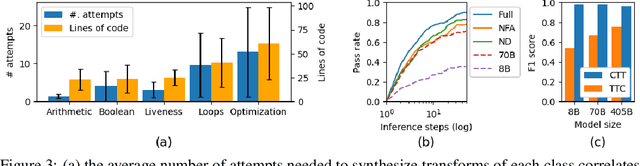
Tools for rewriting, refactoring and optimizing code should be fast and correct. Large language models (LLMs), by their nature, possess neither of these qualities. Yet, there remains tremendous opportunity in using LLMs to improve code. We explore the use of LLMs not to transform code, but to code transforms. We propose a chain-of-thought approach to synthesizing code transformations from a small number of input/output code examples that incorporates execution and feedback. Unlike the direct rewrite approach, LLM-generated transformations are easy to inspect, debug, and validate. The logic of the rewrite is explicitly coded and easy to adapt. The compute required to run code transformations is minute compared to that of LLM rewriting. We test our approach on 16 Python code transformations and find that LLM- generated transforms are perfectly precise for 7 of them and less imprecise than direct LLM rewriting on the others. We hope to encourage further research to improving the precision of LLM code rewriting.
Meta Large Language Model Compiler: Foundation Models of Compiler Optimization
Jun 27, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of software engineering and coding tasks. However, their application in the domain of code and compiler optimization remains underexplored. Training LLMs is resource-intensive, requiring substantial GPU hours and extensive data collection, which can be prohibitive. To address this gap, we introduce Meta Large Language Model Compiler (LLM Compiler), a suite of robust, openly available, pre-trained models specifically designed for code optimization tasks. Built on the foundation of Code Llama, LLM Compiler enhances the understanding of compiler intermediate representations (IRs), assembly language, and optimization techniques. The model has been trained on a vast corpus of 546 billion tokens of LLVM-IR and assembly code and has undergone instruction fine-tuning to interpret compiler behavior. LLM Compiler is released under a bespoke commercial license to allow wide reuse and is available in two sizes: 7 billion and 13 billion parameters. We also present fine-tuned versions of the model, demonstrating its enhanced capabilities in optimizing code size and disassembling from x86_64 and ARM assembly back into LLVM-IR. These achieve 77% of the optimising potential of an autotuning search, and 45% disassembly round trip (14% exact match). This release aims to provide a scalable, cost-effective foundation for further research and development in compiler optimization by both academic researchers and industry practitioners.
Compiler generated feedback for Large Language Models
Mar 18, 2024

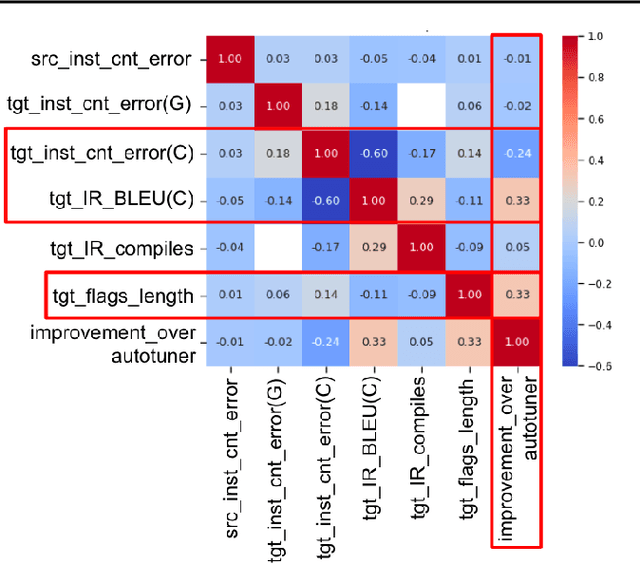
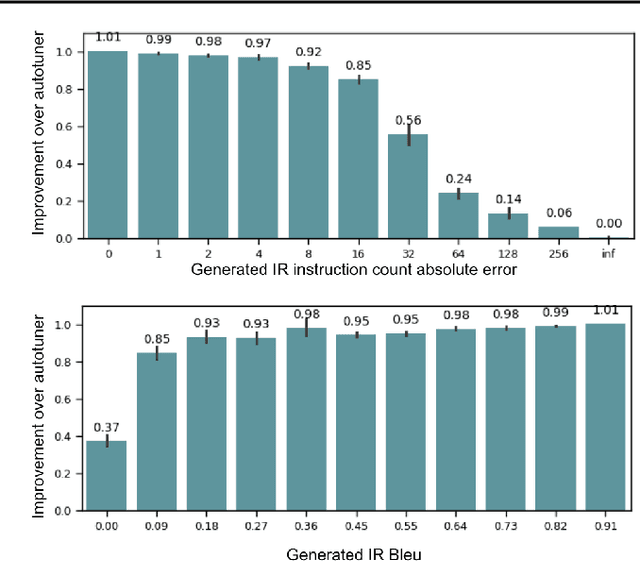
We introduce a novel paradigm in compiler optimization powered by Large Language Models with compiler feedback to optimize the code size of LLVM assembly. The model takes unoptimized LLVM IR as input and produces optimized IR, the best optimization passes, and instruction counts of both unoptimized and optimized IRs. Then we compile the input with generated optimization passes and evaluate if the predicted instruction count is correct, generated IR is compilable, and corresponds to compiled code. We provide this feedback back to LLM and give it another chance to optimize code. This approach adds an extra 0.53% improvement over -Oz to the original model. Even though, adding more information with feedback seems intuitive, simple sampling techniques achieve much higher performance given 10 or more samples.
