 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigO(Bench) -- Can LLMs Generate Code with Controlled Time and Space Complexity?
Mar 20, 2025We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. This benchmark addresses the gap in current evaluations that often overlook the ability of models to comprehend and produce code constrained by computational complexity. BigO(Bench) includes tooling to infer the algorithmic complexity of any Python function from profiling measurements, including human- or LLM-generated solutions. BigO(Bench) also includes of set of 3,105 coding problems and 1,190,250 solutions from Code Contests annotated with inferred (synthetic) time and space complexity labels from the complexity framework, as well as corresponding runtime and memory footprint values for a large set of input sizes. We present results from evaluating multiple state-of-the-art language models on this benchmark, highlighting their strengths and weaknesses in handling complexity requirements. In particular, token-space reasoning models are unrivaled in code generation but not in complexity understanding, hinting that they may not generalize well to tasks for which no reward was given at training time.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Meta Large Language Model Compiler: Foundation Models of Compiler Optimization
Jun 27, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of software engineering and coding tasks. However, their application in the domain of code and compiler optimization remains underexplored. Training LLMs is resource-intensive, requiring substantial GPU hours and extensive data collection, which can be prohibitive. To address this gap, we introduce Meta Large Language Model Compiler (LLM Compiler), a suite of robust, openly available, pre-trained models specifically designed for code optimization tasks. Built on the foundation of Code Llama, LLM Compiler enhances the understanding of compiler intermediate representations (IRs), assembly language, and optimization techniques. The model has been trained on a vast corpus of 546 billion tokens of LLVM-IR and assembly code and has undergone instruction fine-tuning to interpret compiler behavior. LLM Compiler is released under a bespoke commercial license to allow wide reuse and is available in two sizes: 7 billion and 13 billion parameters. We also present fine-tuned versions of the model, demonstrating its enhanced capabilities in optimizing code size and disassembling from x86_64 and ARM assembly back into LLVM-IR. These achieve 77% of the optimising potential of an autotuning search, and 45% disassembly round trip (14% exact match). This release aims to provide a scalable, cost-effective foundation for further research and development in compiler optimization by both academic researchers and industry practitioners.
Large Language Models for Compiler Optimization
Sep 11, 2023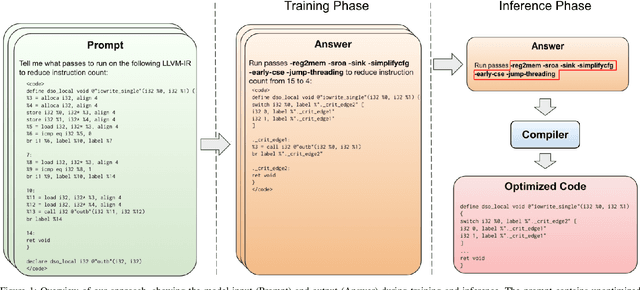
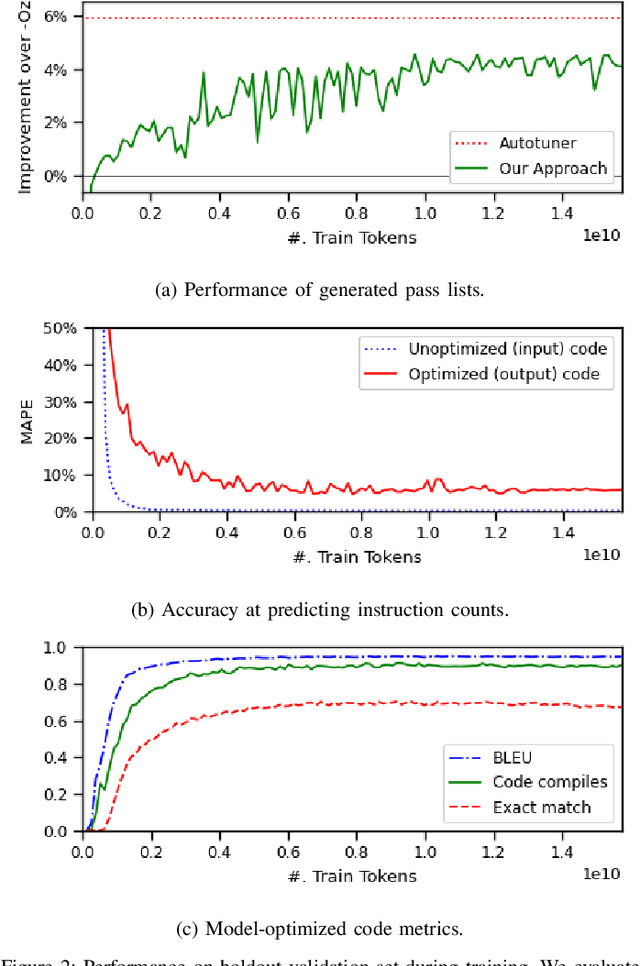