Priority Sampling of Large Language Models for Compilers
Feb 28, 2024Large language models show great potential in generating and optimizing code. Widely used sampling methods such as Nucleus Sampling increase the diversity of generation but often produce repeated samples for low temperatures and incoherent samples for high temperatures. Furthermore, the temperature coefficient has to be tuned for each task, limiting its usability. We present Priority Sampling, a simple and deterministic sampling technique that produces unique samples ordered by the model's confidence. Each new sample expands the unexpanded token with the highest probability in the augmented search tree. Additionally, Priority Sampling supports generation based on regular expression that provides a controllable and structured exploration process. Priority Sampling outperforms Nucleus Sampling for any number of samples, boosting the performance of the original model from 2.87% to 5% improvement over -Oz. Moreover, it outperforms the autotuner used for the generation of labels for the training of the original model in just 30 samples.
Large Language Models for Compiler Optimization
Sep 11, 2023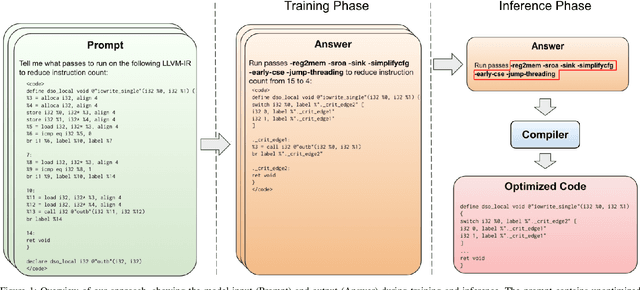
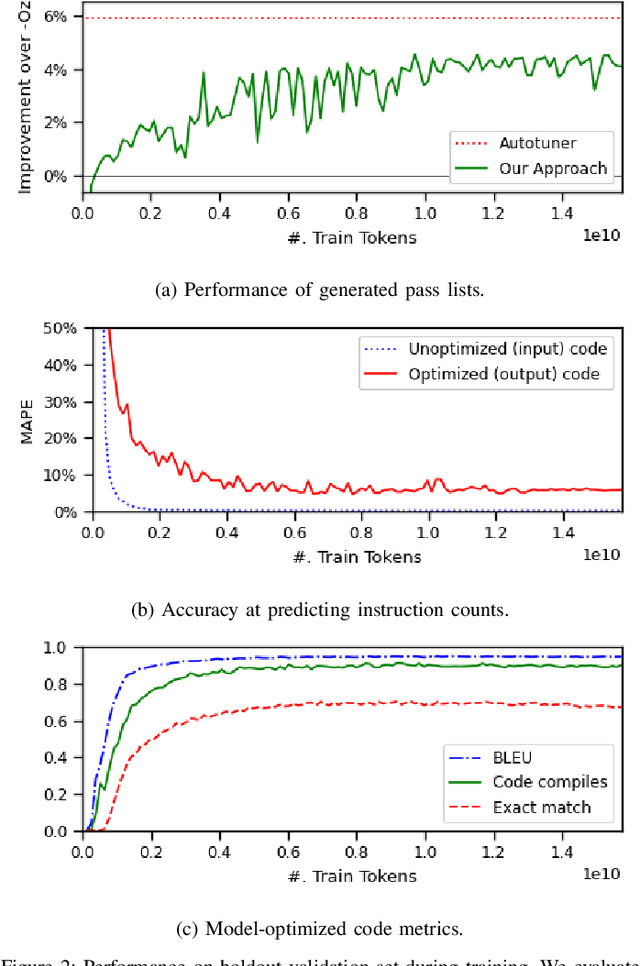
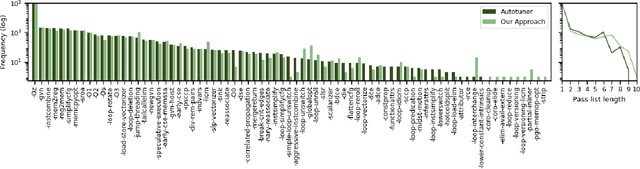
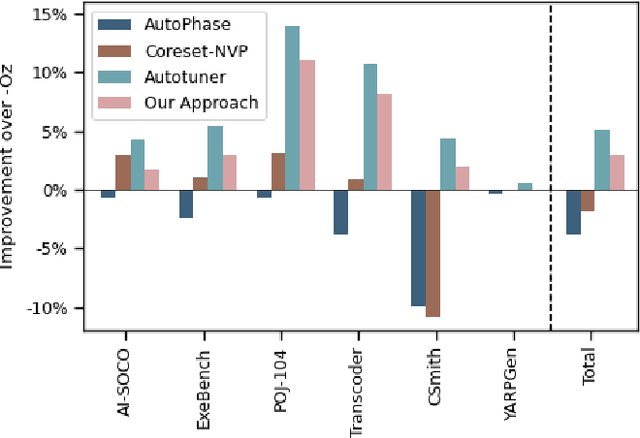
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.