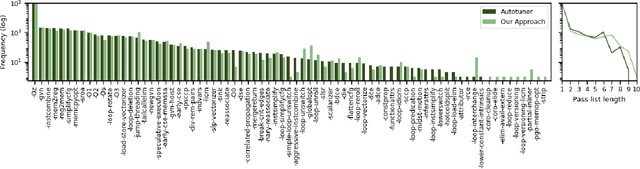
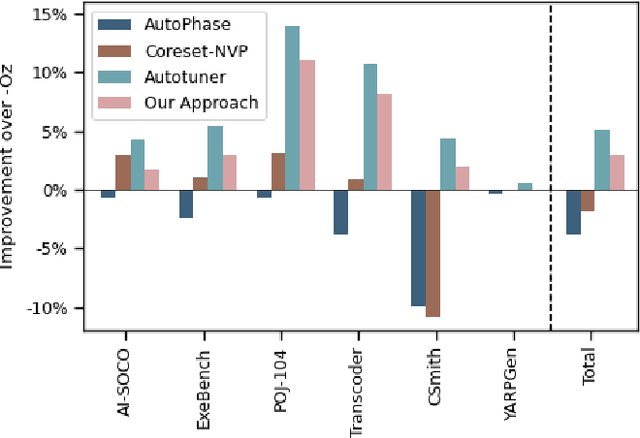
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
Code Translation with Compiler Representations
Jul 13, 2022
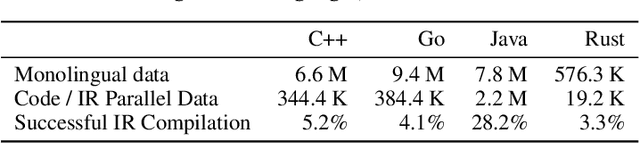
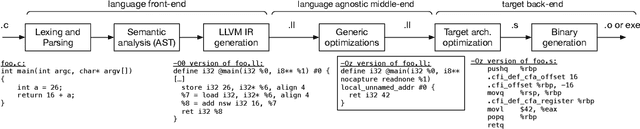

In this paper, we leverage low-level compiler intermediate representations (IR) to improve code translation. Traditional transpilers rely on syntactic information and handcrafted rules, which limits their applicability and produces unnatural-looking code. Applying neural machine translation (NMT) approaches to code has successfully broadened the set of programs on which one can get a natural-looking translation. However, they treat the code as sequences of text tokens, and still do not differentiate well enough between similar pieces of code which have different semantics in different languages. The consequence is low quality translation, reducing the practicality of NMT, and stressing the need for an approach significantly increasing its accuracy. Here we propose to augment code translation with IRs, specifically LLVM IR, with results on the C++, Java, Rust, and Go languages. Our method improves upon the state of the art for unsupervised code translation, increasing the number of correct translations by 11% on average, and up to 79% for the Java - Rust pair. We extend previous test sets for code translation, by adding hundreds of Go and Rust functions. Additionally, we train models with high performance on the problem of IR decompilation, generating programming source code from IR, and study using IRs as intermediary pivot for translation.
Leveraging Automated Unit Tests for Unsupervised Code Translation
Oct 13, 2021
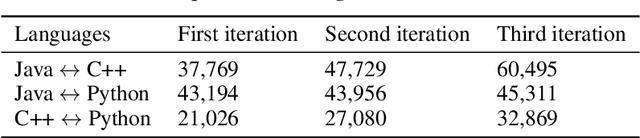
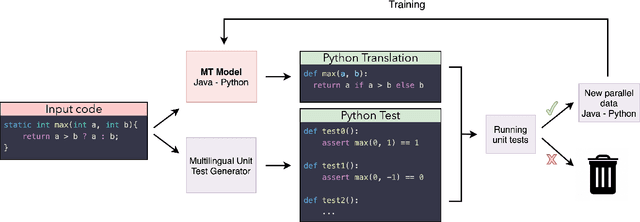
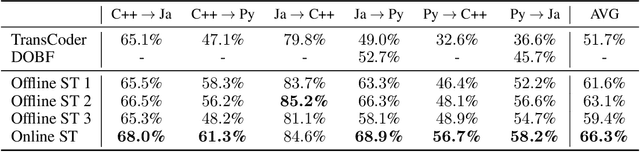
With little to no parallel data available for programming languages, unsupervised methods are well-suited to source code translation. However, the majority of unsupervised machine translation approaches rely on back-translation, a method developed in the context of natural language translation and one that inherently involves training on noisy inputs. Unfortunately, source code is highly sensitive to small changes; a single token can result in compilation failures or erroneous programs, unlike natural languages where small inaccuracies may not change the meaning of a sentence. To address this issue, we propose to leverage an automated unit-testing system to filter out invalid translations, thereby creating a fully tested parallel corpus. We found that fine-tuning an unsupervised model with this filtered data set significantly reduces the noise in the translations so-generated, comfortably outperforming the state-of-the-art for all language pairs studied. In particular, for Java $\to$ Python and Python $\to$ C++ we outperform the best previous methods by more than 16% and 24% respectively, reducing the error rate by more than 35%.
DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
Feb 16, 2021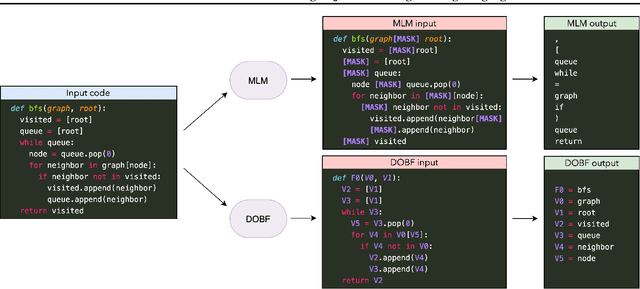


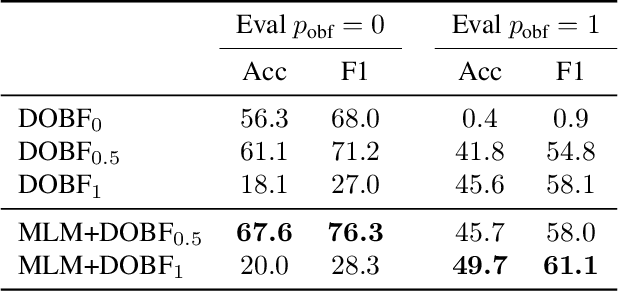
Recent advances in self-supervised learning have dramatically improved the state of the art on a wide variety of tasks. However, research in language model pre-training has mostly focused on natural languages, and it is unclear whether models like BERT and its variants provide the best pre-training when applied to other modalities, such as source code. In this paper, we introduce a new pre-training objective, DOBF, that leverages the structural aspect of programming languages and pre-trains a model to recover the original version of obfuscated source code. We show that models pre-trained with DOBF significantly outperform existing approaches on multiple downstream tasks, providing relative improvements of up to 13% in unsupervised code translation, and 24% in natural language code search. Incidentally, we found that our pre-trained model is able to de-obfuscate fully obfuscated source files, and to suggest descriptive variable names.
Black-Box Optimization Revisited: Improving Algorithm Selection Wizards through Massive Benchmarking
Oct 12, 2020


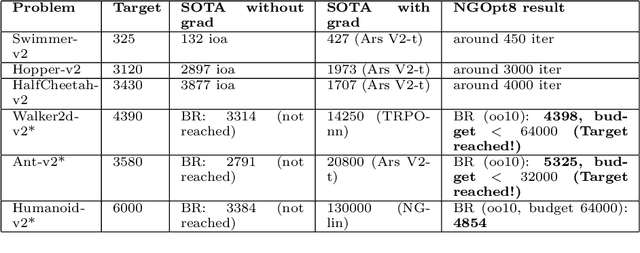
Existing studies in black-box optimization suffer from low generalizability, caused by a typically selective choice of problem instances used for training and testing different optimization algorithms. Among other issues, this practice promotes overfitting and poor-performing user guide-lines. To address this shortcoming, we propose in this work a benchmark suite which covers a broad range of black-box optimization problems, ranging from academic benchmarks to real-world optimization problems, from discrete over numerical to mixed-integer problems, from small to very large-scale problems, from noisy over dynamic to static problems, etc. We demonstrate the advantages of such a broad collection by deriving from it NGOpt8, a general-purpose algorithm selection wizard. Using three different types of algorithm selection techniques, NGOpt8 achieves competitive performance on all benchmark suites. It significantly outperforms previous state of the art on some of them, including the MuJoCo collection,YABBOB, and LSGO. A single algorithm therefore performed best on these three important benchmarks, without any task-specific parametrization. The benchmark collection, the wizard, its low-level solvers, as well as all experimental data are fully reproducible and open source. They are made available as a fork of Nevergrad, termed OptimSuite.
EvolGAN: Evolutionary Generative Adversarial Networks
Sep 28, 2020

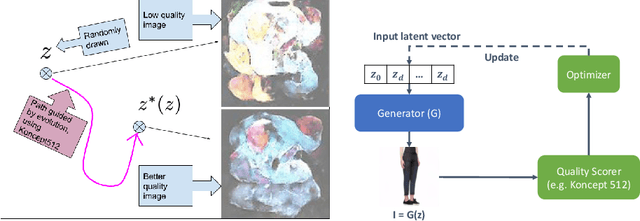
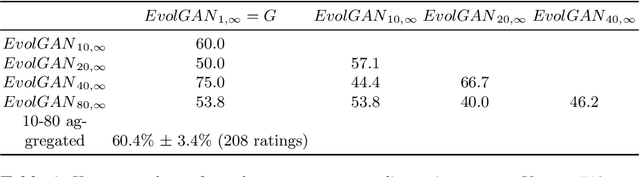
We propose to use a quality estimator and evolutionary methods to search the latent space of generative adversarial networks trained on small, difficult datasets, or both. The new method leads to the generation of significantly higher quality images while preserving the original generator's diversity. Human raters preferred an image from the new version with frequency 83.7pc for Cats, 74pc for FashionGen, 70.4pc for Horses, and 69.2pc for Artworks, and minor improvements for the already excellent GANs for faces. This approach applies to any quality scorer and GAN generator.
Tarsier: Evolving Noise Injection in Super-Resolution GANs
Sep 25, 2020

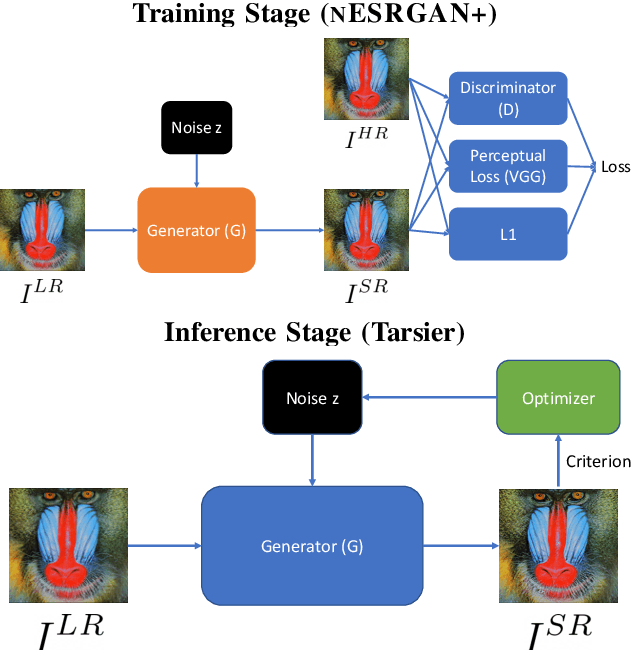
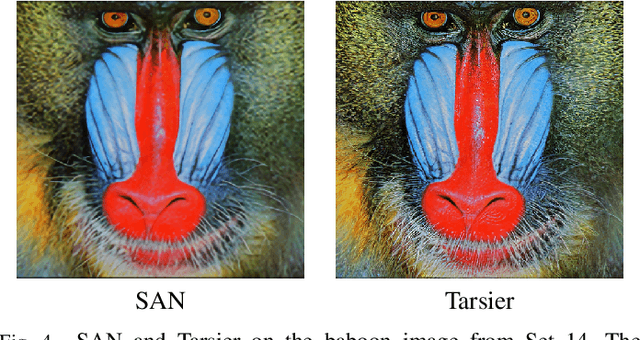
Super-resolution aims at increasing the resolution and level of detail within an image. The current state of the art in general single-image super-resolution is held by NESRGAN+, which injects a Gaussian noise after each residual layer at training time. In this paper, we harness evolutionary methods to improve NESRGAN+ by optimizing the noise injection at inference time. More precisely, we use Diagonal CMA to optimize the injected noise according to a novel criterion combining quality assessment and realism. Our results are validated by the PIRM perceptual score and a human study. Our method outperforms NESRGAN+ on several standard super-resolution datasets. More generally, our approach can be used to optimize any method based on noise injection.